 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Query Efficiency and Accuracy of Transfer Learning-based Model Extraction Attack in Federated Learning
May 25, 2025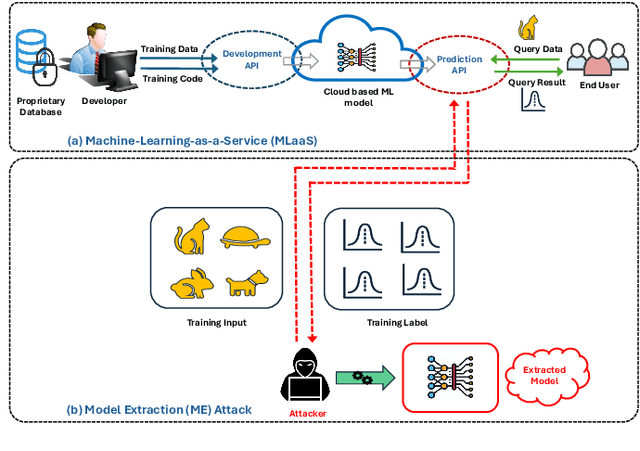
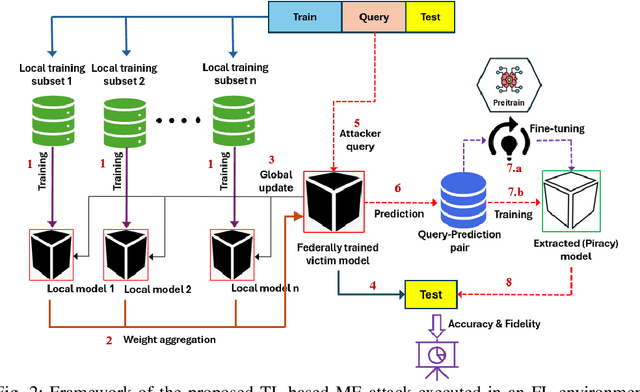
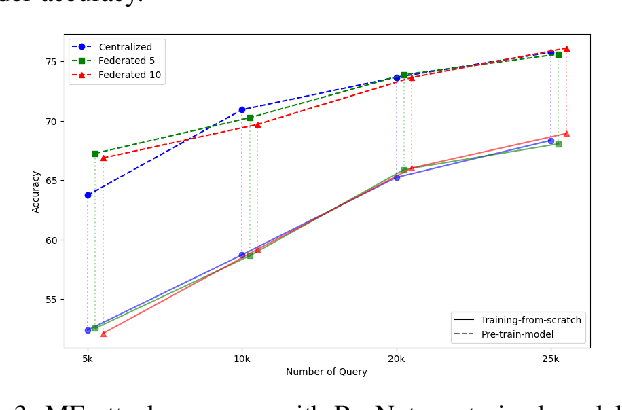
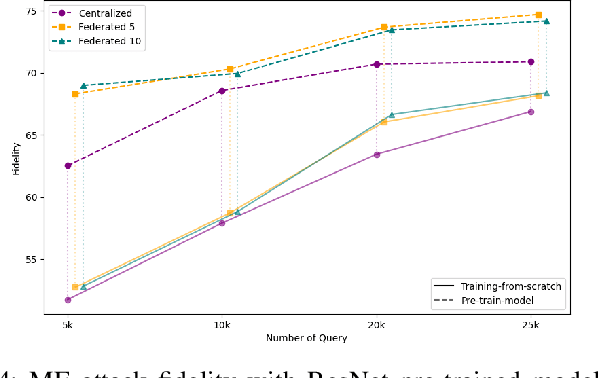
Federated Learning (FL) is a collaborative learning framework designed to protect client data, yet it remains highly vulnerable to Intellectual Property (IP) threats. Model extraction (ME) attacks pose a significant risk to Machine Learning as a Service (MLaaS) platforms, enabling attackers to replicate confidential models by querying black-box (without internal insight) APIs. Despite FL's privacy-preserving goals, its distributed nature makes it particularly susceptible to such attacks. This paper examines the vulnerability of FL-based victim models to two types of model extraction attacks. For various federated clients built under the NVFlare platform, we implemented ME attacks across two deep learning architectures and three image datasets. We evaluate the proposed ME attack performance using various metrics, including accuracy, fidelity, and KL divergence. The experiments show that for different FL clients, the accuracy and fidelity of the extracted model are closely related to the size of the attack query set. Additionally, we explore a transfer learning based approach where pretrained models serve as the starting point for the extraction process. The results indicate that the accuracy and fidelity of the fine-tuned pretrained extraction models are notably higher, particularly with smaller query sets, highlighting potential advantages for attackers.
