 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Power of Framing: How News Headlines Guide Search Behavior
Aug 23, 2025Search engines play a central role in how people gather information, but subtle cues like headline framing may influence not only what users believe but also how they search. While framing effects on judgment are well documented, their impact on subsequent search behavior is less understood. We conducted a controlled experiment where participants issued queries and selected from headlines filtered by specific linguistic frames. Headline framing significantly shaped follow-up queries: conflict and strategy frames disrupted alignment with prior selections, while episodic frames led to more concrete queries than thematic ones. We also observed modest short-term frame persistence that declined over time. These results suggest that even brief exposure to framing can meaningfully alter the direction of users information-seeking behavior.
Social and Political Framing in Search Engine Results
Jul 17, 2025Search engines play a crucial role in shaping public discourse by influencing how information is accessed and framed. While prior research has extensively examined various dimensions of search bias -- such as content prioritization, indexical bias, political polarization, and sources of bias -- an important question remains underexplored: how do search engines and ideologically-motivated user queries contribute to bias in search results. This study analyzes the outputs of major search engines using a dataset of political and social topics. The findings reveal that search engines not only prioritize content in ways that reflect underlying biases but also that ideologically-driven user queries exacerbate these biases, resulting in the amplification of specific narratives. Moreover, significant differences were observed across search engines in terms of the sources they prioritize. These results suggest that search engines may play a pivotal role in shaping public perceptions by reinforcing ideological divides, thereby contributing to the broader issue of information polarization.
* Accepted to ICWSM 2026
Digital Gatekeepers: Google's Role in Curating Hashtags and Subreddits
Jun 17, 2025Search engines play a crucial role as digital gatekeepers, shaping the visibility of Web and social media content through algorithmic curation. This study investigates how search engines like Google selectively promotes or suppresses certain hashtags and subreddits, impacting the information users encounter. By comparing search engine results with nonsampled data from Reddit and Twitter/X, we reveal systematic biases in content visibility. Google's algorithms tend to suppress subreddits and hashtags related to sexually explicit material, conspiracy theories, advertisements, and cryptocurrencies, while promoting content associated with higher engagement. These findings suggest that Google's gatekeeping practices influence public discourse by curating the social media narratives available to users.
* Accepted to ACL 2025 Main
Citations and Trust in LLM Generated Responses
Jan 02, 2025Question answering systems are rapidly advancing, but their opaque nature may impact user trust. We explored trust through an anti-monitoring framework, where trust is predicted to be correlated with presence of citations and inversely related to checking citations. We tested this hypothesis with a live question-answering experiment that presented text responses generated using a commercial Chatbot along with varying citations (zero, one, or five), both relevant and random, and recorded if participants checked the citations and their self-reported trust in the generated responses. We found a significant increase in trust when citations were present, a result that held true even when the citations were random; we also found a significant decrease in trust when participants checked the citations. These results highlight the importance of citations in enhancing trust in AI-generated content.
