Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReLER@ZJU-Alibaba Submission to the Ego4D Natural Language Queries Challenge 2022
Paper and Code
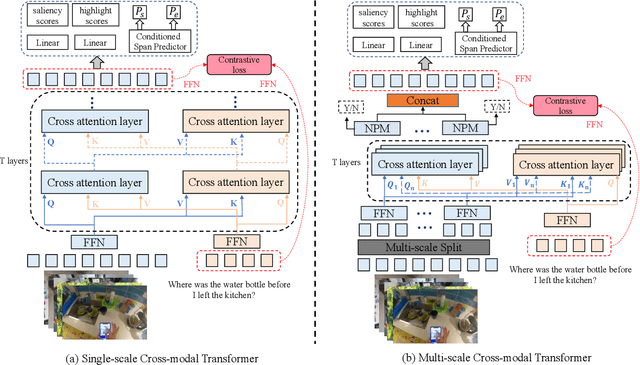



In this report, we present the ReLER@ZJU-Alibaba submission to the Ego4D Natural Language Queries (NLQ) Challenge in CVPR 2022. Given a video clip and a text query, the goal of this challenge is to locate a temporal moment of the video clip where the answer to the query can be obtained. To tackle this task, we propose a multi-scale cross-modal transformer and a video frame-level contrastive loss to fully uncover the correlation between language queries and video clips. Besides, we propose two data augmentation strategies to increase the diversity of training samples. The experimental results demonstrate the effectiveness of our method. The final submission ranked first on the leaderboard.
* 1st Place in Ego4D Natural Language Queries Challenge
View paper on