 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFiber Bundle Morphisms as a Framework for Modeling Many-to-Many Maps
Mar 15, 2022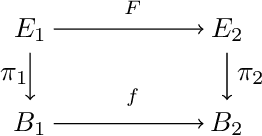


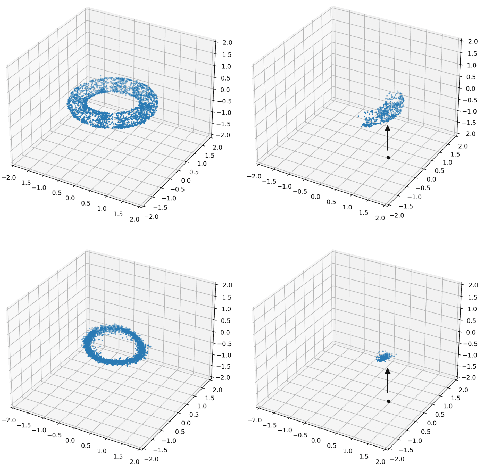
While it is not generally reflected in the `nice' datasets used for benchmarking machine learning algorithms, the real-world is full of processes that would be best described as many-to-many. That is, a single input can potentially yield many different outputs (whether due to noise, imperfect measurement, or intrinsic stochasticity in the process) and many different inputs can yield the same output (that is, the map is not injective). For example, imagine a sentiment analysis task where, due to linguistic ambiguity, a single statement can have a range of different sentiment interpretations while at the same time many distinct statements can represent the same sentiment. When modeling such a multivalued function $f: X \rightarrow Y$, it is frequently useful to be able to model the distribution on $f(x)$ for specific input $x$ as well as the distribution on fiber $f^{-1}(y)$ for specific output $y$. Such an analysis helps the user (i) better understand the variance intrinsic to the process they are studying and (ii) understand the range of specific input $x$ that can be used to achieve output $y$. Following existing work which used a fiber bundle framework to better model many-to-one processes, we describe how morphisms of fiber bundles provide a template for building models which naturally capture the structure of many-to-many processes.
Differential Property Prediction: A Machine Learning Approach to Experimental Design in Advanced Manufacturing
Dec 03, 2021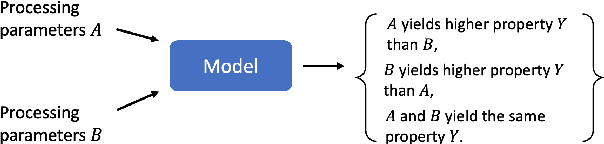



Advanced manufacturing techniques have enabled the production of materials with state-of-the-art properties. In many cases however, the development of physics-based models of these techniques lags behind their use in the lab. This means that designing and running experiments proceeds largely via trial and error. This is sub-optimal since experiments are cost-, time-, and labor-intensive. In this work we propose a machine learning framework, differential property classification (DPC), which enables an experimenter to leverage machine learning's unparalleled pattern matching capability to pursue data-driven experimental design. DPC takes two possible experiment parameter sets and outputs a prediction of which will produce a material with a more desirable property specified by the operator. We demonstrate the success of DPC on AA7075 tube manufacturing process and mechanical property data using shear assisted processing and extrusion (ShAPE), a solid phase processing technology. We show that by focusing on the experimenter's need to choose between multiple candidate experimental parameters, we can reframe the challenging regression task of predicting material properties from processing parameters, into a classification task on which machine learning models can achieve good performance.
CooGAN: A Memory-Efficient Framework for High-Resolution Facial Attribute Editing
Nov 03, 2020



In contrast to great success of memory-consuming face editing methods at a low resolution, to manipulate high-resolution (HR) facial images, i.e., typically larger than 7682 pixels, with very limited memory is still challenging. This is due to the reasons of 1) intractable huge demand of memory; 2) inefficient multi-scale features fusion. To address these issues, we propose a NOVEL pixel translation framework called Cooperative GAN(CooGAN) for HR facial image editing. This framework features a local path for fine-grained local facial patch generation (i.e., patch-level HR, LOW memory) and a global path for global lowresolution (LR) facial structure monitoring (i.e., image-level LR, LOW memory), which largely reduce memory requirements. Both paths work in a cooperative manner under a local-to-global consistency objective (i.e., for smooth stitching). In addition, we propose a lighter selective transfer unit for more efficient multi-scale features fusion, yielding higher fidelity facial attributes manipulation. Extensive experiments on CelebAHQ well demonstrate the memory efficiency as well as the high image generation quality of the proposed framework.
Systematic Evaluation of Backdoor Data Poisoning Attacks on Image Classifiers
Apr 24, 2020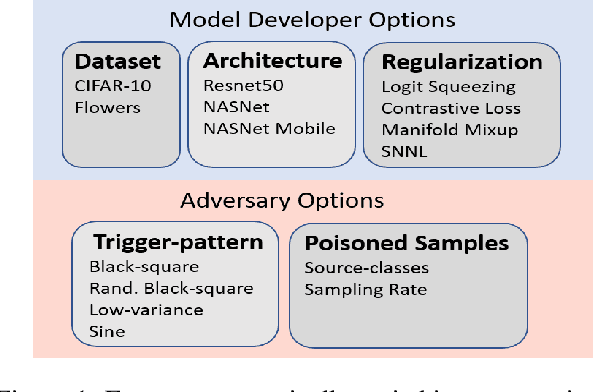
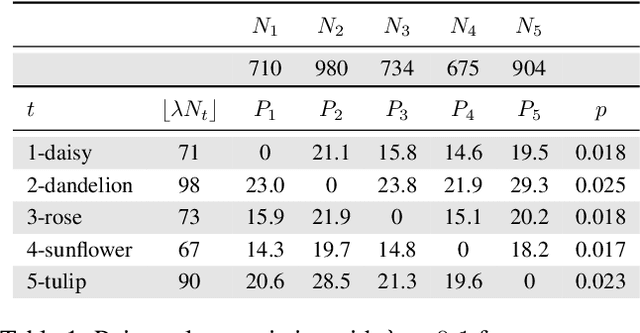


Backdoor data poisoning attacks have recently been demonstrated in computer vision research as a potential safety risk for machine learning (ML) systems. Traditional data poisoning attacks manipulate training data to induce unreliability of an ML model, whereas backdoor data poisoning attacks maintain system performance unless the ML model is presented with an input containing an embedded "trigger" that provides a predetermined response advantageous to the adversary. Our work builds upon prior backdoor data-poisoning research for ML image classifiers and systematically assesses different experimental conditions including types of trigger patterns, persistence of trigger patterns during retraining, poisoning strategies, architectures (ResNet-50, NasNet, NasNet-Mobile), datasets (Flowers, CIFAR-10), and potential defensive regularization techniques (Contrastive Loss, Logit Squeezing, Manifold Mixup, Soft-Nearest-Neighbors Loss). Experiments yield four key findings. First, the success rate of backdoor poisoning attacks varies widely, depending on several factors, including model architecture, trigger pattern and regularization technique. Second, we find that poisoned models are hard to detect through performance inspection alone. Third, regularization typically reduces backdoor success rate, although it can have no effect or even slightly increase it, depending on the form of regularization. Finally, backdoors inserted through data poisoning can be rendered ineffective after just a few epochs of additional training on a small set of clean data without affecting the model's performance.