 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-free Post-hoc Explainability Using Distillation Aided Learnable Approach
Sep 17, 2024



The recent advancements in artificial intelligence (AI), with the release of several large models having only query access, make a strong case for explainability of deep models in a post-hoc gradient free manner. In this paper, we propose a framework, named distillation aided explainability (DAX), that attempts to generate a saliency-based explanation in a model agnostic gradient free application. The DAX approach poses the problem of explanation in a learnable setting with a mask generation network and a distillation network. The mask generation network learns to generate the multiplier mask that finds the salient regions of the input, while the student distillation network aims to approximate the local behavior of the black-box model. We propose a joint optimization of the two networks in the DAX framework using the locally perturbed input samples, with the targets derived from input-output access to the black-box model. We extensively evaluate DAX across different modalities (image and audio), in a classification setting, using a diverse set of evaluations (intersection over union with ground truth, deletion based and subjective human evaluation based measures) and benchmark it with respect to $9$ different methods. In these evaluations, the DAX significantly outperforms the existing approaches on all modalities and evaluation metrics.
Interpretable Acoustic Representation Learning on Breathing and Speech Signals for COVID-19 Detection
Jun 27, 2022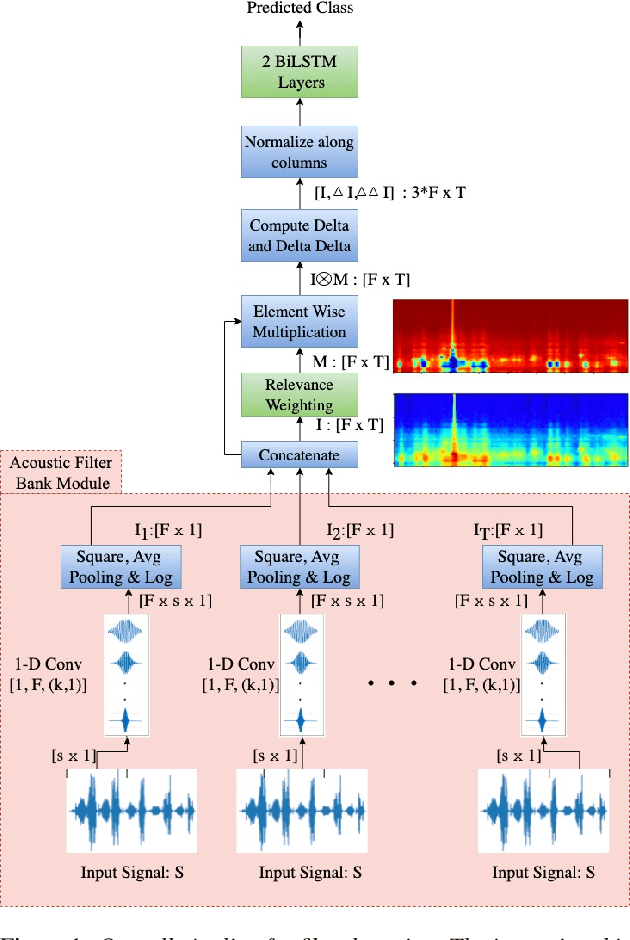
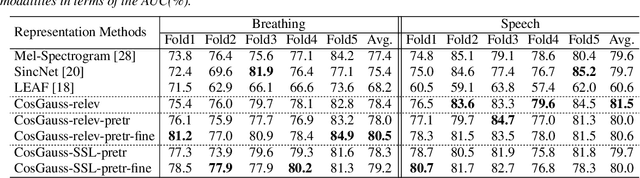
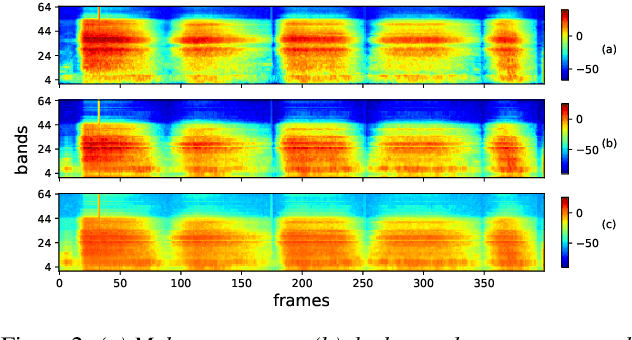
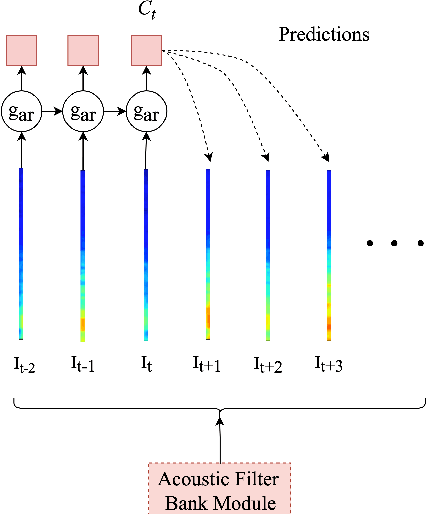
In this paper, we describe an approach for representation learning of audio signals for the task of COVID-19 detection. The raw audio samples are processed with a bank of 1-D convolutional filters that are parameterized as cosine modulated Gaussian functions. The choice of these kernels allows the interpretation of the filterbanks as smooth band-pass filters. The filtered outputs are pooled, log-compressed and used in a self-attention based relevance weighting mechanism. The relevance weighting emphasizes the key regions of the time-frequency decomposition that are important for the downstream task. The subsequent layers of the model consist of a recurrent architecture and the models are trained for a COVID-19 detection task. In our experiments on the Coswara data set, we show that the proposed model achieves significant performance improvements over the baseline system as well as other representation learning approaches. Further, the approach proposed is shown to be uniformly applicable for speech and breathing signals and for transfer learning from a larger data set.
Svadhyaya system for the Second Diagnosing COVID-19 using Acoustics Challenge 2021
Jun 11, 2022
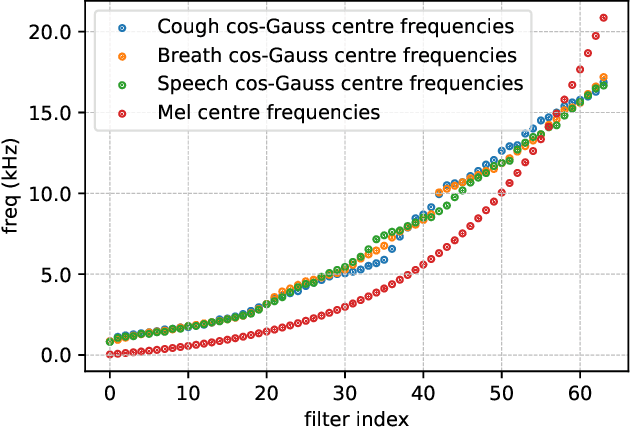

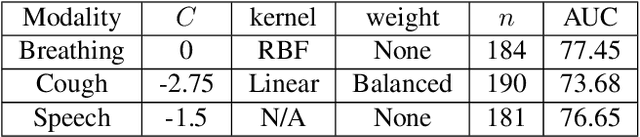
This report describes the system used for detecting COVID-19 positives using three different acoustic modalities, namely speech, breathing, and cough in the second DiCOVA challenge. The proposed system is based on the combination of 4 different approaches, each focusing more on one aspect of the problem, and reaches the blind test AUCs of 86.41, 77.60, and 84.55, in the breathing, cough, and speech tracks, respectively, and the AUC of 85.37 in the fusion of these three tracks.