 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond CAGE: Investigating Generalization of Learned Autonomous Network Defense Policies
Nov 30, 2022Advancements in reinforcement learning (RL) have inspired new directions in intelligent automation of network defense. However, many of these advancements have either outpaced their application to network security or have not considered the challenges associated with implementing them in the real-world. To understand these problems, this work evaluates several RL approaches implemented in the second edition of the CAGE Challenge, a public competition to build an autonomous network defender agent in a high-fidelity network simulator. Our approaches all build on the Proximal Policy Optimization (PPO) family of algorithms, and include hierarchical RL, action masking, custom training, and ensemble RL. We find that the ensemble RL technique performs strongest, outperforming our other models and taking second place in the competition. To understand applicability to real environments we evaluate each method's ability to generalize to unseen networks and against an unknown attack strategy. In unseen environments, all of our approaches perform worse, with degradation varied based on the type of environmental change. Against an unknown attacker strategy, we found that our models had reduced overall performance even though the new strategy was less efficient than the ones our models trained on. Together, these results highlight promising research directions for autonomous network defense in the real world.
Machine Learning Algorithms for Active Monitoring of High Performance Computing as a Service (HPCaaS) Cloud Environments
Sep 26, 2020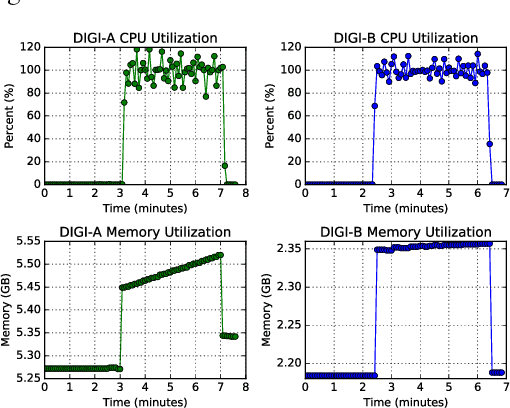
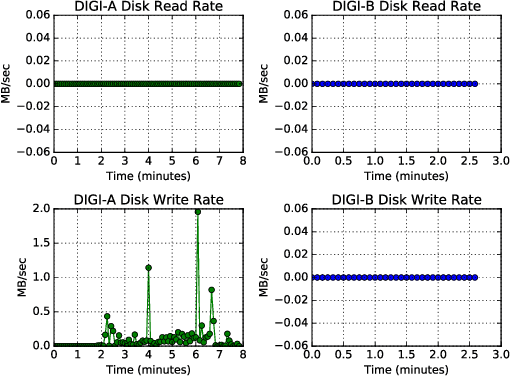
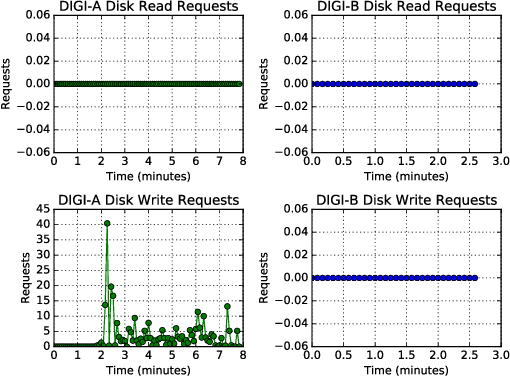
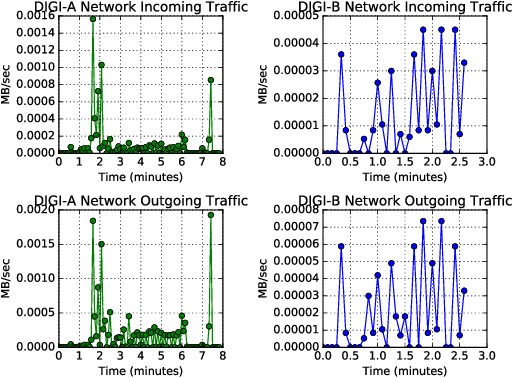
Cloud computing provides ubiquitous and on-demand access to vast reconfigurable resources that can meet any computational need. Many service models are available, but the Infrastructure as a Service (IaaS) model is particularly suited to operate as a high performance computing (HPC) platform, by networking large numbers of cloud computing nodes. We used the Pacific Northwest National Laboratory (PNNL) cloud computing environment to perform our experiments. A number of cloud computing providers such as Amazon Web Services, Microsoft Azure, or IBM Cloud, offer flexible and scalable computing resources. This paper explores the viability identifying types of engineering applications running on a cloud infrastructure configured as an HPC platform using privacy preserving features as input to statistical models. The engineering applications considered in this work include MCNP6, a radiation transport code developed by Los Alamos National Laboratory, OpenFOAM, an open source computational fluid dynamics code, and CADO-NFS, a numerical implementation of the general number field sieve algorithm used for prime number factorization. Our experiments use the OpenStack cloud management tool to create a cloud HPC environment and the privacy preserving Ceilometer billing meters as classification features to demonstrate identification of these applications.
Systematic Evaluation of Backdoor Data Poisoning Attacks on Image Classifiers
Apr 24, 2020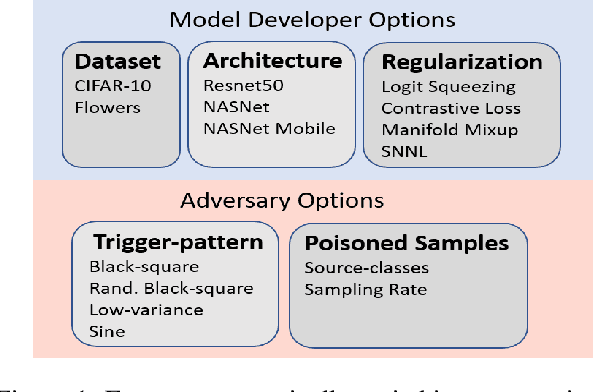
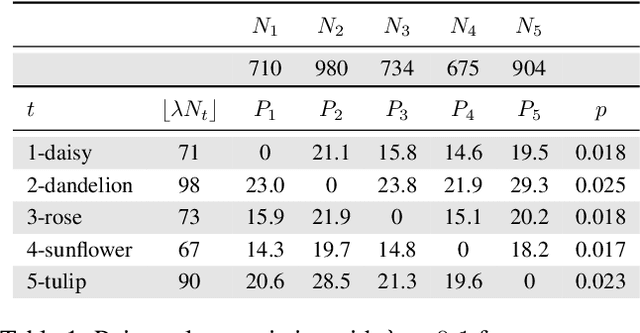


