 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Value in the Age of Scaling: Understanding LLM Scaling Dynamics Under Real-Synthetic Data Mixtures
Nov 17, 2025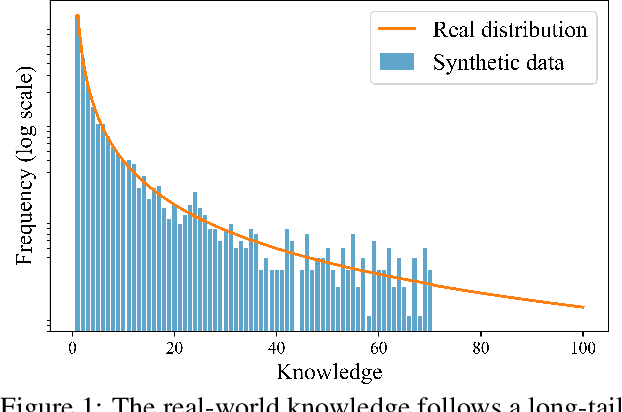
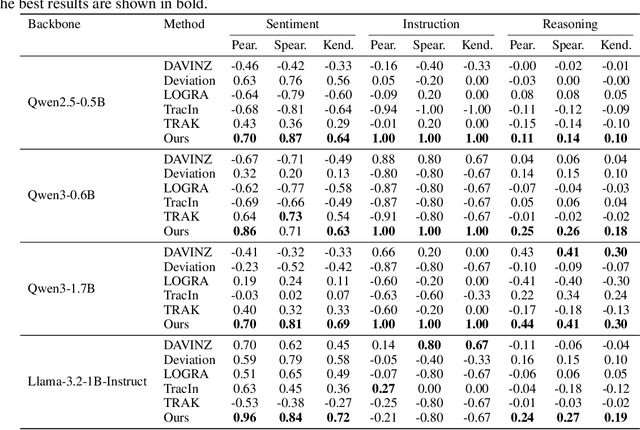
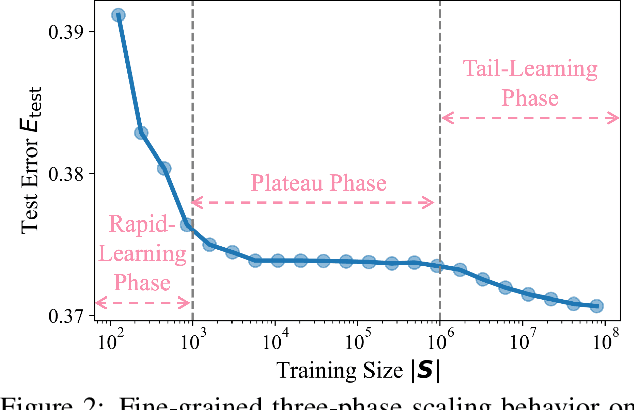
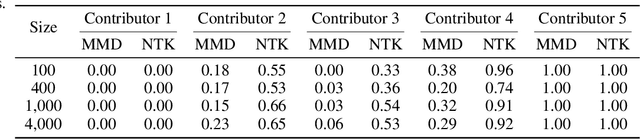
The rapid progress of large language models (LLMs) is fueled by the growing reliance on datasets that blend real and synthetic data. While synthetic data offers scalability and cost-efficiency, it often introduces systematic distributional discrepancies, particularly underrepresenting long-tail knowledge due to truncation effects from data generation mechanisms like top-p sampling, temperature scaling, and finite sampling. These discrepancies pose fundamental challenges in characterizing and evaluating the utility of mixed real-synthetic datasets. In this paper, we identify a three-phase scaling behavior characterized by two breakpoints that reflect transitions in model behavior across learning head and tail knowledge. We further derive an LLM generalization bound designed for real and synthetic mixtures, revealing several key factors that govern their generalization performance. Building on our theoretical findings, we propose an effective yet efficient data valuation method that scales to large-scale datasets. Comprehensive experiments across four tasks, including image classification, sentiment classification, instruction following, and complex reasoning, demonstrate that our method surpasses state-of-the-art baselines in data valuation with significantly low computational cost.
