 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCausality and Batch Reinforcement Learning: Complementary Approaches To Planning In Unknown Domains
Paper and Code
Jun 03, 2020

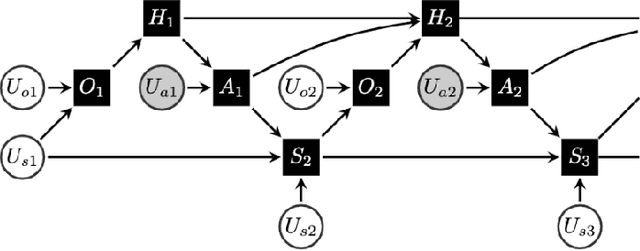
Reinforcement learning algorithms have had tremendous successes in online learning settings. However, these successes have relied on low-stakes interactions between the algorithmic agent and its environment. In many settings where RL could be of use, such as health care and autonomous driving, the mistakes made by most online RL algorithms during early training come with unacceptable costs. These settings require developing reinforcement learning algorithms that can operate in the so-called batch setting, where the algorithms must learn from set of data that is fixed, finite, and generated from some (possibly unknown) policy. Evaluating policies different from the one that collected the data is called off-policy evaluation, and naturally poses counter-factual questions. In this project we show how off-policy evaluation and the estimation of treatment effects in causal inference are two approaches to the same problem, and compare recent progress in these two areas.