 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-free Post-hoc Explainability Using Distillation Aided Learnable Approach
Sep 17, 2024



The recent advancements in artificial intelligence (AI), with the release of several large models having only query access, make a strong case for explainability of deep models in a post-hoc gradient free manner. In this paper, we propose a framework, named distillation aided explainability (DAX), that attempts to generate a saliency-based explanation in a model agnostic gradient free application. The DAX approach poses the problem of explanation in a learnable setting with a mask generation network and a distillation network. The mask generation network learns to generate the multiplier mask that finds the salient regions of the input, while the student distillation network aims to approximate the local behavior of the black-box model. We propose a joint optimization of the two networks in the DAX framework using the locally perturbed input samples, with the targets derived from input-output access to the black-box model. We extensively evaluate DAX across different modalities (image and audio), in a classification setting, using a diverse set of evaluations (intersection over union with ground truth, deletion based and subjective human evaluation based measures) and benchmark it with respect to $9$ different methods. In these evaluations, the DAX significantly outperforms the existing approaches on all modalities and evaluation metrics.
A Closer Look at Bearing Fault Classification Approaches
Sep 29, 2023



Rolling bearing fault diagnosis has garnered increased attention in recent years owing to its presence in rotating machinery across various industries, and an ever increasing demand for efficient operations. Prompt detection and accurate prediction of bearing failures can help reduce the likelihood of unexpected machine downtime and enhance maintenance schedules, averting lost productivity. Recent technological advances have enabled monitoring the health of these assets at scale using a variety of sensors, and predicting the failures using modern Machine Learning (ML) approaches including deep learning architectures. Vibration data has been collected using accelerated run-to-failure of overloaded bearings, or by introducing known failure in bearings, under a variety of operating conditions such as rotating speed, load on the bearing, type