 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpan-Oriented Information Extraction -- A Unifying Perspective on Information Extraction
Mar 18, 2024Information Extraction refers to a collection of tasks within Natural Language Processing (NLP) that identifies sub-sequences within text and their labels. These tasks have been used for many years to link extract relevant information and to link free text to structured data. However, the heterogeneity among information extraction tasks impedes progress in this area. We therefore offer a unifying perspective centered on what we define to be spans in text. We then re-orient these seemingly incongruous tasks into this unified perspective and then re-present the wide assortment of information extraction tasks as variants of the same basic Span-Oriented Information Extraction task.
MEWS: Real-time Social Media Manipulation Detection and Analysis
May 13, 2022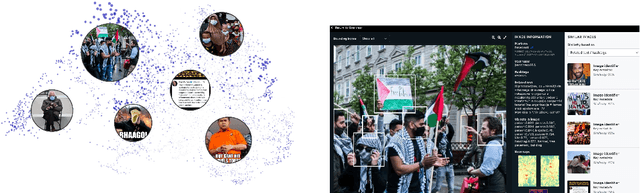
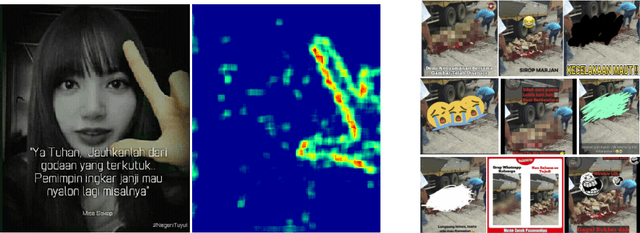

This article presents a beta-version of MEWS (Misinformation Early Warning System). It describes the various aspects of the ingestion, manipulation detection, and graphing algorithms employed to determine--in near real-time--the relationships between social media images as they emerge and spread on social media platforms. By combining these various technologies into a single processing pipeline, MEWS can identify manipulated media items as they arise and identify when these particular items begin trending on individual social media platforms or even across multiple platforms. The emergence of a novel manipulation followed by rapid diffusion of the manipulated content suggests a disinformation campaign.