 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThis Probably Looks Exactly Like That: An Invertible Prototypical Network
Jul 16, 2024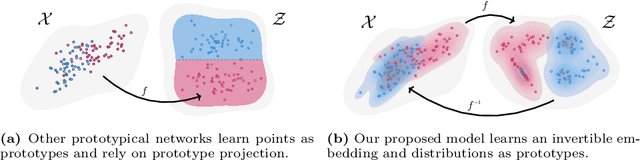
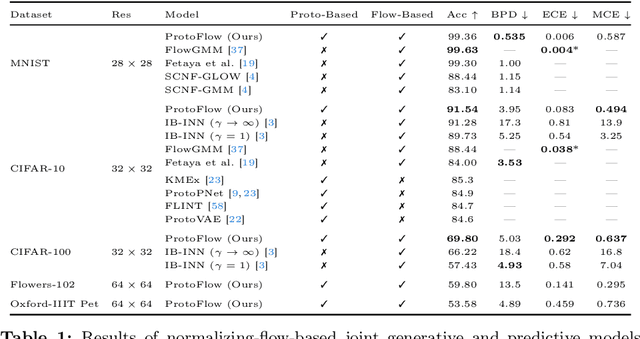
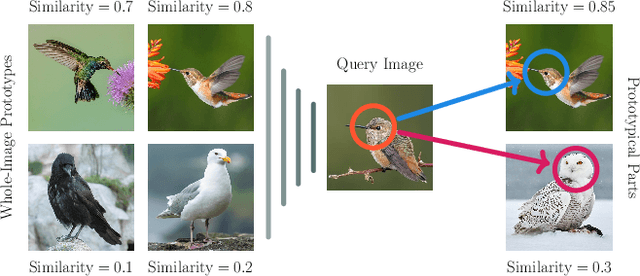
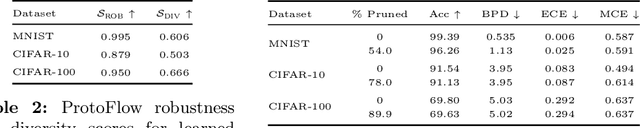
We combine concept-based neural networks with generative, flow-based classifiers into a novel, intrinsically explainable, exactly invertible approach to supervised learning. Prototypical neural networks, a type of concept-based neural network, represent an exciting way forward in realizing human-comprehensible machine learning without concept annotations, but a human-machine semantic gap continues to haunt current approaches. We find that reliance on indirect interpretation functions for prototypical explanations imposes a severe limit on prototypes' informative power. From this, we posit that invertibly learning prototypes as distributions over the latent space provides more robust, expressive, and interpretable modeling. We propose one such model, called ProtoFlow, by composing a normalizing flow with Gaussian mixture models. ProtoFlow (1) sets a new state-of-the-art in joint generative and predictive modeling and (2) achieves predictive performance comparable to existing prototypical neural networks while enabling richer interpretation.
Temporal Egonet Subgraph Transitions
Mar 26, 2023
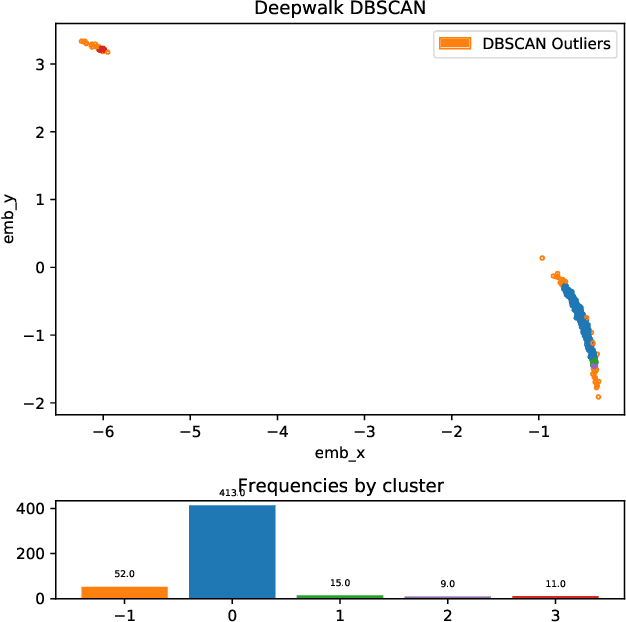
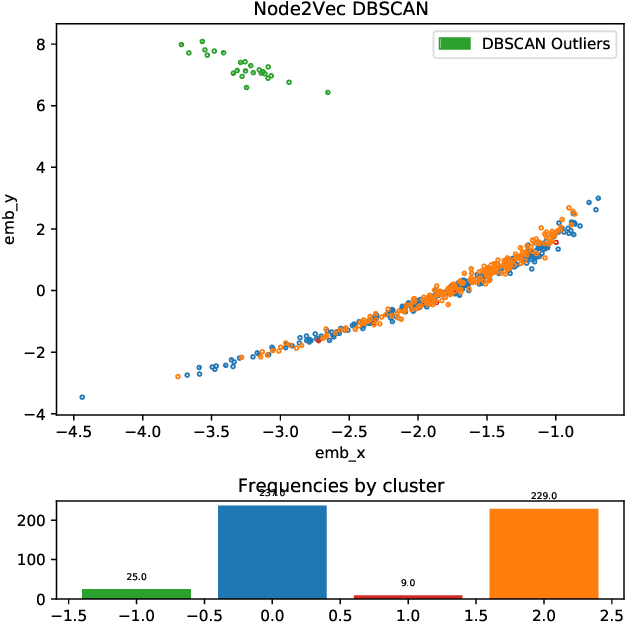
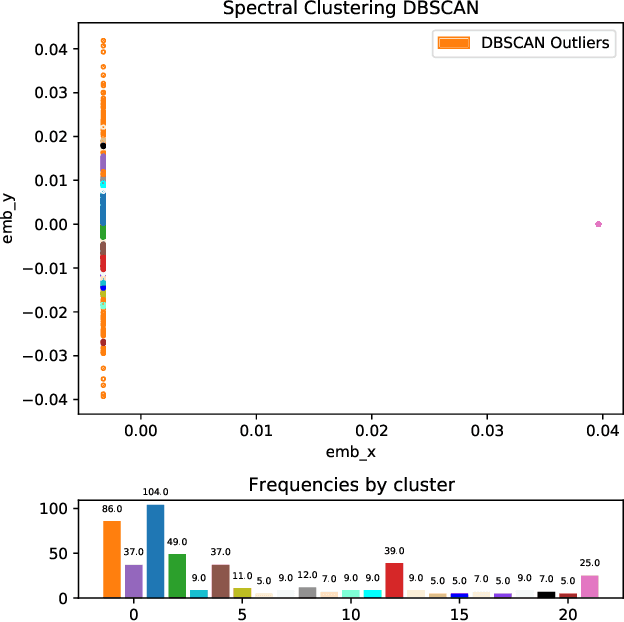
How do we summarize dynamic behavioral interactions? We introduce a possible node-embedding-based solution to this question: temporal egonet subgraph transitions.
Dynamic Vertex Replacement Grammars
Mar 22, 2023