of bearing fault, and data acquisition frequency. However, in the development of bearing failure classification models using vibration data there is a lack of consensus in the metrics used to evaluate the models, data partitions used to evaluate models, and methods used to generate failure labels in run-to-failure experiments. An understanding of the impact of these choices is important to reliably develop models, and deploy them in practical settings. In this work, we demonstrate the significance of these choices on the performance of the models using publicly-available vibration datasets, and suggest model development considerations for real world scenarios. Our experimental findings demonstrate that assigning vibration data from a given bearing across training and evaluation splits leads to over-optimistic performance estimates, PCA-based approach is able to robustly generate labels for failure classification in run-to-failure experiments, and $F$ scores are more insightful to evaluate the models with unbalanced real-world failure data.
Interpretable Acoustic Representation Learning on Breathing and Speech Signals for COVID-19 Detection
Jun 27, 2022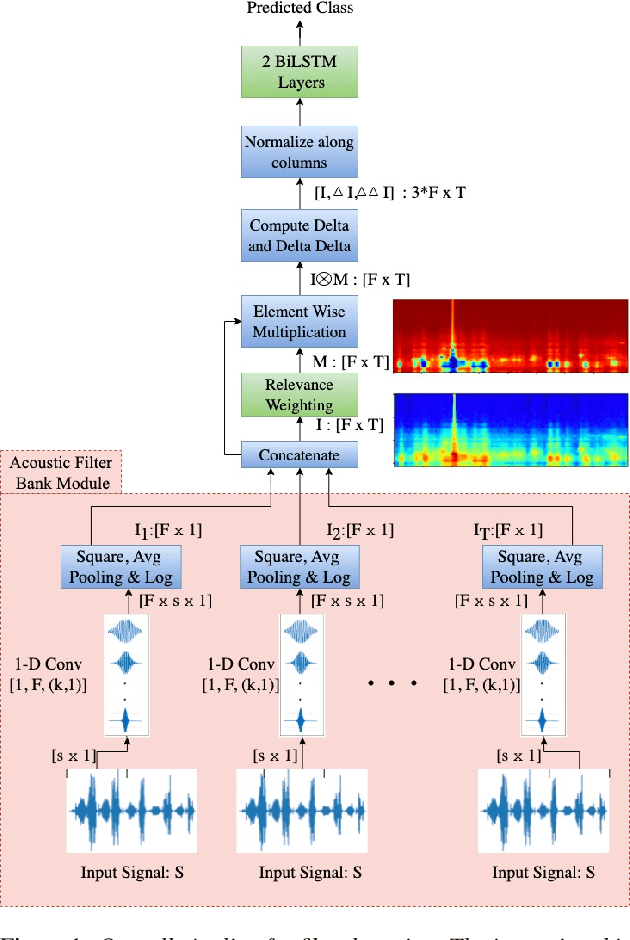
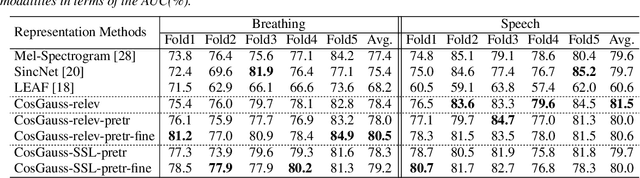
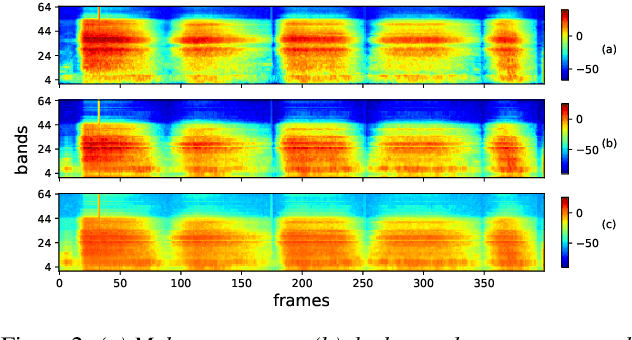
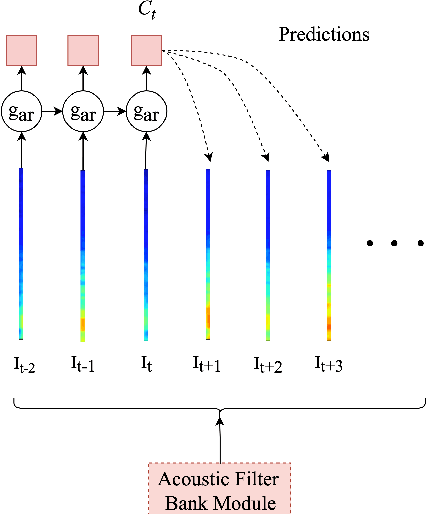
In this paper, we describe an approach for representation learning of audio signals for the task of COVID-19 detection. The raw audio samples are processed with a bank of 1-D convolutional filters that are parameterized as cosine modulated Gaussian functions. The choice of these kernels allows the interpretation of the filterbanks as smooth band-pass filters. The filtered outputs are pooled, log-compressed and used in a self-attention based relevance weighting mechanism. The relevance weighting emphasizes the key regions of the time-frequency decomposition that are important for the downstream task. The subsequent layers of the model consist of a recurrent architecture and the models are trained for a COVID-19 detection task. In our experiments on the Coswara data set, we show that the proposed model achieves significant performance improvements over the baseline system as well as other representation learning approaches. Further, the approach proposed is shown to be uniformly applicable for speech and breathing signals and for transfer learning from a larger data set.