Retrieval Augmented Anomaly Detection (RAAD): Nimble Model Adjustment Without Retraining
Feb 26, 2025We propose a novel mechanism for real-time (human-in-the-loop) feedback focused on false positive reduction to enhance anomaly detection models. It was designed for the lightweight deployment of a behavioral network anomaly detection model. This methodology is easily integrable to similar domains that require a premium on throughput while maintaining high precision. In this paper, we introduce Retrieval Augmented Anomaly Detection, a novel method taking inspiration from Retrieval Augmented Generation. Human annotated examples are sent to a vector store, which can modify model outputs on the very next processed batch for model inference. To demonstrate the generalization of this technique, we benchmarked several different model architectures and multiple data modalities, including images, text, and graph-based data.
Privacy Drift: Evolving Privacy Concerns in Incremental Learning
Dec 06, 2024In the evolving landscape of machine learning (ML), Federated Learning (FL) presents a paradigm shift towards decentralized model training while preserving user data privacy. This paper introduces the concept of ``privacy drift", an innovative framework that parallels the well-known phenomenon of concept drift. While concept drift addresses the variability in model accuracy over time due to changes in the data, privacy drift encapsulates the variation in the leakage of private information as models undergo incremental training. By defining and examining privacy drift, this study aims to unveil the nuanced relationship between the evolution of model performance and the integrity of data privacy. Through rigorous experimentation, we investigate the dynamics of privacy drift in FL systems, focusing on how model updates and data distribution shifts influence the susceptibility of models to privacy attacks, such as membership inference attacks (MIA). Our results highlight a complex interplay between model accuracy and privacy safeguards, revealing that enhancements in model performance can lead to increased privacy risks. We provide empirical evidence from experiments on customized datasets derived from CIFAR-100 (Canadian Institute for Advanced Research, 100 classes), showcasing the impact of data and concept drift on privacy. This work lays the groundwork for future research on privacy-aware machine learning, aiming to achieve a delicate balance between model accuracy and data privacy in decentralized environments.
Accuracy-Privacy Trade-off in the Mitigation of Membership Inference Attack in Federated Learning
Jul 26, 2024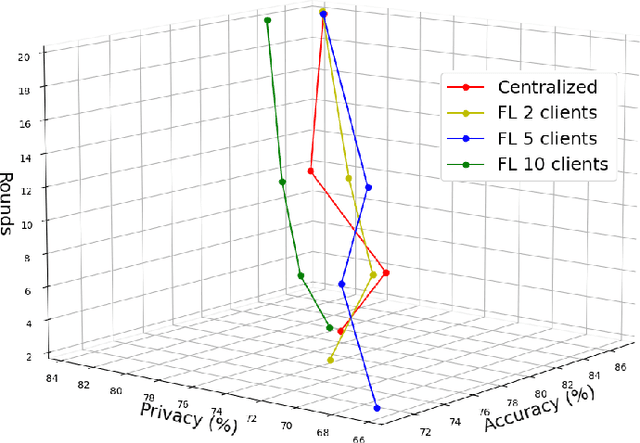
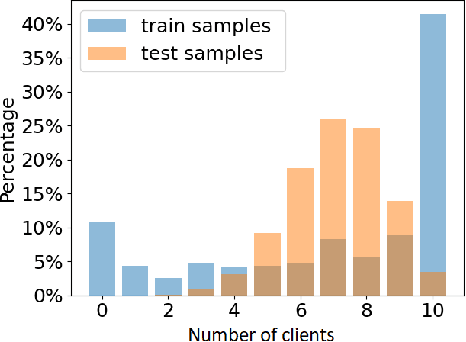
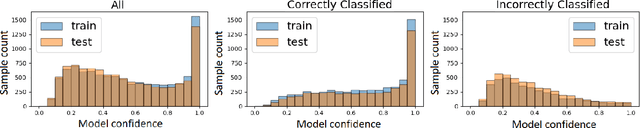
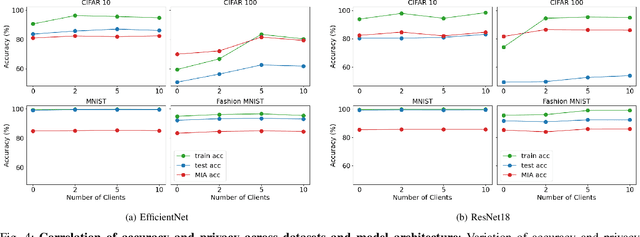
Over the last few years, federated learning (FL) has emerged as a prominent method in machine learning, emphasizing privacy preservation by allowing multiple clients to collaboratively build a model while keeping their training data private. Despite this focus on privacy, FL models are susceptible to various attacks, including membership inference attacks (MIAs), posing a serious threat to data confidentiality. In a recent study, Rezaei \textit{et al.} revealed the existence of an accuracy-privacy trade-off in deep ensembles and proposed a few fusion strategies to overcome it. In this paper, we aim to explore the relationship between deep ensembles and FL. Specifically, we investigate whether confidence-based metrics derived from deep ensembles apply to FL and whether there is a trade-off between accuracy and privacy in FL with respect to MIA. Empirical investigations illustrate a lack of a non-monotonic correlation between the number of clients and the accuracy-privacy trade-off. By experimenting with different numbers of federated clients, datasets, and confidence-metric-based fusion strategies, we identify and analytically justify the clear existence of the accuracy-privacy trade-off.