Context-free graph grammars have shown a remarkable ability to model structures in real-world relational data. However, graph grammars lack the ability to capture time-changing phenomena since the left-to-right transitions of a production rule do not represent temporal change. In the present work, we describe dynamic vertex-replacement grammars (DyVeRG), which generalize vertex replacement grammars in the time domain by providing a formal framework for updating a learned graph grammar in accordance with modifications to its underlying data. We show that DyVeRG grammars can be learned from, and used to generate, real-world dynamic graphs faithfully while remaining human-interpretable. We also demonstrate their ability to forecast by computing dyvergence scores, a novel graph similarity measurement exposed by this framework.
Motif Mining: Finding and Summarizing Remixed Image Content
Mar 17, 2022
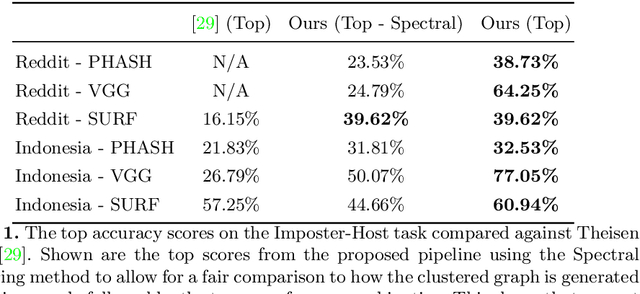
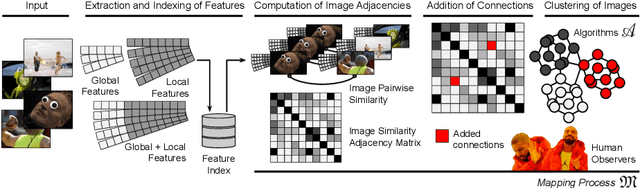
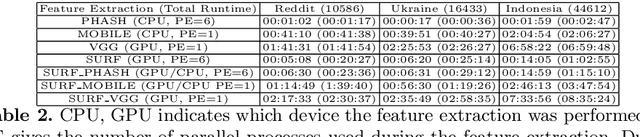
On the internet, images are no longer static; they have become dynamic content. Thanks to the availability of smartphones with cameras and easy-to-use editing software, images can be remixed (i.e., redacted, edited, and recombined with other content) on-the-fly and with a world-wide audience that can repeat the process. From digital art to memes, the evolution of images through time is now an important topic of study for digital humanists, social scientists, and media forensics specialists. However, because typical data sets in computer vision are composed of static content, the development of automated algorithms to analyze remixed content has been limited. In this paper, we introduce the idea of Motif Mining - the process of finding and summarizing remixed image content in large collections of unlabeled and unsorted data. In this paper, this idea is formalized and a reference implementation is introduced. Experiments are conducted on three meme-style data sets, including a newly collected set associated with the information war in the Russo-Ukrainian conflict. The proposed motif mining approach is able to identify related remixed content that, when compared to similar approaches, more closely aligns with the preferences and expectations of human observers.