Backdoor data poisoning attacks have recently been demonstrated in computer vision research as a potential safety risk for machine learning (ML) systems. Traditional data poisoning attacks manipulate training data to induce unreliability of an ML model, whereas backdoor data poisoning attacks maintain system performance unless the ML model is presented with an input containing an embedded "trigger" that provides a predetermined response advantageous to the adversary. Our work builds upon prior backdoor data-poisoning research for ML image classifiers and systematically assesses different experimental conditions including types of trigger patterns, persistence of trigger patterns during retraining, poisoning strategies, architectures (ResNet-50, NasNet, NasNet-Mobile), datasets (Flowers, CIFAR-10), and potential defensive regularization techniques (Contrastive Loss, Logit Squeezing, Manifold Mixup, Soft-Nearest-Neighbors Loss). Experiments yield four key findings. First, the success rate of backdoor poisoning attacks varies widely, depending on several factors, including model architecture, trigger pattern and regularization technique. Second, we find that poisoned models are hard to detect through performance inspection alone. Third, regularization typically reduces backdoor success rate, although it can have no effect or even slightly increase it, depending on the form of regularization. Finally, backdoors inserted through data poisoning can be rendered ineffective after just a few epochs of additional training on a small set of clean data without affecting the model's performance.
Projecting Trouble: Light Based Adversarial Attacks on Deep Learning Classifiers
Oct 16, 2018



This work demonstrates a physical attack on a deep learning image classification system using projected light onto a physical scene. Prior work is dominated by techniques for creating adversarial examples which directly manipulate the digital input of the classifier. Such an attack is limited to scenarios where the adversary can directly update the inputs to the classifier. This could happen by intercepting and modifying the inputs to an online API such as Clarifai or Cloud Vision. Such limitations have led to a vein of research around physical attacks where objects are constructed to be inherently adversarial or adversarial modifications are added to cause misclassification. Our work differs from other physical attacks in that we can cause misclassification dynamically without altering physical objects in a permanent way. We construct an experimental setup which includes a light projection source, an object for classification, and a camera to capture the scene. Experiments are conducted against 2D and 3D objects from CIFAR-10. Initial tests show projected light patterns selected via differential evolution could degrade classification from 98% to 22% and 89% to 43% probability for 2D and 3D targets respectively. Subsequent experiments explore sensitivity to physical setup and compare two additional baseline conditions for all 10 CIFAR classes. Some physical targets are more susceptible to perturbation. Simple attacks show near equivalent success, and 6 of the 10 classes were disrupted by light.
Recurrent Neural Network Attention Mechanisms for Interpretable System Log Anomaly Detection
Mar 13, 2018



