 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReLER@ZJU-Alibaba Submission to the Ego4D Natural Language Queries Challenge 2022
Jul 01, 2022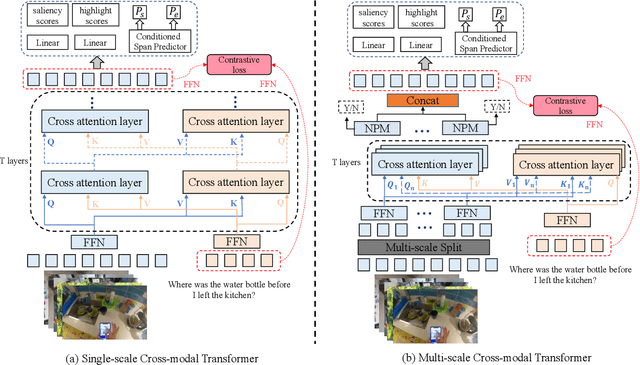



In this report, we present the ReLER@ZJU-Alibaba submission to the Ego4D Natural Language Queries (NLQ) Challenge in CVPR 2022. Given a video clip and a text query, the goal of this challenge is to locate a temporal moment of the video clip where the answer to the query can be obtained. To tackle this task, we propose a multi-scale cross-modal transformer and a video frame-level contrastive loss to fully uncover the correlation between language queries and video clips. Besides, we propose two data augmentation strategies to increase the diversity of training samples. The experimental results demonstrate the effectiveness of our method. The final submission ranked first on the leaderboard.
Image Translation via Fine-grained Knowledge Transfer
Dec 21, 2020



Prevailing image-translation frameworks mostly seek to process images via the end-to-end style, which has achieved convincing results. Nonetheless, these methods lack interpretability and are not scalable on different image-translation tasks (e.g., style transfer, HDR, etc.). In this paper, we propose an interpretable knowledge-based image-translation framework, which realizes the image-translation through knowledge retrieval and transfer. In details, the framework constructs a plug-and-play and model-agnostic general purpose knowledge library, remembering task-specific styles, tones, texture patterns, etc. Furthermore, we present a fast ANN searching approach, Bandpass Hierarchical K-Means (BHKM), to cope with the difficulty of searching in the enormous knowledge library. Extensive experiments well demonstrate the effectiveness and feasibility of our framework in different image-translation tasks. In particular, backtracking experiments verify the interpretability of our method. Our code soon will be available at https://github.com/AceSix/Knowledge_Transfer.
RainNet: A Large-Scale Dataset for Spatial Precipitation Downscaling
Dec 18, 2020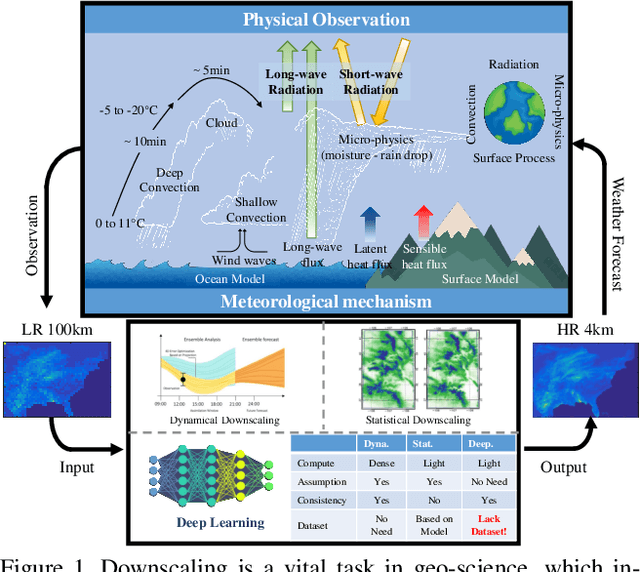
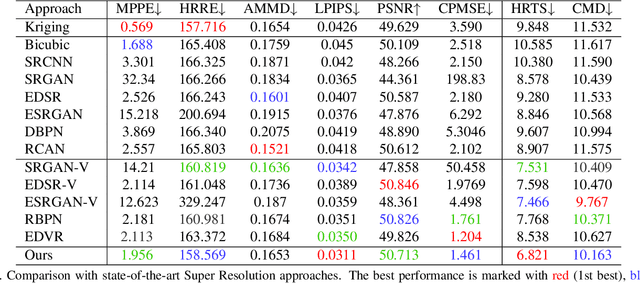
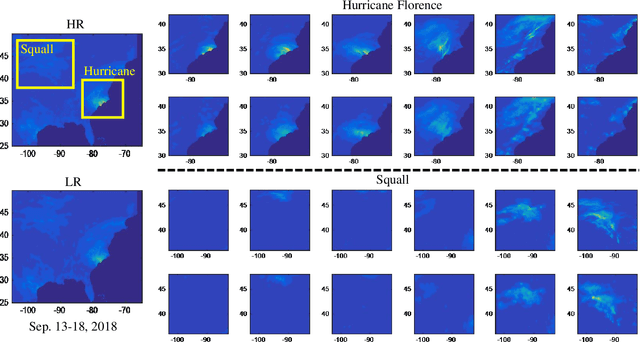
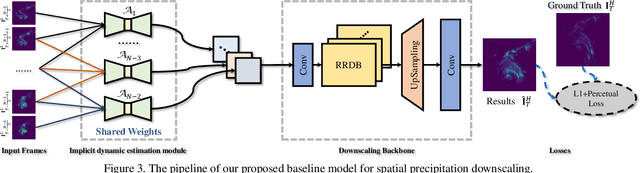
