 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplanatory Masks for Neural Network Interpretability
Paper and Code
Nov 15, 2019
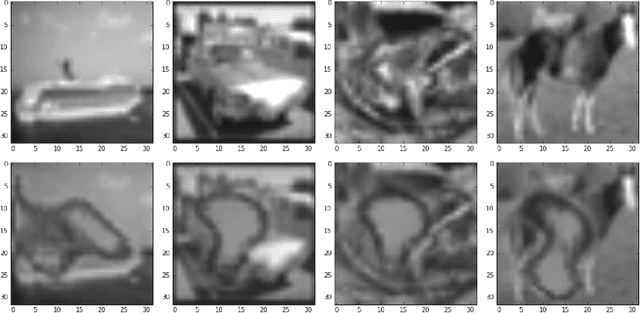


Neural network interpretability is a vital component for applications across a wide variety of domains. In such cases it is often useful to analyze a network which has already been trained for its specific purpose. In this work, we develop a method to produce explanation masks for pre-trained networks. The mask localizes the most important aspects of each input for prediction of the original network. Masks are created by a secondary network whose goal is to create as small an explanation as possible while still preserving the predictive accuracy of the original network. We demonstrate the applicability of our method for image classification with CNNs, sentiment analysis with RNNs, and chemical property prediction with mixed CNN/RNN architectures.