 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-generated Text Detection: A Multifaceted Approach to Binary and Multiclass Classification
May 15, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in generating text that closely resembles human writing across a wide range of styles and genres. However, such capabilities are prone to potential misuse, such as fake news generation, spam email creation, and misuse in academic assignments. As a result, accurate detection of AI-generated text and identification of the model that generated it are crucial for maintaining the responsible use of LLMs. In this work, we addressed two sub-tasks put forward by the Defactify workshop under AI-Generated Text Detection shared task at the Association for the Advancement of Artificial Intelligence (AAAI 2025): Task A involved distinguishing between human-authored or AI-generated text, while Task B focused on attributing text to its originating language model. For each task, we proposed two neural architectures: an optimized model and a simpler variant. For Task A, the optimized neural architecture achieved fifth place with $F1$ score of 0.994, and for Task B, the simpler neural architecture also ranked fifth place with $F1$ score of 0.627.
Citations and Trust in LLM Generated Responses
Jan 02, 2025Question answering systems are rapidly advancing, but their opaque nature may impact user trust. We explored trust through an anti-monitoring framework, where trust is predicted to be correlated with presence of citations and inversely related to checking citations. We tested this hypothesis with a live question-answering experiment that presented text responses generated using a commercial Chatbot along with varying citations (zero, one, or five), both relevant and random, and recorded if participants checked the citations and their self-reported trust in the generated responses. We found a significant increase in trust when citations were present, a result that held true even when the citations were random; we also found a significant decrease in trust when participants checked the citations. These results highlight the importance of citations in enhancing trust in AI-generated content.
Learning from Litigation: Graphs and LLMs for Retrieval and Reasoning in eDiscovery
May 29, 2024



Electronic Discovery (eDiscovery) involves identifying relevant documents from a vast collection based on legal production requests. The integration of artificial intelligence (AI) and natural language processing (NLP) has transformed this process, helping document review and enhance efficiency and cost-effectiveness. Although traditional approaches like BM25 or fine-tuned pre-trained models are common in eDiscovery, they face performance, computational, and interpretability challenges. In contrast, Large Language Model (LLM)-based methods prioritize interpretability but sacrifice performance and throughput. This paper introduces DISCOvery Graph (DISCOG), a hybrid approach that combines the strengths of two worlds: a heterogeneous graph-based method for accurate document relevance prediction and subsequent LLM-driven approach for reasoning. Graph representational learning generates embeddings and predicts links, ranking the corpus for a given request, and the LLMs provide reasoning for document relevance. Our approach handles datasets with balanced and imbalanced distributions, outperforming baselines in F1-score, precision, and recall by an average of 12%, 3%, and 16%, respectively. In an enterprise context, our approach drastically reduces document review costs by 99.9% compared to manual processes and by 95% compared to LLM-based classification methods
EntGPT: Linking Generative Large Language Models with Knowledge Bases
Feb 09, 2024



The ability of Large Language Models (LLMs) to generate factually correct output remains relatively unexplored due to the lack of fact-checking and knowledge grounding during training and inference. In this work, we aim to address this challenge through the Entity Disambiguation (ED) task. We first consider prompt engineering, and design a three-step hard-prompting method to probe LLMs' ED performance without supervised fine-tuning (SFT). Overall, the prompting method improves the micro-F_1 score of the original vanilla models by a large margin, on some cases up to 36% and higher, and obtains comparable performance across 10 datasets when compared to existing methods with SFT. We further improve the knowledge grounding ability through instruction tuning (IT) with similar prompts and responses. The instruction-tuned model not only achieves higher micro-F1 score performance as compared to several baseline methods on supervised entity disambiguation tasks with an average micro-F_1 improvement of 2.1% over the existing baseline models, but also obtains higher accuracy on six Question Answering (QA) tasks in the zero-shot setting. Our methodologies apply to both open- and closed-source LLMs.
A Simple yet Efficient Ensemble Approach for AI-generated Text Detection
Nov 08, 2023Recent Large Language Models (LLMs) have demonstrated remarkable capabilities in generating text that closely resembles human writing across wide range of styles and genres. However, such capabilities are prone to potential abuse, such as fake news generation, spam email creation, and misuse in academic assignments. Hence, it is essential to build automated approaches capable of distinguishing between artificially generated text and human-authored text. In this paper, we propose a simple yet efficient solution to this problem by ensembling predictions from multiple constituent LLMs. Compared to previous state-of-the-art approaches, which are perplexity-based or uses ensembles with a number of LLMs, our condensed ensembling approach uses only two constituent LLMs to achieve comparable performance. Experiments conducted on four benchmark datasets for generative text classification show performance improvements in the range of 0.5 to 100\% compared to previous state-of-the-art approaches. We also study the influence that the training data from individual LLMs have on model performance. We found that substituting commercially-restrictive Generative Pre-trained Transformer (GPT) data with data generated from other open language models such as Falcon, Large Language Model Meta AI (LLaMA2), and Mosaic Pretrained Transformers (MPT) is a feasible alternative when developing generative text detectors. Furthermore, to demonstrate zero-shot generalization, we experimented with an English essays dataset, and results suggest that our ensembling approach can handle new data effectively.
