 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProAlignNet : Unsupervised Learning for Progressively Aligning Noisy Contours
May 23, 2020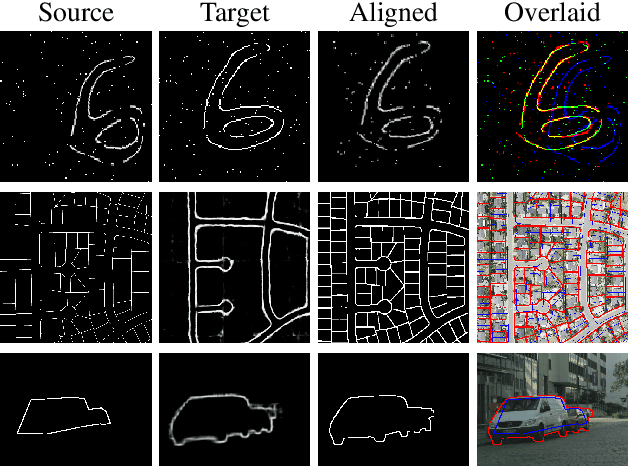
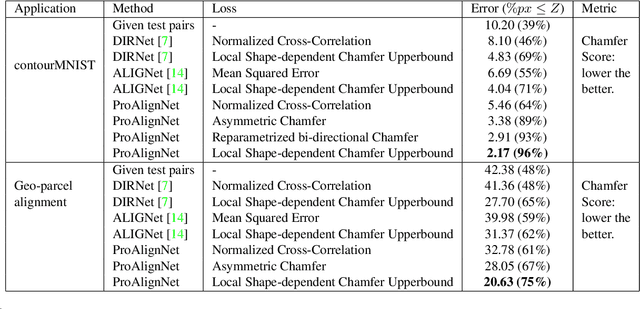
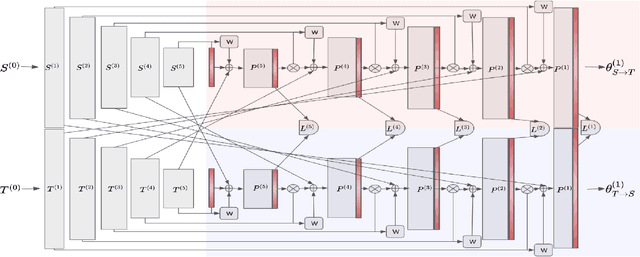
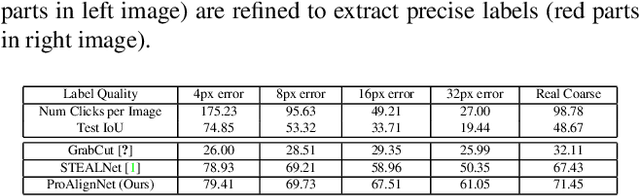
Contour shape alignment is a fundamental but challenging problem in computer vision, especially when the observations are partial, noisy, and largely misaligned. Recent ConvNet-based architectures that were proposed to align image structures tend to fail with contour representation of shapes, mostly due to the use of proximity-insensitive pixel-wise similarity measures as loss functions in their training processes. This work presents a novel ConvNet, "ProAlignNet" that accounts for large scale misalignments and complex transformations between the contour shapes. It infers the warp parameters in a multi-scale fashion with progressively increasing complex transformations over increasing scales. It learns --without supervision-- to align contours, agnostic to noise and missing parts, by training with a novel loss function which is derived an upperbound of a proximity-sensitive and local shape-dependent similarity metric that uses classical Morphological Chamfer Distance Transform. We evaluate the reliability of these proposals on a simulated MNIST noisy contours dataset via some basic sanity check experiments. Next, we demonstrate the effectiveness of the proposed models in two real-world applications of (i) aligning geo-parcel data to aerial image maps and (ii) refining coarsely annotated segmentation labels. In both applications, the proposed models consistently perform superior to state-of-the-art methods.
Wavelets to the Rescue: Improving Sample Quality of Latent Variable Deep Generative Models
Oct 26, 2019

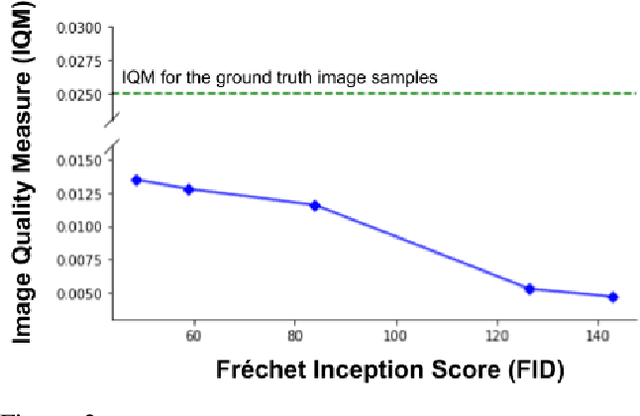
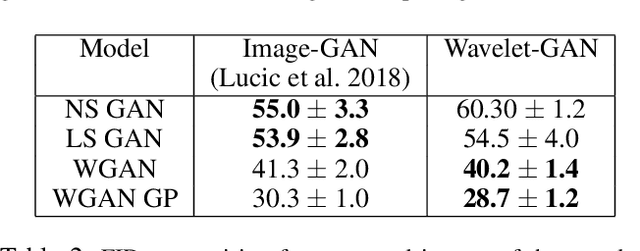
Variational Autoencoders (VAE) are probabilistic deep generative models underpinned by elegant theory, stable training processes, and meaningful manifold representations. However, they produce blurry images due to a lack of explicit emphasis over high-frequency textural details of the images, and the difficulty to directly model the complex joint probability distribution over the high-dimensional image space. In this work, we approach these two challenges with a novel wavelet space VAE that uses the decoder to model the images in the wavelet coefficient space. This enables the VAE to emphasize over high-frequency components within an image obtained via wavelet decomposition. Additionally, by decomposing the complex function of generating high-dimensional images into inverse wavelet transformation and generation of wavelet coefficients, the latter becomes simpler to model by the VAE. We empirically validate that deep generative models operating in the wavelet space can generate images of higher quality than the image (RGB) space counterparts. Quantitatively, on benchmark natural image datasets, we achieve consistently better FID scores than VAE based architectures and competitive FID scores with a variety of GAN models for the same architectural and experimental setup. Furthermore, the proposed wavelet-based generative model retains desirable attributes like disentangled and informative latent representation without losing the quality in the generated samples.