 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Structured Biological Knowledge for Counterfactual Inference: a Case Study of Viral Pathogenesis
Jan 13, 2021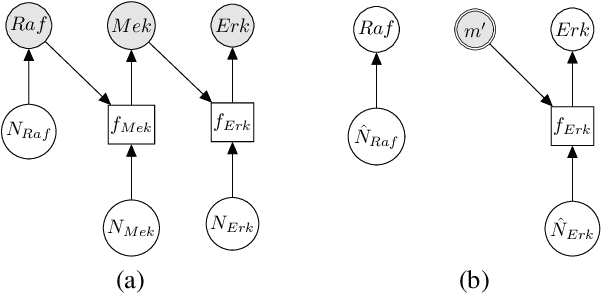
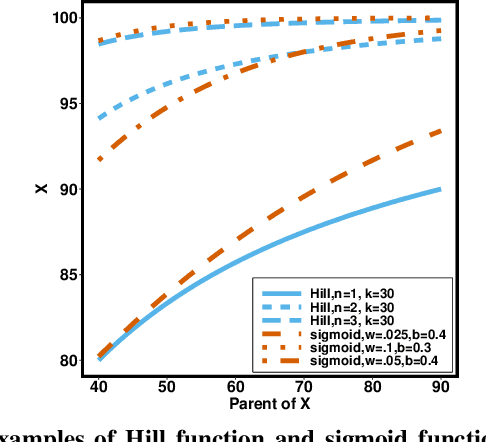

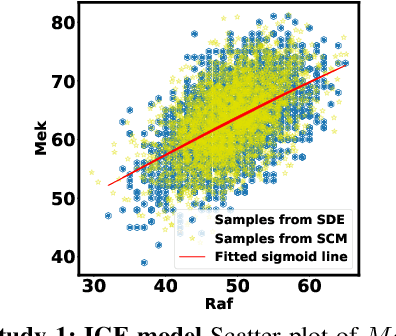
Counterfactual inference is a useful tool for comparing outcomes of interventions on complex systems. It requires us to represent the system in form of a structural causal model, complete with a causal diagram, probabilistic assumptions on exogenous variables, and functional assignments. Specifying such models can be extremely difficult in practice. The process requires substantial domain expertise, and does not scale easily to large systems, multiple systems, or novel system modifications. At the same time, many application domains, such as molecular biology, are rich in structured causal knowledge that is qualitative in nature. This manuscript proposes a general approach for querying a causal biological knowledge graph, and converting the qualitative result into a quantitative structural causal model that can learn from data to answer the question. We demonstrate the feasibility, accuracy and versatility of this approach using two case studies in systems biology. The first demonstrates the appropriateness of the underlying assumptions and the accuracy of the results. The second demonstrates the versatility of the approach by querying a knowledge base for the molecular determinants of a severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2)-induced cytokine storm, and performing counterfactual inference to estimate the causal effect of medical countermeasures for severely ill patients.
Machine Learning Algorithms for Active Monitoring of High Performance Computing as a Service (HPCaaS) Cloud Environments
Sep 26, 2020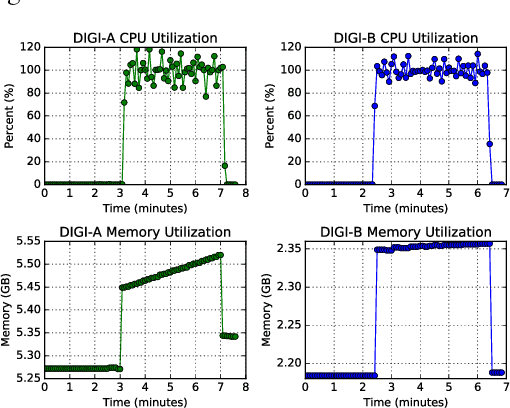
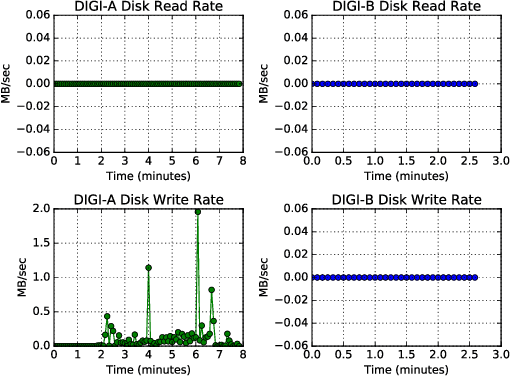
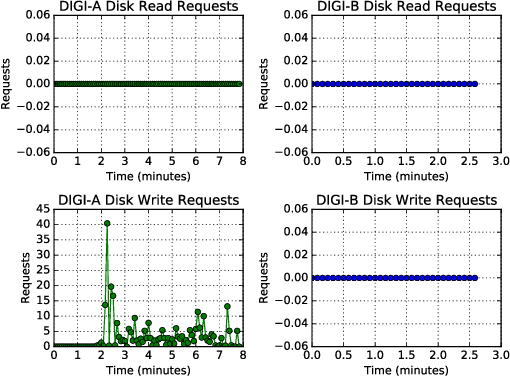
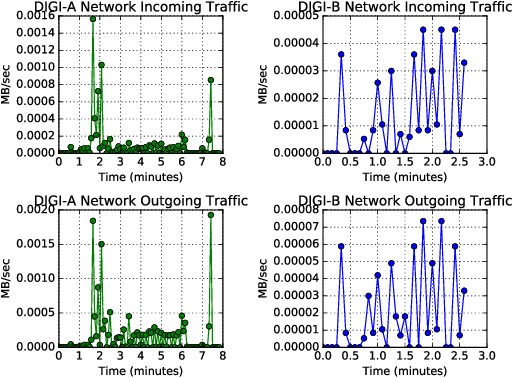
Cloud computing provides ubiquitous and on-demand access to vast reconfigurable resources that can meet any computational need. Many service models are available, but the Infrastructure as a Service (IaaS) model is particularly suited to operate as a high performance computing (HPC) platform, by networking large numbers of cloud computing nodes. We used the Pacific Northwest National Laboratory (PNNL) cloud computing environment to perform our experiments. A number of cloud computing providers such as Amazon Web Services, Microsoft Azure, or IBM Cloud, offer flexible and scalable computing resources. This paper explores the viability identifying types of engineering applications running on a cloud infrastructure configured as an HPC platform using privacy preserving features as input to statistical models. The engineering applications considered in this work include MCNP6, a radiation transport code developed by Los Alamos National Laboratory, OpenFOAM, an open source computational fluid dynamics code, and CADO-NFS, a numerical implementation of the general number field sieve algorithm used for prime number factorization. Our experiments use the OpenStack cloud management tool to create a cloud HPC environment and the privacy preserving Ceilometer billing meters as classification features to demonstrate identification of these applications.