Spatial Precipitation Downscaling is one of the most important problems in the geo-science community. However, it still remains an unaddressed issue. Deep learning is a promising potential solution for downscaling. In order to facilitate the research on precipitation downscaling for deep learning, we present the first REAL (non-simulated) Large-Scale Spatial Precipitation Downscaling Dataset, RainNet, which contains 62,424 pairs of low-resolution and high-resolution precipitation maps for 17 years. Contrary to simulated data, this real dataset covers various types of real meteorological phenomena (e.g., Hurricane, Squall, etc.), and shows the physical characters - Temporal Misalignment, Temporal Sparse and Fluid Properties - that challenge the downscaling algorithms. In order to fully explore potential downscaling solutions, we propose an implicit physical estimation framework to learn the above characteristics. Eight metrics specifically considering the physical property of the data set are raised, while fourteen models are evaluated on the proposed dataset. Finally, we analyze the effectiveness and feasibility of these models on precipitation downscaling task. The Dataset and Code will be available at https://neuralchen.github.io/RainNet/.
CooGAN: A Memory-Efficient Framework for High-Resolution Facial Attribute Editing
Nov 03, 2020



In contrast to great success of memory-consuming face editing methods at a low resolution, to manipulate high-resolution (HR) facial images, i.e., typically larger than 7682 pixels, with very limited memory is still challenging. This is due to the reasons of 1) intractable huge demand of memory; 2) inefficient multi-scale features fusion. To address these issues, we propose a NOVEL pixel translation framework called Cooperative GAN(CooGAN) for HR facial image editing. This framework features a local path for fine-grained local facial patch generation (i.e., patch-level HR, LOW memory) and a global path for global lowresolution (LR) facial structure monitoring (i.e., image-level LR, LOW memory), which largely reduce memory requirements. Both paths work in a cooperative manner under a local-to-global consistency objective (i.e., for smooth stitching). In addition, we propose a lighter selective transfer unit for more efficient multi-scale features fusion, yielding higher fidelity facial attributes manipulation. Extensive experiments on CelebAHQ well demonstrate the memory efficiency as well as the high image generation quality of the proposed framework.
