 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Novel Quality Diversity Methods For Generalization in Reinforcement Learning
Mar 26, 2023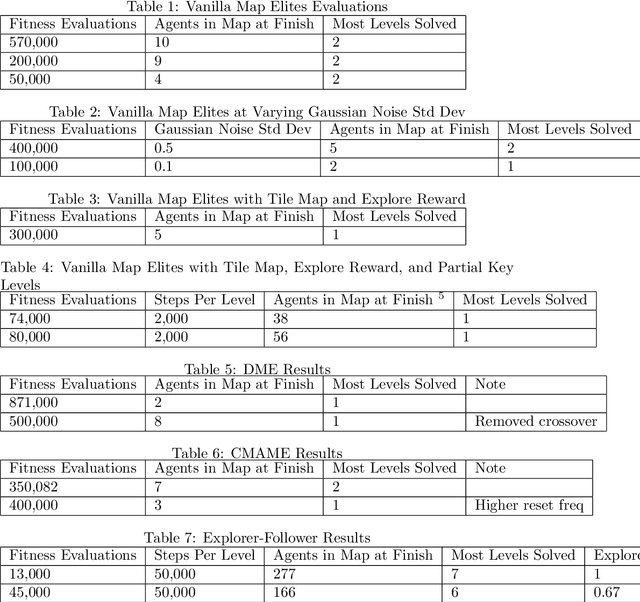
The Reinforcement Learning field is strong on achievements and weak on reapplication; a computer playing GO at a super-human level is still terrible at Tic-Tac-Toe. This paper asks whether the method of training networks improves their generalization. Specifically we explore core quality diversity algorithms, compare against two recent algorithms, and propose a new algorithm to deal with shortcomings in existing methods. Although results of these methods are well below the performance hoped for, our work raises important points about the choice of behavior criterion in quality diversity, the interaction of differential and evolutionary training methods, and the role of offline reinforcement learning and randomized learning in evolutionary search.
SASS: Data and Methods for Subject Aware Sentence Simplification
Mar 26, 2023
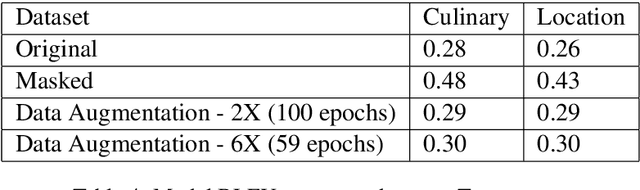

Sentence simplification tends to focus on the generic simplification of sentences by making them more readable and easier to understand. This paper provides a dataset aimed at training models that perform subject aware sentence simplifications rather than simplifying sentences as a whole. We also test models on that dataset which are inspired by model architecture used in abstractive summarization. We hand generated portions of the data and augment the dataset by further manipulating those hand written simplifications. Our results show that data-augmentation, data-masking, and model architecture choices used in summarization provide a solid baseline for comparison on subject aware simplification.
Thistle: A Vector Database in Rust
Mar 25, 2023We present Thistle, a fully functional vector database. Thistle is an entry into the domain of latent knowledge use in answering search queries, an ongoing research topic at both start-ups and search engine companies. We implement Thistle with several well-known algorithms, and benchmark results on the MS MARCO dataset. Results help clarify the latent knowledge domain as well as the growing Rust ML ecosystem.
Causality and Batch Reinforcement Learning: Complementary Approaches To Planning In Unknown Domains
Jun 03, 2020

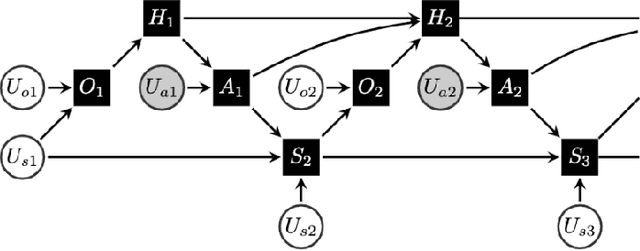
Reinforcement learning algorithms have had tremendous successes in online learning settings. However, these successes have relied on low-stakes interactions between the algorithmic agent and its environment. In many settings where RL could be of use, such as health care and autonomous driving, the mistakes made by most online RL algorithms during early training come with unacceptable costs. These settings require developing reinforcement learning algorithms that can operate in the so-called batch setting, where the algorithms must learn from set of data that is fixed, finite, and generated from some (possibly unknown) policy. Evaluating policies different from the one that collected the data is called off-policy evaluation, and naturally poses counter-factual questions. In this project we show how off-policy evaluation and the estimation of treatment effects in causal inference are two approaches to the same problem, and compare recent progress in these two areas.