 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Novel Quality Diversity Methods For Generalization in Reinforcement Learning
Paper and Code
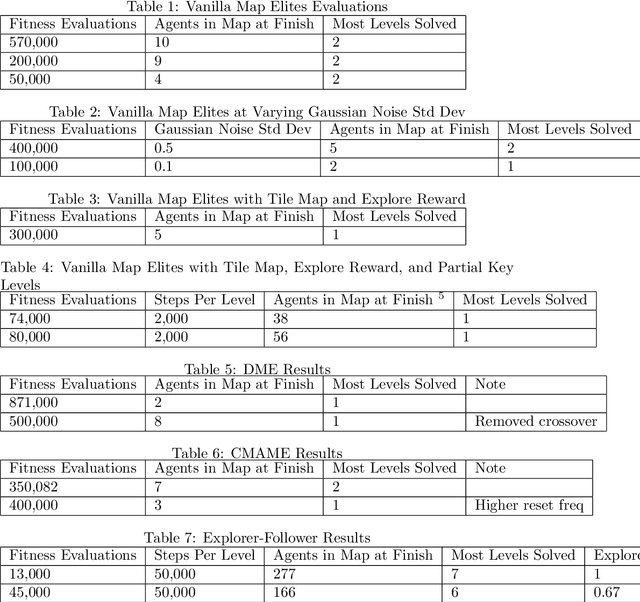
The Reinforcement Learning field is strong on achievements and weak on reapplication; a computer playing GO at a super-human level is still terrible at Tic-Tac-Toe. This paper asks whether the method of training networks improves their generalization. Specifically we explore core quality diversity algorithms, compare against two recent algorithms, and propose a new algorithm to deal with shortcomings in existing methods. Although results of these methods are well below the performance hoped for, our work raises important points about the choice of behavior criterion in quality diversity, the interaction of differential and evolutionary training methods, and the role of offline reinforcement learning and randomized learning in evolutionary search.