Modeling Information Narrative Detection and Evolution on Telegram during the Russia-Ukraine War
Sep 12, 2024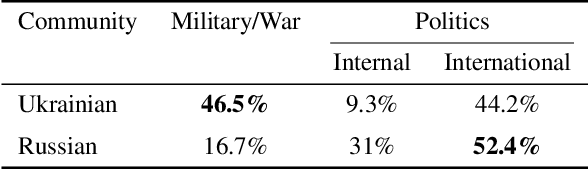
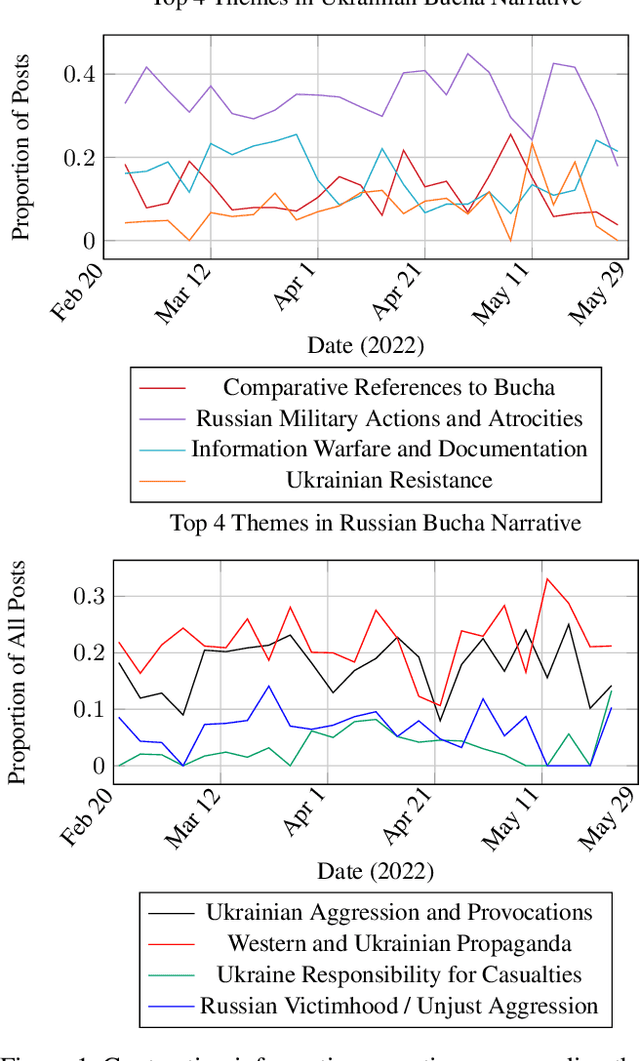
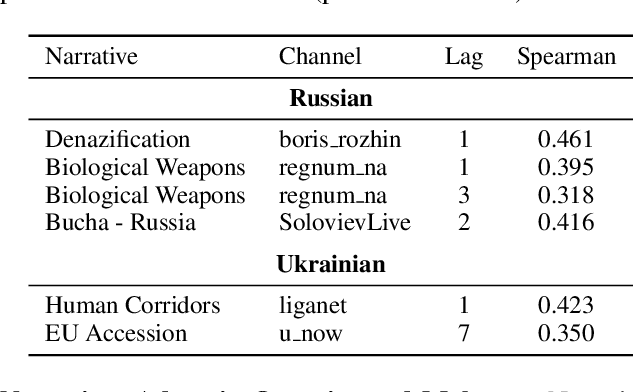
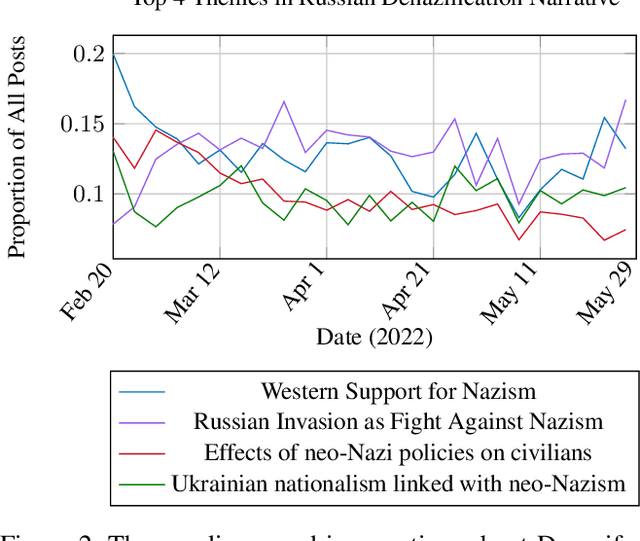
Following the Russian Federation's full-scale invasion of Ukraine in February 2022, a multitude of information narratives emerged within both pro-Russian and pro-Ukrainian communities online. As the conflict progresses, so too do the information narratives, constantly adapting and influencing local and global community perceptions and attitudes. This dynamic nature of the evolving information environment (IE) underscores a critical need to fully discern how narratives evolve and affect online communities. Existing research, however, often fails to capture information narrative evolution, overlooking both the fluid nature of narratives and the internal mechanisms that drive their evolution. Recognizing this, we introduce a novel approach designed to both model narrative evolution and uncover the underlying mechanisms driving them. In this work we perform a comparative discourse analysis across communities on Telegram covering the initial three months following the invasion. First, we uncover substantial disparities in narratives and perceptions between pro-Russian and pro-Ukrainian communities. Then, we probe deeper into prevalent narratives of each group, identifying key themes and examining the underlying mechanisms fueling their evolution. Finally, we explore influences and factors that may shape the development and spread of narratives.
Learning from Litigation: Graphs and LLMs for Retrieval and Reasoning in eDiscovery
May 29, 2024



Electronic Discovery (eDiscovery) involves identifying relevant documents from a vast collection based on legal production requests. The integration of artificial intelligence (AI) and natural language processing (NLP) has transformed this process, helping document review and enhance efficiency and cost-effectiveness. Although traditional approaches like BM25 or fine-tuned pre-trained models are common in eDiscovery, they face performance, computational, and interpretability challenges. In contrast, Large Language Model (LLM)-based methods prioritize interpretability but sacrifice performance and throughput. This paper introduces DISCOvery Graph (DISCOG), a hybrid approach that combines the strengths of two worlds: a heterogeneous graph-based method for accurate document relevance prediction and subsequent LLM-driven approach for reasoning. Graph representational learning generates embeddings and predicts links, ranking the corpus for a given request, and the LLMs provide reasoning for document relevance. Our approach handles datasets with balanced and imbalanced distributions, outperforming baselines in F1-score, precision, and recall by an average of 12%, 3%, and 16%, respectively. In an enterprise context, our approach drastically reduces document review costs by 99.9% compared to manual processes and by 95% compared to LLM-based classification methods
Span-Oriented Information Extraction -- A Unifying Perspective on Information Extraction
Mar 18, 2024Information Extraction refers to a collection of tasks within Natural Language Processing (NLP) that identifies sub-sequences within text and their labels. These tasks have been used for many years to link extract relevant information and to link free text to structured data. However, the heterogeneity among information extraction tasks impedes progress in this area. We therefore offer a unifying perspective centered on what we define to be spans in text. We then re-orient these seemingly incongruous tasks into this unified perspective and then re-present the wide assortment of information extraction tasks as variants of the same basic Span-Oriented Information Extraction task.