Evaluating Query Efficiency and Accuracy of Transfer Learning-based Model Extraction Attack in Federated Learning
May 25, 2025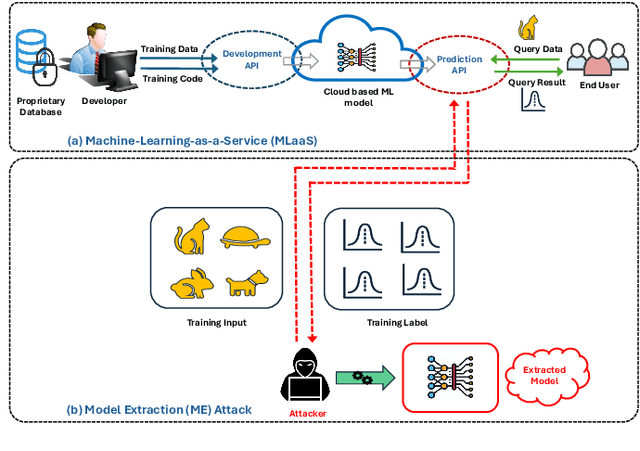
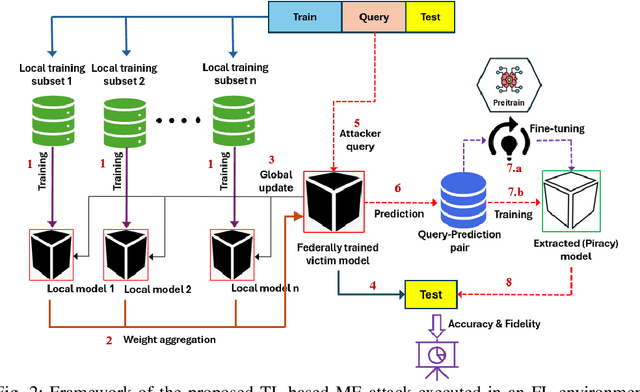
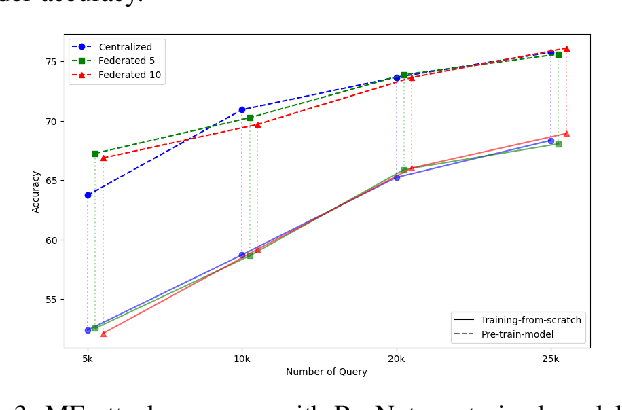
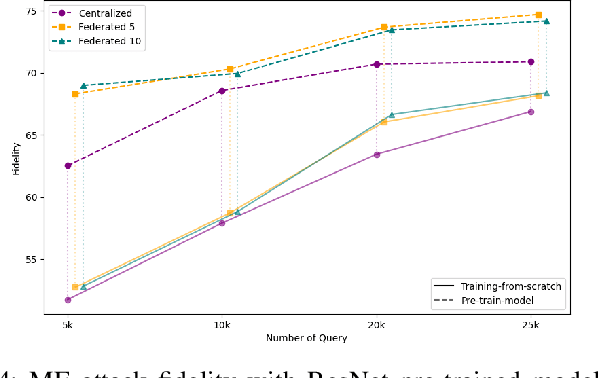
Federated Learning (FL) is a collaborative learning framework designed to protect client data, yet it remains highly vulnerable to Intellectual Property (IP) threats. Model extraction (ME) attacks pose a significant risk to Machine Learning as a Service (MLaaS) platforms, enabling attackers to replicate confidential models by querying black-box (without internal insight) APIs. Despite FL's privacy-preserving goals, its distributed nature makes it particularly susceptible to such attacks. This paper examines the vulnerability of FL-based victim models to two types of model extraction attacks. For various federated clients built under the NVFlare platform, we implemented ME attacks across two deep learning architectures and three image datasets. We evaluate the proposed ME attack performance using various metrics, including accuracy, fidelity, and KL divergence. The experiments show that for different FL clients, the accuracy and fidelity of the extracted model are closely related to the size of the attack query set. Additionally, we explore a transfer learning based approach where pretrained models serve as the starting point for the extraction process. The results indicate that the accuracy and fidelity of the fine-tuned pretrained extraction models are notably higher, particularly with smaller query sets, highlighting potential advantages for attackers.
