 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccuracy-Privacy Trade-off in the Mitigation of Membership Inference Attack in Federated Learning
Jul 26, 2024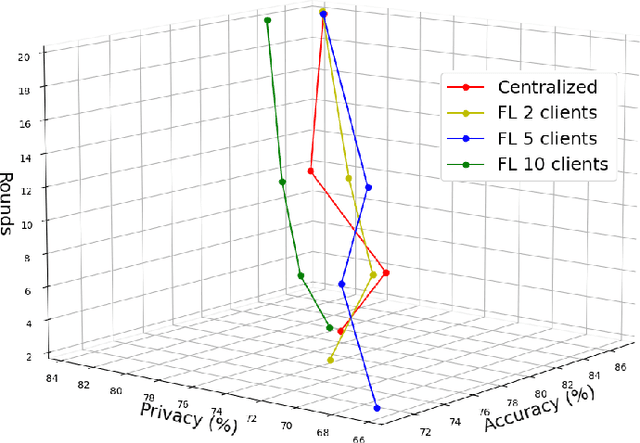
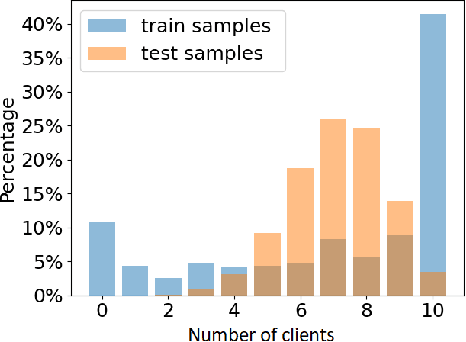
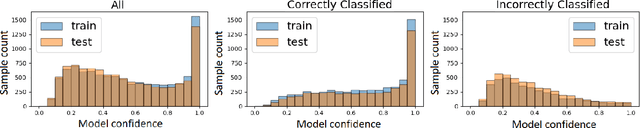
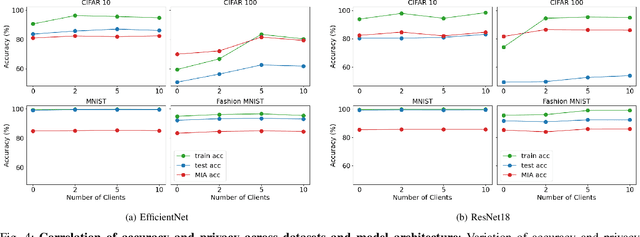
Over the last few years, federated learning (FL) has emerged as a prominent method in machine learning, emphasizing privacy preservation by allowing multiple clients to collaboratively build a model while keeping their training data private. Despite this focus on privacy, FL models are susceptible to various attacks, including membership inference attacks (MIAs), posing a serious threat to data confidentiality. In a recent study, Rezaei \textit{et al.} revealed the existence of an accuracy-privacy trade-off in deep ensembles and proposed a few fusion strategies to overcome it. In this paper, we aim to explore the relationship between deep ensembles and FL. Specifically, we investigate whether confidence-based metrics derived from deep ensembles apply to FL and whether there is a trade-off between accuracy and privacy in FL with respect to MIA. Empirical investigations illustrate a lack of a non-monotonic correlation between the number of clients and the accuracy-privacy trade-off. By experimenting with different numbers of federated clients, datasets, and confidence-metric-based fusion strategies, we identify and analytically justify the clear existence of the accuracy-privacy trade-off.
FedBayes: A Zero-Trust Federated Learning Aggregation to Defend Against Adversarial Attacks
Dec 04, 2023Federated learning has created a decentralized method to train a machine learning model without needing direct access to client data. The main goal of a federated learning architecture is to protect the privacy of each client while still contributing to the training of the global model. However, the main advantage of privacy in federated learning is also the easiest aspect to exploit. Without being able to see the clients' data, it is difficult to determine the quality of the data. By utilizing data poisoning methods, such as backdoor or label-flipping attacks, or by sending manipulated information about their data back to the server, malicious clients are able to corrupt the global model and degrade performance across all clients within a federation. Our novel aggregation method, FedBayes, mitigates the effect of a malicious client by calculating the probabilities of a client's model weights given to the prior model's weights using Bayesian statistics. Our results show that this approach negates the effects of malicious clients and protects the overall federation.
MIA-BAD: An Approach for Enhancing Membership Inference Attack and its Mitigation with Federated Learning
Nov 28, 2023The membership inference attack (MIA) is a popular paradigm for compromising the privacy of a machine learning (ML) model. MIA exploits the natural inclination of ML models to overfit upon the training data. MIAs are trained to distinguish between training and testing prediction confidence to infer membership information. Federated Learning (FL) is a privacy-preserving ML paradigm that enables multiple clients to train a unified model without disclosing their private data. In this paper, we propose an enhanced Membership Inference Attack with the Batch-wise generated Attack Dataset (MIA-BAD), a modification to the MIA approach. We investigate that the MIA is more accurate when the attack dataset is generated batch-wise. This quantitatively decreases the attack dataset while qualitatively improving it. We show how training an ML model through FL, has some distinct advantages and investigate how the threat introduced with the proposed MIA-BAD approach can be mitigated with FL approaches. Finally, we demonstrate the qualitative effects of the proposed MIA-BAD methodology by conducting extensive experiments with various target datasets, variable numbers of federated clients, and training batch sizes.