 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-generated Text Detection: A Multifaceted Approach to Binary and Multiclass Classification
May 15, 2025Large Language Models (LLMs) have demonstrated remarkable capabilities in generating text that closely resembles human writing across a wide range of styles and genres. However, such capabilities are prone to potential misuse, such as fake news generation, spam email creation, and misuse in academic assignments. As a result, accurate detection of AI-generated text and identification of the model that generated it are crucial for maintaining the responsible use of LLMs. In this work, we addressed two sub-tasks put forward by the Defactify workshop under AI-Generated Text Detection shared task at the Association for the Advancement of Artificial Intelligence (AAAI 2025): Task A involved distinguishing between human-authored or AI-generated text, while Task B focused on attributing text to its originating language model. For each task, we proposed two neural architectures: an optimized model and a simpler variant. For Task A, the optimized neural architecture achieved fifth place with $F1$ score of 0.994, and for Task B, the simpler neural architecture also ranked fifth place with $F1$ score of 0.627.
A Simple yet Efficient Ensemble Approach for AI-generated Text Detection
Nov 08, 2023Recent Large Language Models (LLMs) have demonstrated remarkable capabilities in generating text that closely resembles human writing across wide range of styles and genres. However, such capabilities are prone to potential abuse, such as fake news generation, spam email creation, and misuse in academic assignments. Hence, it is essential to build automated approaches capable of distinguishing between artificially generated text and human-authored text. In this paper, we propose a simple yet efficient solution to this problem by ensembling predictions from multiple constituent LLMs. Compared to previous state-of-the-art approaches, which are perplexity-based or uses ensembles with a number of LLMs, our condensed ensembling approach uses only two constituent LLMs to achieve comparable performance. Experiments conducted on four benchmark datasets for generative text classification show performance improvements in the range of 0.5 to 100\% compared to previous state-of-the-art approaches. We also study the influence that the training data from individual LLMs have on model performance. We found that substituting commercially-restrictive Generative Pre-trained Transformer (GPT) data with data generated from other open language models such as Falcon, Large Language Model Meta AI (LLaMA2), and Mosaic Pretrained Transformers (MPT) is a feasible alternative when developing generative text detectors. Furthermore, to demonstrate zero-shot generalization, we experimented with an English essays dataset, and results suggest that our ensembling approach can handle new data effectively.
A Closer Look at Bearing Fault Classification Approaches
Sep 29, 2023



Rolling bearing fault diagnosis has garnered increased attention in recent years owing to its presence in rotating machinery across various industries, and an ever increasing demand for efficient operations. Prompt detection and accurate prediction of bearing failures can help reduce the likelihood of unexpected machine downtime and enhance maintenance schedules, averting lost productivity. Recent technological advances have enabled monitoring the health of these assets at scale using a variety of sensors, and predicting the failures using modern Machine Learning (ML) approaches including deep learning architectures. Vibration data has been collected using accelerated run-to-failure of overloaded bearings, or by introducing known failure in bearings, under a variety of operating conditions such as rotating speed, load on the bearing, type of bearing fault, and data acquisition frequency. However, in the development of bearing failure classification models using vibration data there is a lack of consensus in the metrics used to evaluate the models, data partitions used to evaluate models, and methods used to generate failure labels in run-to-failure experiments. An understanding of the impact of these choices is important to reliably develop models, and deploy them in practical settings. In this work, we demonstrate the significance of these choices on the performance of the models using publicly-available vibration datasets, and suggest model development considerations for real world scenarios. Our experimental findings demonstrate that assigning vibration data from a given bearing across training and evaluation splits leads to over-optimistic performance estimates, PCA-based approach is able to robustly generate labels for failure classification in run-to-failure experiments, and $F$ scores are more insightful to evaluate the models with unbalanced real-world failure data.
Generative AI Text Classification using Ensemble LLM Approaches
Sep 14, 2023Large Language Models (LLMs) have shown impressive performance across a variety of Artificial Intelligence (AI) and natural language processing tasks, such as content creation, report generation, etc. However, unregulated malign application of these models can create undesirable consequences such as generation of fake news, plagiarism, etc. As a result, accurate detection of AI-generated language can be crucial in responsible usage of LLMs. In this work, we explore 1) whether a certain body of text is AI generated or written by human, and 2) attribution of a specific language model in generating a body of text. Texts in both English and Spanish are considered. The datasets used in this study are provided as part of the Automated Text Identification (AuTexTification) shared task. For each of the research objectives stated above, we propose an ensemble neural model that generates probabilities from different pre-trained LLMs which are used as features to a Traditional Machine Learning (TML) classifier following it. For the first task of distinguishing between AI and human generated text, our model ranked in fifth and thirteenth place (with macro $F1$ scores of 0.733 and 0.649) for English and Spanish texts, respectively. For the second task on model attribution, our model ranked in first place with macro $F1$ scores of 0.625 and 0.653 for English and Spanish texts, respectively.