Privacy Drift: Evolving Privacy Concerns in Incremental Learning
Dec 06, 2024In the evolving landscape of machine learning (ML), Federated Learning (FL) presents a paradigm shift towards decentralized model training while preserving user data privacy. This paper introduces the concept of ``privacy drift", an innovative framework that parallels the well-known phenomenon of concept drift. While concept drift addresses the variability in model accuracy over time due to changes in the data, privacy drift encapsulates the variation in the leakage of private information as models undergo incremental training. By defining and examining privacy drift, this study aims to unveil the nuanced relationship between the evolution of model performance and the integrity of data privacy. Through rigorous experimentation, we investigate the dynamics of privacy drift in FL systems, focusing on how model updates and data distribution shifts influence the susceptibility of models to privacy attacks, such as membership inference attacks (MIA). Our results highlight a complex interplay between model accuracy and privacy safeguards, revealing that enhancements in model performance can lead to increased privacy risks. We provide empirical evidence from experiments on customized datasets derived from CIFAR-100 (Canadian Institute for Advanced Research, 100 classes), showcasing the impact of data and concept drift on privacy. This work lays the groundwork for future research on privacy-aware machine learning, aiming to achieve a delicate balance between model accuracy and data privacy in decentralized environments.
Accuracy-Privacy Trade-off in the Mitigation of Membership Inference Attack in Federated Learning
Jul 26, 2024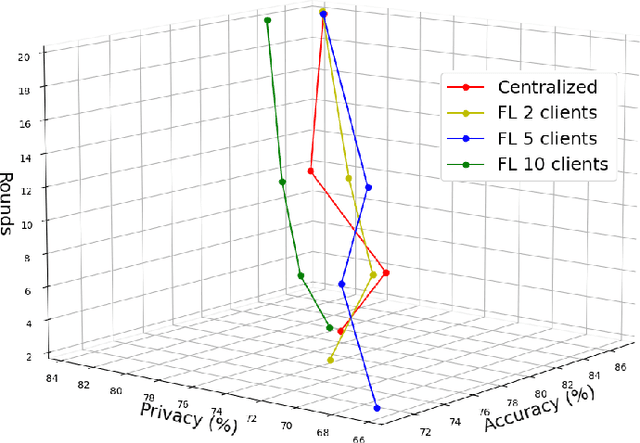
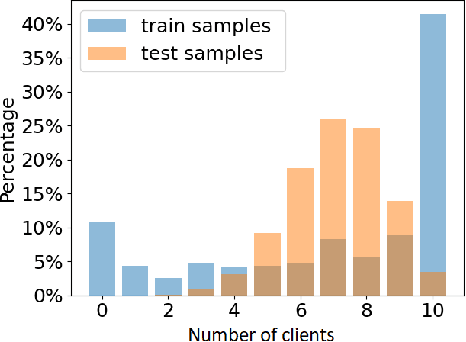
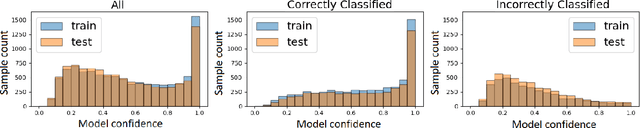
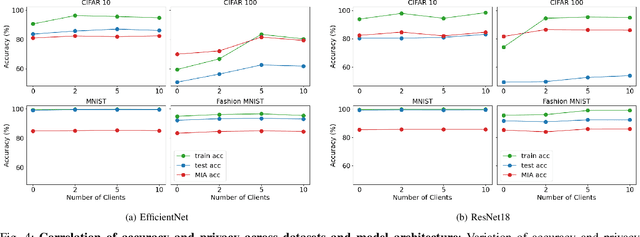
Over the last few years, federated learning (FL) has emerged as a prominent method in machine learning, emphasizing privacy preservation by allowing multiple clients to collaboratively build a model while keeping their training data private. Despite this focus on privacy, FL models are susceptible to various attacks, including membership inference attacks (MIAs), posing a serious threat to data confidentiality. In a recent study, Rezaei \textit{et al.} revealed the existence of an accuracy-privacy trade-off in deep ensembles and proposed a few fusion strategies to overcome it. In this paper, we aim to explore the relationship between deep ensembles and FL. Specifically, we investigate whether confidence-based metrics derived from deep ensembles apply to FL and whether there is a trade-off between accuracy and privacy in FL with respect to MIA. Empirical investigations illustrate a lack of a non-monotonic correlation between the number of clients and the accuracy-privacy trade-off. By experimenting with different numbers of federated clients, datasets, and confidence-metric-based fusion strategies, we identify and analytically justify the clear existence of the accuracy-privacy trade-off.
Improving Intrusion Detection with Domain-Invariant Representation Learning in Latent Space
Jan 02, 2024


Domain generalization focuses on leveraging knowledge from multiple related domains with ample training data and labels to enhance inference on unseen in-distribution (IN) and out-of-distribution (OOD) domains. In our study, we introduce a two-phase representation learning technique using multi-task learning. This approach aims to cultivate a latent space from features spanning multiple domains, encompassing both native and cross-domains, to amplify generalization to IN and OOD territories. Additionally, we attempt to disentangle the latent space by minimizing the mutual information between the prior and latent space, effectively de-correlating spurious feature correlations. Collectively, the joint optimization will facilitate domain-invariant feature learning. We assess the model's efficacy across multiple cybersecurity datasets, using standard classification metrics on both unseen IN and OOD sets, and juxtapose the results with contemporary domain generalization methods.