Svadhyaya system for the Second Diagnosing COVID-19 using Acoustics Challenge 2021
Jun 11, 2022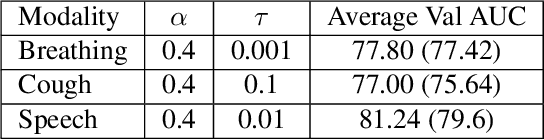
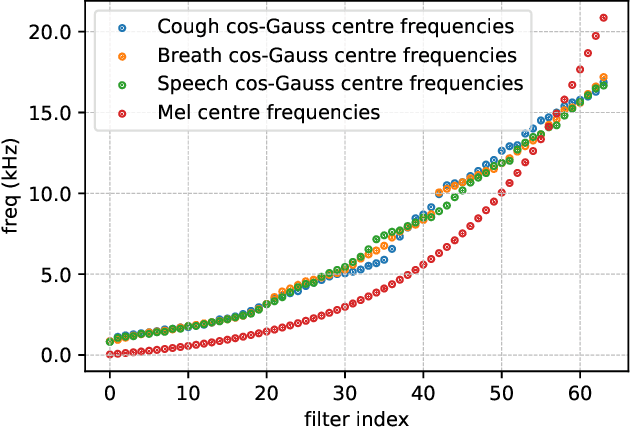

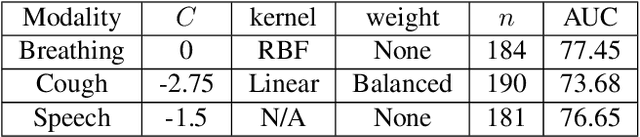
This report describes the system used for detecting COVID-19 positives using three different acoustic modalities, namely speech, breathing, and cough in the second DiCOVA challenge. The proposed system is based on the combination of 4 different approaches, each focusing more on one aspect of the problem, and reaches the blind test AUCs of 86.41, 77.60, and 84.55, in the breathing, cough, and speech tracks, respectively, and the AUC of 85.37 in the fusion of these three tracks.
SpliceOut: A Simple and Efficient Audio Augmentation Method
Oct 13, 2021
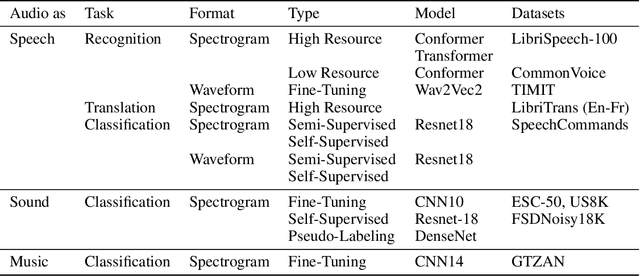
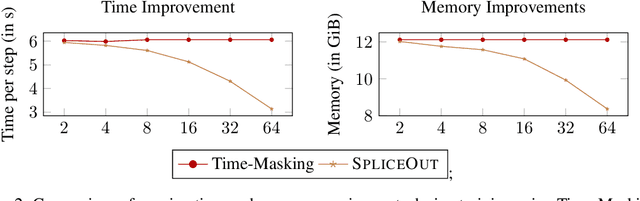
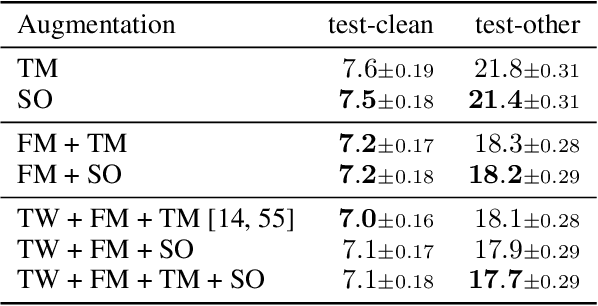
Time masking has become a de facto augmentation technique for speech and audio tasks, including automatic speech recognition (ASR) and audio classification, most notably as a part of SpecAugment. In this work, we propose SpliceOut, a simple modification to time masking which makes it computationally more efficient. SpliceOut performs comparably to (and sometimes outperforms) SpecAugment on a wide variety of speech and audio tasks, including ASR for seven different languages using varying amounts of training data, as well as on speech translation, sound and music classification, thus establishing itself as a broadly applicable audio augmentation method. SpliceOut also provides additional gains when used in conjunction with other augmentation techniques. Apart from the fully-supervised setting, we also demonstrate that SpliceOut can complement unsupervised representation learning with performance gains in the semi-supervised and self-supervised settings.