Multi-label Categorization of Accounts of Sexism using a Neural Framework
Nov 18, 2019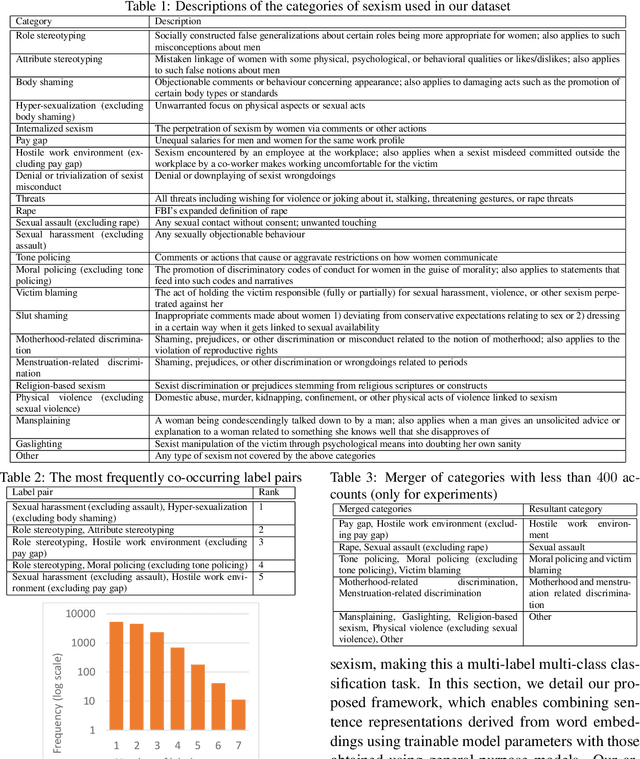
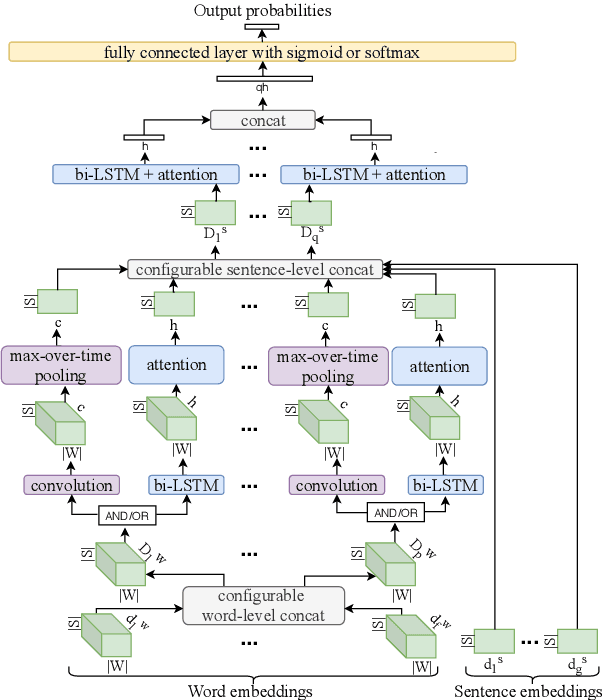


Sexism, an injustice that subjects women and girls to enormous suffering, manifests in blatant as well as subtle ways. In the wake of growing documentation of experiences of sexism on the web, the automatic categorization of accounts of sexism has the potential to assist social scientists and policy makers in studying and countering sexism better. The existing work on sexism classification, which is different from sexism detection, has certain limitations in terms of the categories of sexism used and/or whether they can co-occur. To the best of our knowledge, this is the first work on the multi-label classification of sexism of any kind(s), and we contribute the largest dataset for sexism categorization. We develop a neural solution for this multi-label classification that can combine sentence representations obtained using models such as BERT with distributional and linguistic word embeddings using a flexible, hierarchical architecture involving recurrent components and optional convolutional ones. Further, we leverage unlabeled accounts of sexism to infuse domain-specific elements into our framework. The best proposed method outperforms several deep learning as well as traditional machine learning baselines by an appreciable margin.