Deep learning has recently demonstrated state-of-the art performance on key tasks related to the maintenance of computer systems, such as intrusion detection, denial of service attack detection, hardware and software system failures, and malware detection. In these contexts, model interpretability is vital for administrator and analyst to trust and act on the automated analysis of machine learning models. Deep learning methods have been criticized as black box oracles which allow limited insight into decision factors. In this work we seek to "bridge the gap" between the impressive performance of deep learning models and the need for interpretable model introspection. To this end we present recurrent neural network (RNN) language models augmented with attention for anomaly detection in system logs. Our methods are generally applicable to any computer system and logging source. By incorporating attention variants into our RNN language models we create opportunities for model introspection and analysis without sacrificing state-of-the art performance. We demonstrate model performance and illustrate model interpretability on an intrusion detection task using the Los Alamos National Laboratory (LANL) cyber security dataset, reporting upward of 0.99 area under the receiver operator characteristic curve despite being trained only on a single day's worth of data.
Deep Learning for Unsupervised Insider Threat Detection in Structured Cybersecurity Data Streams
Dec 15, 2017



Analysis of an organization's computer network activity is a key component of early detection and mitigation of insider threat, a growing concern for many organizations. Raw system logs are a prototypical example of streaming data that can quickly scale beyond the cognitive power of a human analyst. As a prospective filter for the human analyst, we present an online unsupervised deep learning approach to detect anomalous network activity from system logs in real time. Our models decompose anomaly scores into the contributions of individual user behavior features for increased interpretability to aid analysts reviewing potential cases of insider threat. Using the CERT Insider Threat Dataset v6.2 and threat detection recall as our performance metric, our novel deep and recurrent neural network models outperform Principal Component Analysis, Support Vector Machine and Isolation Forest based anomaly detection baselines. For our best model, the events labeled as insider threat activity in our dataset had an average anomaly score in the 95.53 percentile, demonstrating our approach's potential to greatly reduce analyst workloads.
Recurrent Neural Network Language Models for Open Vocabulary Event-Level Cyber Anomaly Detection
Dec 02, 2017



Automated analysis methods are crucial aids for monitoring and defending a network to protect the sensitive or confidential data it hosts. This work introduces a flexible, powerful, and unsupervised approach to detecting anomalous behavior in computer and network logs, one that largely eliminates domain-dependent feature engineering employed by existing methods. By treating system logs as threads of interleaved "sentences" (event log lines) to train online unsupervised neural network language models, our approach provides an adaptive model of normal network behavior. We compare the effectiveness of both standard and bidirectional recurrent neural network language models at detecting malicious activity within network log data. Extending these models, we introduce a tiered recurrent architecture, which provides context by modeling sequences of users' actions over time. Compared to Isolation Forest and Principal Components Analysis, two popular anomaly detection algorithms, we observe superior performance on the Los Alamos National Laboratory Cyber Security dataset. For log-line-level red team detection, our best performing character-based model provides test set area under the receiver operator characteristic curve of 0.98, demonstrating the strong fine-grained anomaly detection performance of this approach on open vocabulary logging sources.
Faster Fuzzing: Reinitialization with Deep Neural Models
Nov 08, 2017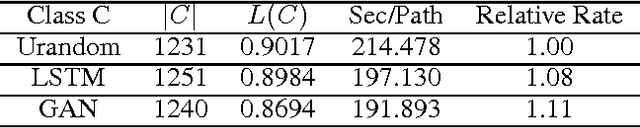


We improve the performance of the American Fuzzy Lop (AFL) fuzz testing framework by using Generative Adversarial Network (GAN) models to reinitialize the system with novel seed files. We assess performance based on the temporal rate at which we produce novel and unseen code paths. We compare this approach to seed file generation from a random draw of bytes observed in the training seed files. The code path lengths and variations were not sufficiently diverse to fully replace AFL input generation. However, augmenting native AFL with these additional code paths demonstrated improvements over AFL alone. Specifically, experiments showed the GAN was faster and more effective than the LSTM and out-performed a random augmentation strategy, as measured by the number of unique code paths discovered. GAN helps AFL discover 14.23% more code paths than the random strategy in the same amount of CPU time, finds 6.16% more unique code paths, and finds paths that are on average 13.84% longer. Using GAN shows promise as a reinitialization strategy for AFL to help the fuzzer exercise deep paths in software.