ProAlignNet : Unsupervised Learning for Progressively Aligning Noisy Contours
May 23, 2020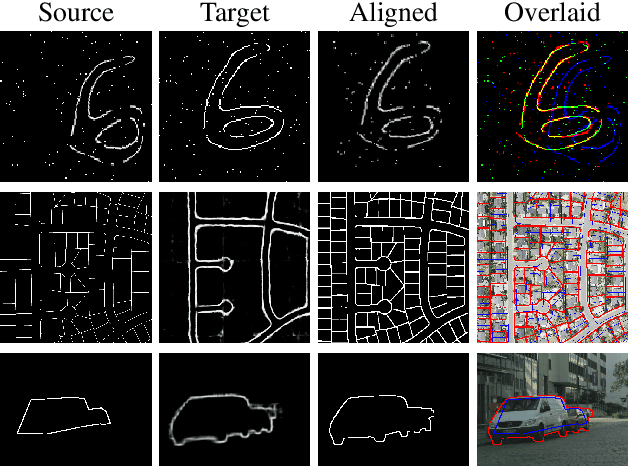
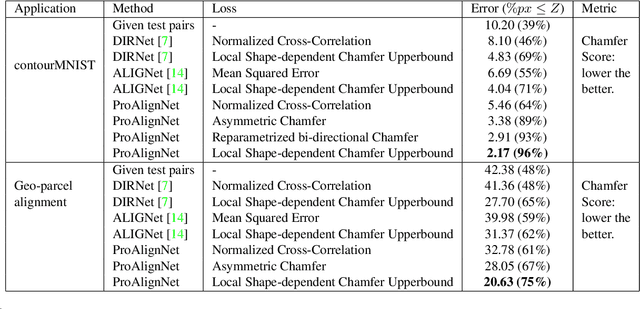
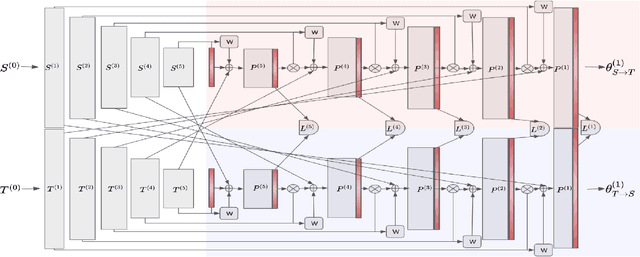
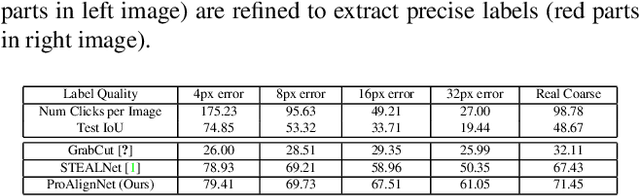
Contour shape alignment is a fundamental but challenging problem in computer vision, especially when the observations are partial, noisy, and largely misaligned. Recent ConvNet-based architectures that were proposed to align image structures tend to fail with contour representation of shapes, mostly due to the use of proximity-insensitive pixel-wise similarity measures as loss functions in their training processes. This work presents a novel ConvNet, "ProAlignNet" that accounts for large scale misalignments and complex transformations between the contour shapes. It infers the warp parameters in a multi-scale fashion with progressively increasing complex transformations over increasing scales. It learns --without supervision-- to align contours, agnostic to noise and missing parts, by training with a novel loss function which is derived an upperbound of a proximity-sensitive and local shape-dependent similarity metric that uses classical Morphological Chamfer Distance Transform. We evaluate the reliability of these proposals on a simulated MNIST noisy contours dataset via some basic sanity check experiments. Next, we demonstrate the effectiveness of the proposed models in two real-world applications of (i) aligning geo-parcel data to aerial image maps and (ii) refining coarsely annotated segmentation labels. In both applications, the proposed models consistently perform superior to state-of-the-art methods.