FedBayes: A Zero-Trust Federated Learning Aggregation to Defend Against Adversarial Attacks
Dec 04, 2023Federated learning has created a decentralized method to train a machine learning model without needing direct access to client data. The main goal of a federated learning architecture is to protect the privacy of each client while still contributing to the training of the global model. However, the main advantage of privacy in federated learning is also the easiest aspect to exploit. Without being able to see the clients' data, it is difficult to determine the quality of the data. By utilizing data poisoning methods, such as backdoor or label-flipping attacks, or by sending manipulated information about their data back to the server, malicious clients are able to corrupt the global model and degrade performance across all clients within a federation. Our novel aggregation method, FedBayes, mitigates the effect of a malicious client by calculating the probabilities of a client's model weights given to the prior model's weights using Bayesian statistics. Our results show that this approach negates the effects of malicious clients and protects the overall federation.
MIA-BAD: An Approach for Enhancing Membership Inference Attack and its Mitigation with Federated Learning
Nov 28, 2023The membership inference attack (MIA) is a popular paradigm for compromising the privacy of a machine learning (ML) model. MIA exploits the natural inclination of ML models to overfit upon the training data. MIAs are trained to distinguish between training and testing prediction confidence to infer membership information. Federated Learning (FL) is a privacy-preserving ML paradigm that enables multiple clients to train a unified model without disclosing their private data. In this paper, we propose an enhanced Membership Inference Attack with the Batch-wise generated Attack Dataset (MIA-BAD), a modification to the MIA approach. We investigate that the MIA is more accurate when the attack dataset is generated batch-wise. This quantitatively decreases the attack dataset while qualitatively improving it. We show how training an ML model through FL, has some distinct advantages and investigate how the threat introduced with the proposed MIA-BAD approach can be mitigated with FL approaches. Finally, we demonstrate the qualitative effects of the proposed MIA-BAD methodology by conducting extensive experiments with various target datasets, variable numbers of federated clients, and training batch sizes.
Zero Day Threat Detection Using Metric Learning Autoencoders
Nov 01, 2022The proliferation of zero-day threats (ZDTs) to companies' networks has been immensely costly and requires novel methods to scan traffic for malicious behavior at massive scale. The diverse nature of normal behavior along with the huge landscape of attack types makes deep learning methods an attractive option for their ability to capture highly-nonlinear behavior patterns. In this paper, the authors demonstrate an improvement upon a previously introduced methodology, which used a dual-autoencoder approach to identify ZDTs in network flow telemetry. In addition to the previously-introduced asset-level graph features, which help abstractly represent the role of a host in its network, this new model uses metric learning to train the second autoencoder on labeled attack data. This not only produces stronger performance, but it has the added advantage of improving the interpretability of the model by allowing for multiclass classification in the latent space. This can potentially save human threat hunters time when they investigate predicted ZDTs by showing them which known attack classes were nearby in the latent space. The models presented here are also trained and evaluated with two more datasets, and continue to show promising results even when generalizing to new network topologies.