Anisotropic Stroke Control for Multiple Artists Style Transfer
Oct 16, 2020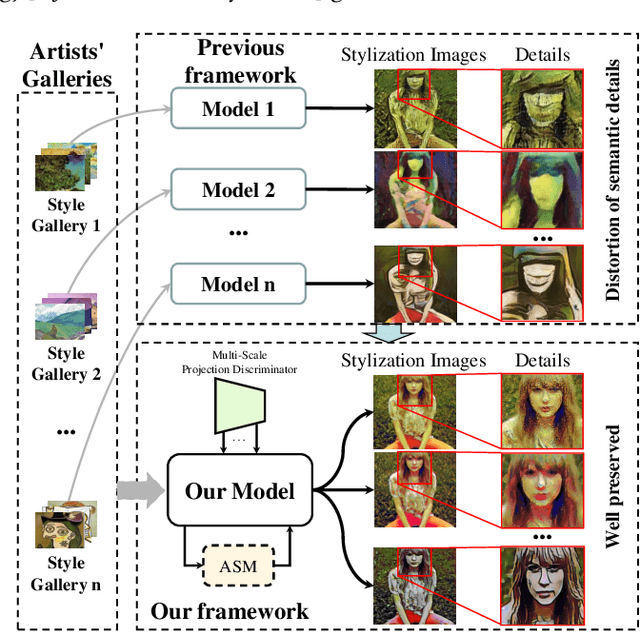
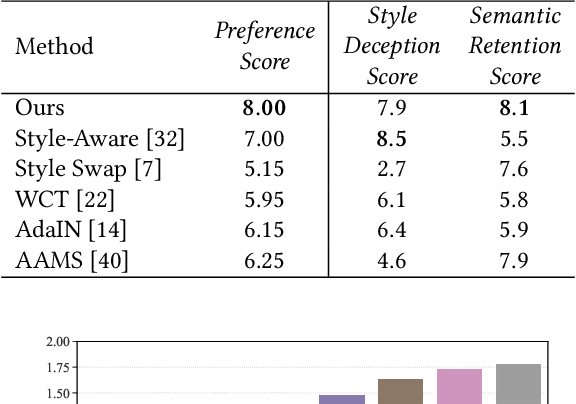

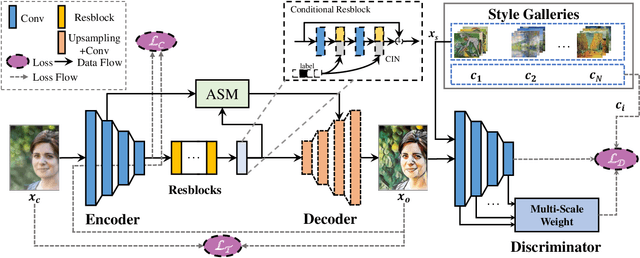
Though significant progress has been made in artistic style transfer, semantic information is usually difficult to be preserved in a fine-grained locally consistent manner by most existing methods, especially when multiple artists styles are required to transfer within one single model. To circumvent this issue, we propose a Stroke Control Multi-Artist Style Transfer framework. On the one hand, we develop a multi-condition single-generator structure which first performs multi-artist style transfer. On the one hand, we design an Anisotropic Stroke Module (ASM) which realizes the dynamic adjustment of style-stroke between the non-trivial and the trivial regions. ASM endows the network with the ability of adaptive semantic-consistency among various styles. On the other hand, we present an novel Multi-Scale Projection Discriminator} to realize the texture-level conditional generation. In contrast to the single-scale conditional discriminator, our discriminator is able to capture multi-scale texture clue to effectively distinguish a wide range of artistic styles. Extensive experimental results well demonstrate the feasibility and effectiveness of our approach. Our framework can transform a photograph into different artistic style oil painting via only ONE single model. Furthermore, the results are with distinctive artistic style and retain the anisotropic semantic information.