Studying the Plasticity in Deep Convolutional Neural Networks using Random Pruning
Dec 26, 2018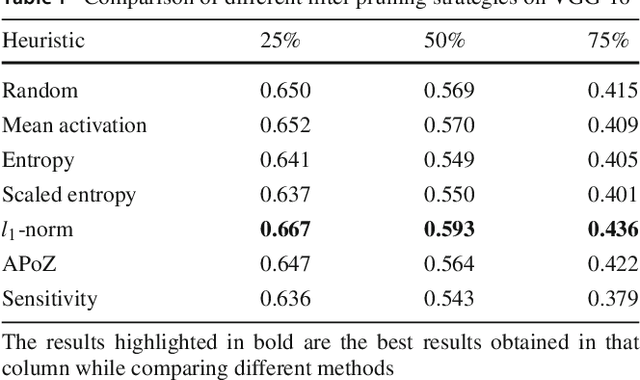
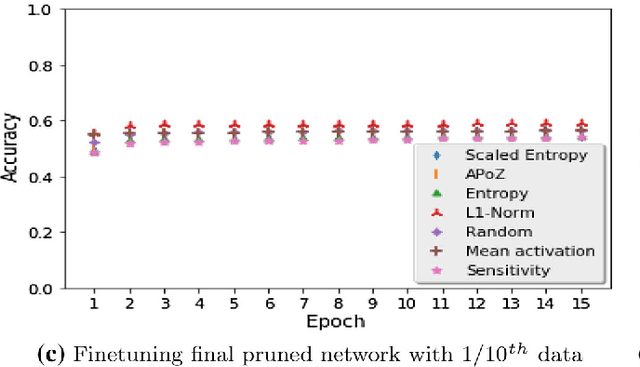
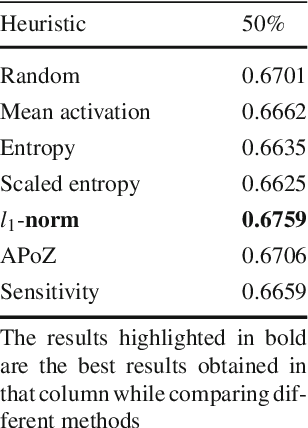
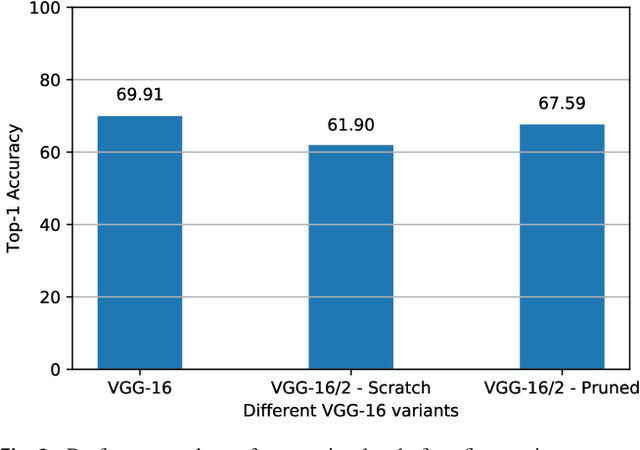
Recently there has been a lot of work on pruning filters from deep convolutional neural networks (CNNs) with the intention of reducing computations.The key idea is to rank the filters based on a certain criterion (say, l1-norm) and retain only the top ranked filters. Once the low scoring filters are pruned away the remainder of the network is fine tuned and is shown to give performance comparable to the original unpruned network. In this work, we report experiments which suggest that the comparable performance of the pruned network is not due to the specific criterion chosen but due to the inherent plasticity of deep neural networks which allows them to recover from the loss of pruned filters once the rest of the filters are fine-tuned. Specifically we show counter-intuitive results wherein by randomly pruning 25-50% filters from deep CNNs we are able to obtain the same performance as obtained by using state-of-the-art pruning methods. We empirically validate our claims by doing an exhaustive evaluation with VGG-16 and ResNet-50. We also evaluate a real world scenario where a CNN trained on all 1000 ImageNet classes needs to be tested on only a small set of classes at test time (say, only animals). We create a new benchmark dataset from ImageNet to evaluate such class specific pruning and show that even here a random pruning strategy gives close to state-of-the-art performance. Unlike existing approaches which mainly focus on the task of image classification, in this work we also report results on object detection and image segmentation. We show that using a simple random pruning strategy we can achieve significant speed up in object detection (74% improvement in fps) while retaining the same accuracy as that of the original Faster RCNN model. Similarly we show that the performance of a pruned Segmentation Network (SegNet) is actually very similar to that of the original unpruned SegNet.
