 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdjusting for Confounders with Text: Challenges and an Empirical Evaluation Framework for Causal Inference
Sep 21, 2020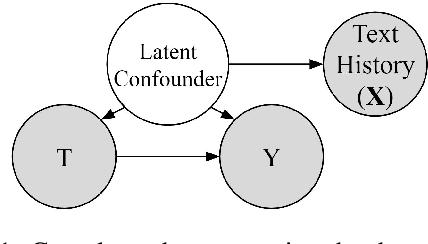
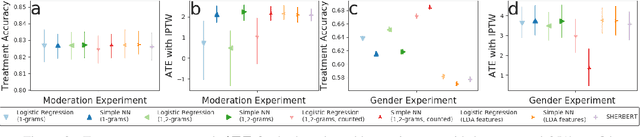
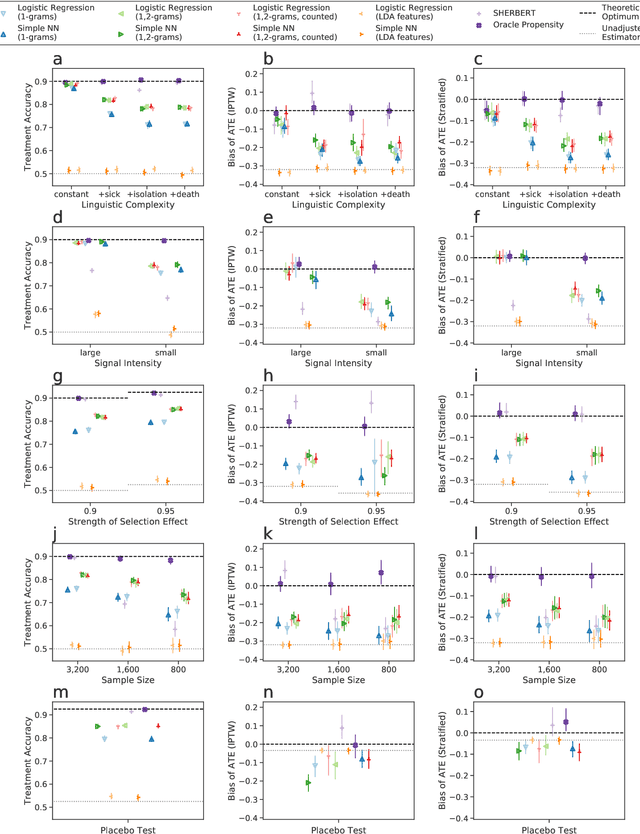
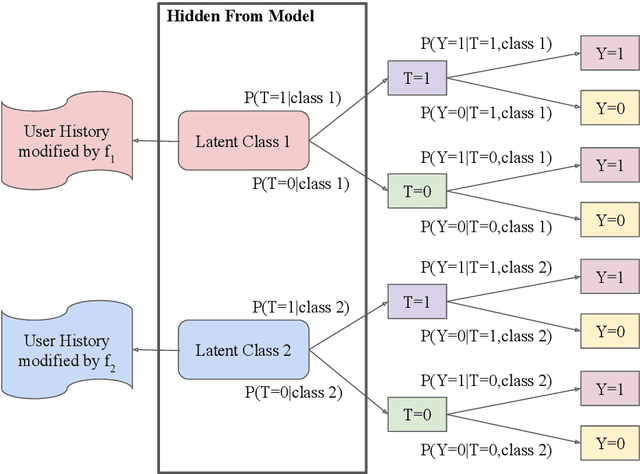
Leveraging text, such as social media posts, for causal inferences requires the use of NLP models to 'learn' and adjust for confounders, which could otherwise impart bias. However, evaluating such models is challenging, as ground truth is almost never available. We demonstrate the need for empirical evaluation frameworks for causal inference in natural language by showing that existing, commonly used models regularly disagree with one another on real world tasks. We contribute the first such framework, generalizing several challenges across these real world tasks. Using this framework, we evaluate a large set of commonly used causal inference models based on propensity scores and identify their strengths and weaknesses to inform future improvements. We make all tasks, data, and models public to inform applications and encourage additional research.