ChatEL: Entity Linking with Chatbots
Feb 20, 2024Entity Linking (EL) is an essential and challenging task in natural language processing that seeks to link some text representing an entity within a document or sentence with its corresponding entry in a dictionary or knowledge base. Most existing approaches focus on creating elaborate contextual models that look for clues the words surrounding the entity-text to help solve the linking problem. Although these fine-tuned language models tend to work, they can be unwieldy, difficult to train, and do not transfer well to other domains. Fortunately, Large Language Models (LLMs) like GPT provide a highly-advanced solution to the problems inherent in EL models, but simply naive prompts to LLMs do not work well. In the present work, we define ChatEL, which is a three-step framework to prompt LLMs to return accurate results. Overall the ChatEL framework improves the average F1 performance across 10 datasets by more than 2%. Finally, a thorough error analysis shows many instances with the ground truth labels were actually incorrect, and the labels predicted by ChatEL were actually correct. This indicates that the quantitative results presented in this paper may be a conservative estimate of the actual performance. All data and code are available as an open-source package on GitHub at https://github.com/yifding/In_Context_EL.
EntGPT: Linking Generative Large Language Models with Knowledge Bases
Feb 09, 2024



The ability of Large Language Models (LLMs) to generate factually correct output remains relatively unexplored due to the lack of fact-checking and knowledge grounding during training and inference. In this work, we aim to address this challenge through the Entity Disambiguation (ED) task. We first consider prompt engineering, and design a three-step hard-prompting method to probe LLMs' ED performance without supervised fine-tuning (SFT). Overall, the prompting method improves the micro-F_1 score of the original vanilla models by a large margin, on some cases up to 36% and higher, and obtains comparable performance across 10 datasets when compared to existing methods with SFT. We further improve the knowledge grounding ability through instruction tuning (IT) with similar prompts and responses. The instruction-tuned model not only achieves higher micro-F1 score performance as compared to several baseline methods on supervised entity disambiguation tasks with an average micro-F_1 improvement of 2.1% over the existing baseline models, but also obtains higher accuracy on six Question Answering (QA) tasks in the zero-shot setting. Our methodologies apply to both open- and closed-source LLMs.
Navigating the Post-API Dilemma Search Engine Results Pages Present a Biased View of Social Media Data
Jan 27, 2024

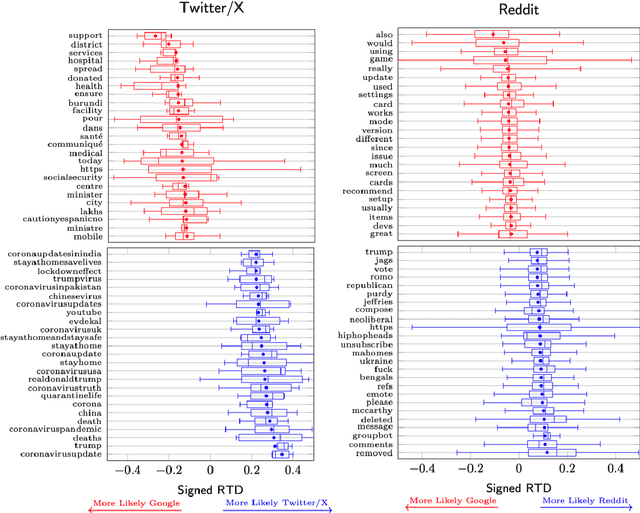
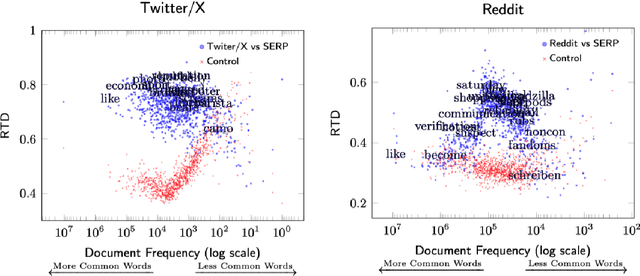
Recent decisions to discontinue access to social media APIs are having detrimental effects on Internet research and the field of computational social science as a whole. This lack of access to data has been dubbed the Post-API era of Internet research. Fortunately, popular search engines have the means to crawl, capture, and surface social media data on their Search Engine Results Pages (SERP) if provided the proper search query, and may provide a solution to this dilemma. In the present work we ask: does SERP provide a complete and unbiased sample of social media data? Is SERP a viable alternative to direct API-access? To answer these questions, we perform a comparative analysis between (Google) SERP results and nonsampled data from Reddit and Twitter/X. We find that SERP results are highly biased in favor of popular posts; against political, pornographic, and vulgar posts; are more positive in their sentiment; and have large topical gaps. Overall, we conclude that SERP is not a viable alternative to social media API access.