 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSalient Information Preserving Adversarial Training Improves Clean and Robust Accuracy
Jan 15, 2025In this work we introduce Salient Information Preserving Adversarial Training (SIP-AT), an intuitive method for relieving the robustness-accuracy trade-off incurred by traditional adversarial training. SIP-AT uses salient image regions to guide the adversarial training process in such a way that fragile features deemed meaningful by an annotator remain unperturbed during training, allowing models to learn highly predictive non-robust features without sacrificing overall robustness. This technique is compatible with both human-based and automatically generated salience estimates, allowing SIP-AT to be used as a part of human-driven model development without forcing SIP-AT to be reliant upon additional human data. We perform experiments across multiple datasets and architectures and demonstrate that SIP-AT is able to boost the clean accuracy of models while maintaining a high degree of robustness against attacks at multiple epsilon levels. We complement our central experiments with an observational study measuring the rate at which human subjects successfully identify perturbed images. This study helps build a more intuitive understanding of adversarial attack strength and demonstrates the heightened importance of low-epsilon robustness. Our results demonstrate the efficacy of SIP-AT and provide valuable insight into the risks posed by adversarial samples of various strengths.
This Probably Looks Exactly Like That: An Invertible Prototypical Network
Jul 16, 2024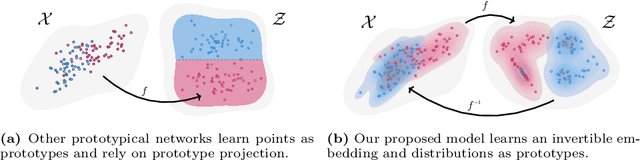
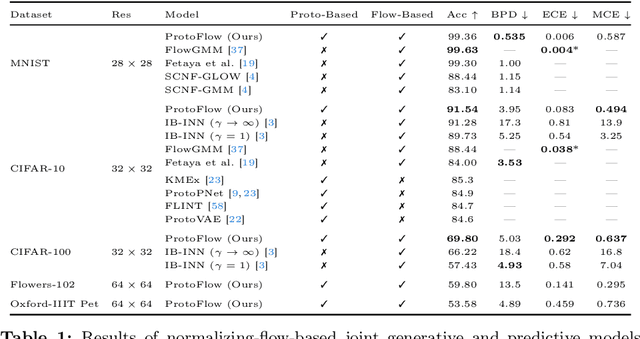
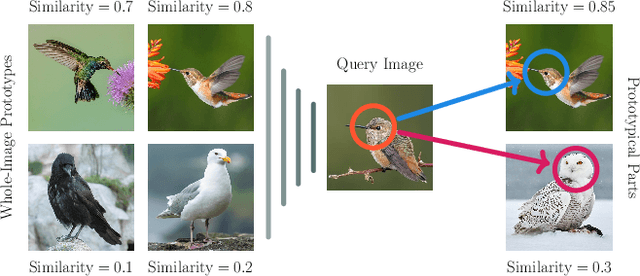
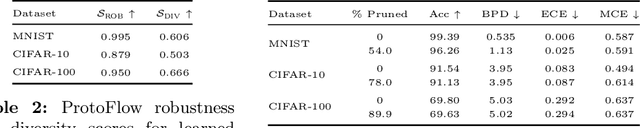
We combine concept-based neural networks with generative, flow-based classifiers into a novel, intrinsically explainable, exactly invertible approach to supervised learning. Prototypical neural networks, a type of concept-based neural network, represent an exciting way forward in realizing human-comprehensible machine learning without concept annotations, but a human-machine semantic gap continues to haunt current approaches. We find that reliance on indirect interpretation functions for prototypical explanations imposes a severe limit on prototypes' informative power. From this, we posit that invertibly learning prototypes as distributions over the latent space provides more robust, expressive, and interpretable modeling. We propose one such model, called ProtoFlow, by composing a normalizing flow with Gaussian mixture models. ProtoFlow (1) sets a new state-of-the-art in joint generative and predictive modeling and (2) achieves predictive performance comparable to existing prototypical neural networks while enabling richer interpretation.
Generating Adversarial Samples in Mini-Batches May Be Detrimental To Adversarial Robustness
Mar 30, 2023



Neural networks have been proven to be both highly effective within computer vision, and highly vulnerable to adversarial attacks. Consequently, as the use of neural networks increases due to their unrivaled performance, so too does the threat posed by adversarial attacks. In this work, we build towards addressing the challenge of adversarial robustness by exploring the relationship between the mini-batch size used during adversarial sample generation and the strength of the adversarial samples produced. We demonstrate that an increase in mini-batch size results in a decrease in the efficacy of the samples produced, and we draw connections between these observations and the phenomenon of vanishing gradients. Next, we formulate loss functions such that adversarial sample strength is not degraded by mini-batch size. Our findings highlight a potential risk for underestimating the true (practical) strength of adversarial attacks, and a risk of overestimating a model's robustness. We share our codes to let others replicate our experiments and to facilitate further exploration of the connections between batch size and adversarial sample strength.