Recovering from Random Pruning: On the Plasticity of Deep Convolutional Neural Networks
Jan 31, 2018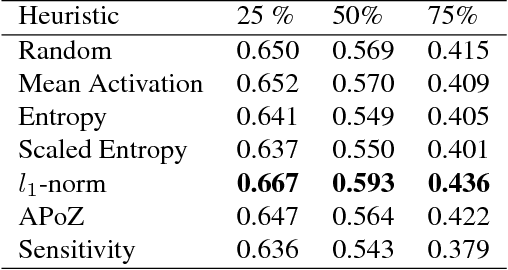
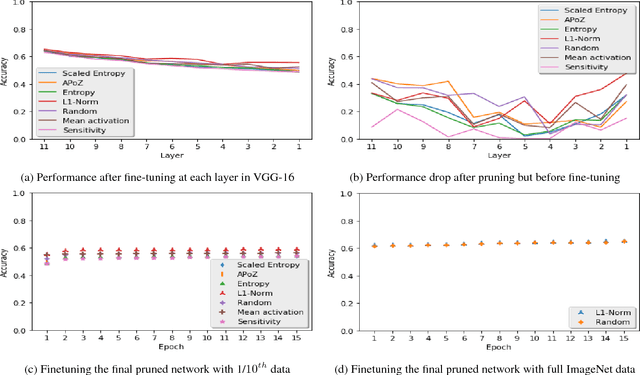
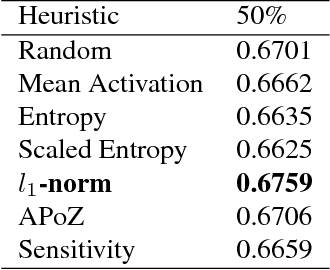
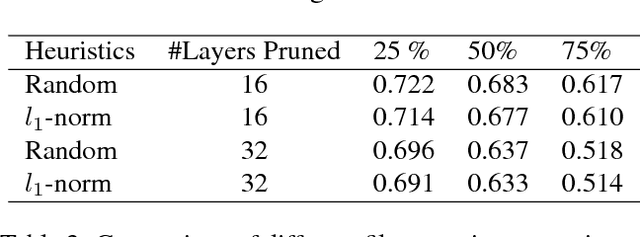
Recently there has been a lot of work on pruning filters from deep convolutional neural networks (CNNs) with the intention of reducing computations. The key idea is to rank the filters based on a certain criterion (say, $l_1$-norm, average percentage of zeros, etc) and retain only the top ranked filters. Once the low scoring filters are pruned away the remainder of the network is fine tuned and is shown to give performance comparable to the original unpruned network. In this work, we report experiments which suggest that the comparable performance of the pruned network is not due to the specific criterion chosen but due to the inherent plasticity of deep neural networks which allows them to recover from the loss of pruned filters once the rest of the filters are fine-tuned. Specifically, we show counter-intuitive results wherein by randomly pruning 25-50\% filters from deep CNNs we are able to obtain the same performance as obtained by using state of the art pruning methods. We empirically validate our claims by doing an exhaustive evaluation with VGG-16 and ResNet-50. Further, we also evaluate a real world scenario where a CNN trained on all 1000 ImageNet classes needs to be tested on only a small set of classes at test time (say, only animals). We create a new benchmark dataset from ImageNet to evaluate such class specific pruning and show that even here a random pruning strategy gives close to state of the art performance. Lastly, unlike existing approaches which mainly focus on the task of image classification, in this work we also report results on object detection. We show that using a simple random pruning strategy we can achieve significant speed up in object detection (74$\%$ improvement in fps) while retaining the same accuracy as that of the original Faster RCNN model.