Anomaly Detection via Federated Learning
Oct 12, 2022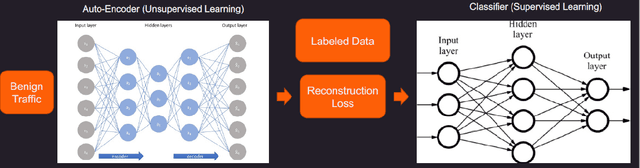
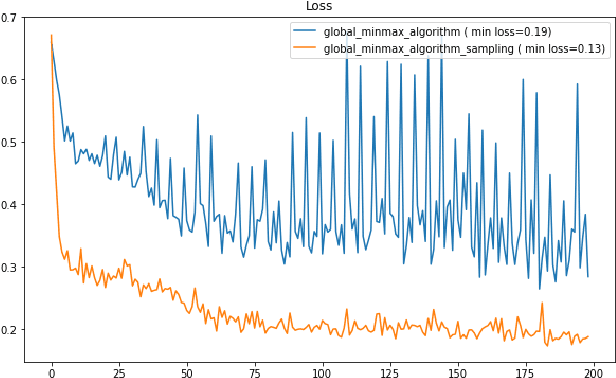
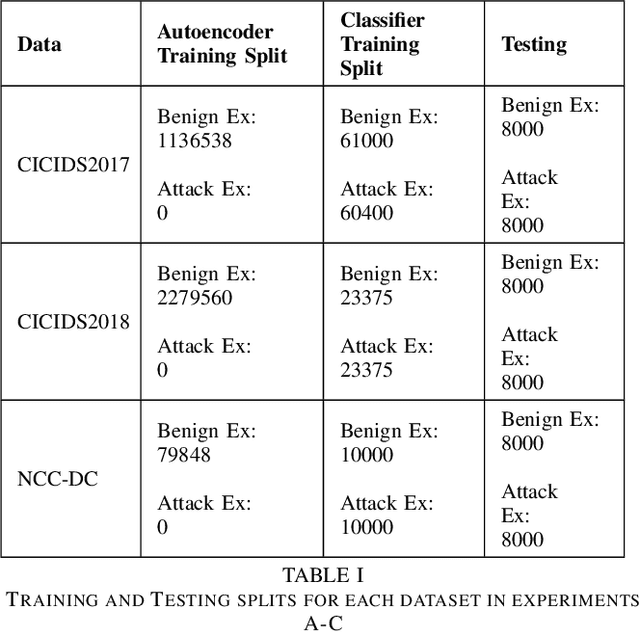
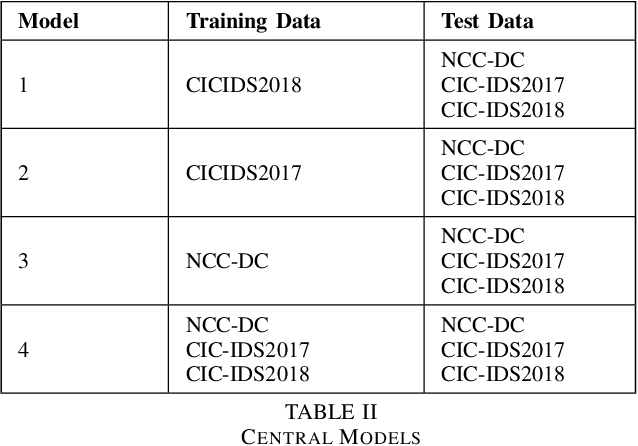
Machine learning has helped advance the field of anomaly detection by incorporating classifiers and autoencoders to decipher between normal and anomalous behavior. Additionally, federated learning has provided a way for a global model to be trained with multiple clients' data without requiring the client to directly share their data. This paper proposes a novel anomaly detector via federated learning to detect malicious network activity on a client's server. In our experiments, we use an autoencoder with a classifier in a federated learning framework to determine if the network activity is benign or malicious. By using our novel min-max scalar and sampling technique, called FedSam, we determined federated learning allows the global model to learn from each client's data and, in turn, provide a means for each client to improve their intrusion detection system's defense against cyber-attacks.