FedBayes: A Zero-Trust Federated Learning Aggregation to Defend Against Adversarial Attacks
Dec 04, 2023Federated learning has created a decentralized method to train a machine learning model without needing direct access to client data. The main goal of a federated learning architecture is to protect the privacy of each client while still contributing to the training of the global model. However, the main advantage of privacy in federated learning is also the easiest aspect to exploit. Without being able to see the clients' data, it is difficult to determine the quality of the data. By utilizing data poisoning methods, such as backdoor or label-flipping attacks, or by sending manipulated information about their data back to the server, malicious clients are able to corrupt the global model and degrade performance across all clients within a federation. Our novel aggregation method, FedBayes, mitigates the effect of a malicious client by calculating the probabilities of a client's model weights given to the prior model's weights using Bayesian statistics. Our results show that this approach negates the effects of malicious clients and protects the overall federation.
MIA-BAD: An Approach for Enhancing Membership Inference Attack and its Mitigation with Federated Learning
Nov 28, 2023The membership inference attack (MIA) is a popular paradigm for compromising the privacy of a machine learning (ML) model. MIA exploits the natural inclination of ML models to overfit upon the training data. MIAs are trained to distinguish between training and testing prediction confidence to infer membership information. Federated Learning (FL) is a privacy-preserving ML paradigm that enables multiple clients to train a unified model without disclosing their private data. In this paper, we propose an enhanced Membership Inference Attack with the Batch-wise generated Attack Dataset (MIA-BAD), a modification to the MIA approach. We investigate that the MIA is more accurate when the attack dataset is generated batch-wise. This quantitatively decreases the attack dataset while qualitatively improving it. We show how training an ML model through FL, has some distinct advantages and investigate how the threat introduced with the proposed MIA-BAD approach can be mitigated with FL approaches. Finally, we demonstrate the qualitative effects of the proposed MIA-BAD methodology by conducting extensive experiments with various target datasets, variable numbers of federated clients, and training batch sizes.
A Novel Approach To User Agent String Parsing For Vulnerability Analysis Using Mutli-Headed Attention
Jun 06, 2023



The increasing reliance on the internet has led to the proliferation of a diverse set of web-browsers and operating systems (OSs) capable of browsing the web. User agent strings (UASs) are a component of web browsing that are transmitted with every Hypertext Transfer Protocol (HTTP) request. They contain information about the client device and software, which is used by web servers for various purposes such as content negotiation and security. However, due to the proliferation of various browsers and devices, parsing UASs is a non-trivial task due to a lack of standardization of UAS formats. Current rules-based approaches are often brittle and can fail when encountering such non-standard formats. In this work, a novel methodology for parsing UASs using Multi-Headed Attention Based transformers is proposed. The proposed methodology exhibits strong performance in parsing a variety of UASs with differing formats. Furthermore, a framework to utilize parsed UASs to estimate the vulnerability scores for large sections of publicly visible IT networks or regions is also discussed. The methodology present here can also be easily extended or deployed for real-time parsing of logs in enterprise settings.
Thistle: A Vector Database in Rust
Mar 25, 2023We present Thistle, a fully functional vector database. Thistle is an entry into the domain of latent knowledge use in answering search queries, an ongoing research topic at both start-ups and search engine companies. We implement Thistle with several well-known algorithms, and benchmark results on the MS MARCO dataset. Results help clarify the latent knowledge domain as well as the growing Rust ML ecosystem.
Zero Day Threat Detection Using Metric Learning Autoencoders
Nov 01, 2022The proliferation of zero-day threats (ZDTs) to companies' networks has been immensely costly and requires novel methods to scan traffic for malicious behavior at massive scale. The diverse nature of normal behavior along with the huge landscape of attack types makes deep learning methods an attractive option for their ability to capture highly-nonlinear behavior patterns. In this paper, the authors demonstrate an improvement upon a previously introduced methodology, which used a dual-autoencoder approach to identify ZDTs in network flow telemetry. In addition to the previously-introduced asset-level graph features, which help abstractly represent the role of a host in its network, this new model uses metric learning to train the second autoencoder on labeled attack data. This not only produces stronger performance, but it has the added advantage of improving the interpretability of the model by allowing for multiclass classification in the latent space. This can potentially save human threat hunters time when they investigate predicted ZDTs by showing them which known attack classes were nearby in the latent space. The models presented here are also trained and evaluated with two more datasets, and continue to show promising results even when generalizing to new network topologies.