Generative AI Text Classification using Ensemble LLM Approaches
Sep 14, 2023Large Language Models (LLMs) have shown impressive performance across a variety of Artificial Intelligence (AI) and natural language processing tasks, such as content creation, report generation, etc. However, unregulated malign application of these models can create undesirable consequences such as generation of fake news, plagiarism, etc. As a result, accurate detection of AI-generated language can be crucial in responsible usage of LLMs. In this work, we explore 1) whether a certain body of text is AI generated or written by human, and 2) attribution of a specific language model in generating a body of text. Texts in both English and Spanish are considered. The datasets used in this study are provided as part of the Automated Text Identification (AuTexTification) shared task. For each of the research objectives stated above, we propose an ensemble neural model that generates probabilities from different pre-trained LLMs which are used as features to a Traditional Machine Learning (TML) classifier following it. For the first task of distinguishing between AI and human generated text, our model ranked in fifth and thirteenth place (with macro $F1$ scores of 0.733 and 0.649) for English and Spanish texts, respectively. For the second task on model attribution, our model ranked in first place with macro $F1$ scores of 0.625 and 0.653 for English and Spanish texts, respectively.
Anomaly Detection via Federated Learning
Oct 12, 2022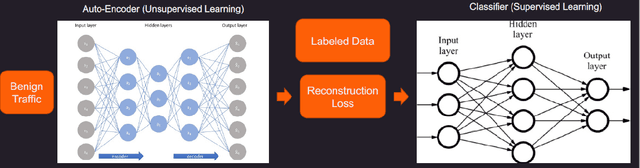
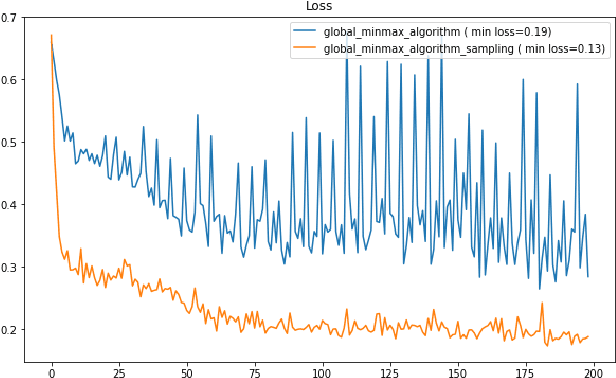
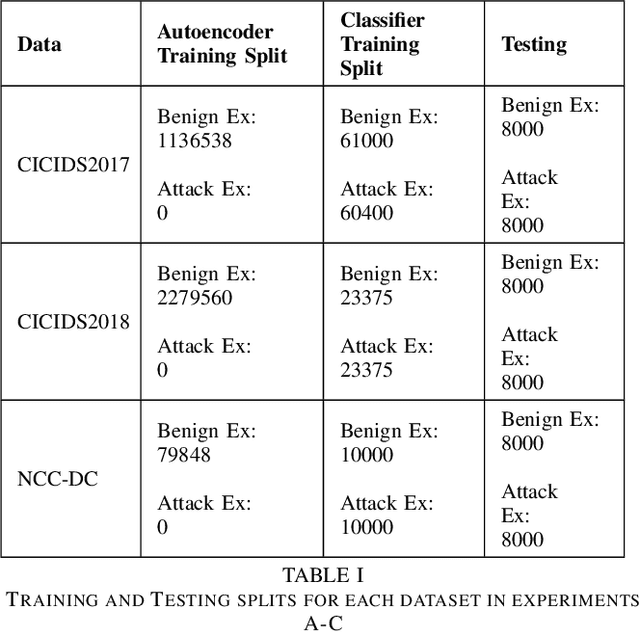
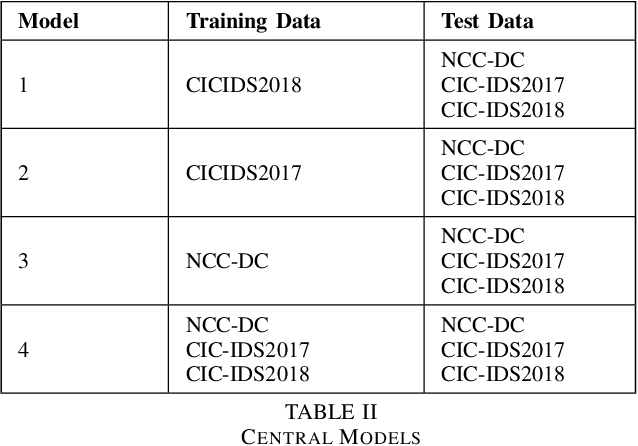
Machine learning has helped advance the field of anomaly detection by incorporating classifiers and autoencoders to decipher between normal and anomalous behavior. Additionally, federated learning has provided a way for a global model to be trained with multiple clients' data without requiring the client to directly share their data. This paper proposes a novel anomaly detector via federated learning to detect malicious network activity on a client's server. In our experiments, we use an autoencoder with a classifier in a federated learning framework to determine if the network activity is benign or malicious. By using our novel min-max scalar and sampling technique, called FedSam, we determined federated learning allows the global model to learn from each client's data and, in turn, provide a means for each client to improve their intrusion detection system's defense against cyber-attacks.