 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntentGPT: Few-shot Intent Discovery with Large Language Models
Nov 16, 2024



In today's digitally driven world, dialogue systems play a pivotal role in enhancing user interactions, from customer service to virtual assistants. In these dialogues, it is important to identify user's goals automatically to resolve their needs promptly. This has necessitated the integration of models that perform Intent Detection. However, users' intents are diverse and dynamic, making it challenging to maintain a fixed set of predefined intents. As a result, a more practical approach is to develop a model capable of identifying new intents as they emerge. We address the challenge of Intent Discovery, an area that has drawn significant attention in recent research efforts. Existing methods need to train on a substantial amount of data for correctly identifying new intents, demanding significant human effort. To overcome this, we introduce IntentGPT, a novel training-free method that effectively prompts Large Language Models (LLMs) such as GPT-4 to discover new intents with minimal labeled data. IntentGPT comprises an \textit{In-Context Prompt Generator}, which generates informative prompts for In-Context Learning, an \textit{Intent Predictor} for classifying and discovering user intents from utterances, and a \textit{Semantic Few-Shot Sampler} that selects relevant few-shot examples and a set of known intents to be injected into the prompt. Our experiments show that IntentGPT outperforms previous methods that require extensive domain-specific data and fine-tuning, in popular benchmarks, including CLINC and BANKING, among others.
TK-KNN: A Balanced Distance-Based Pseudo Labeling Approach for Semi-Supervised Intent Classification
Oct 17, 2023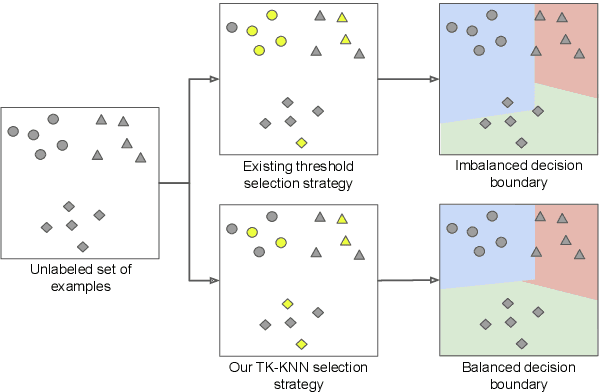
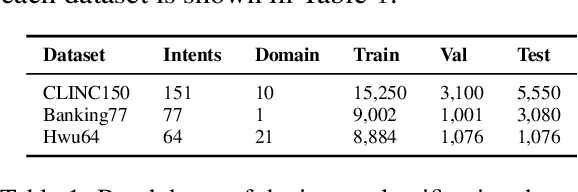
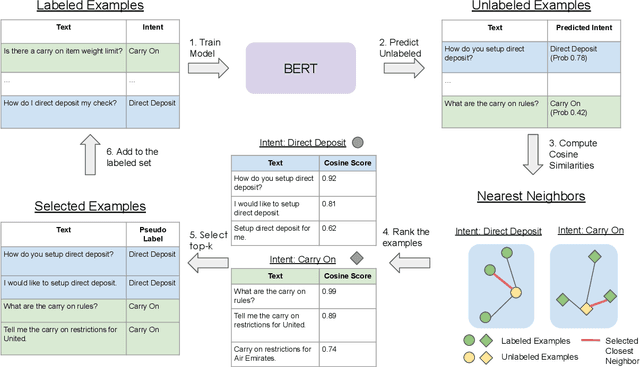
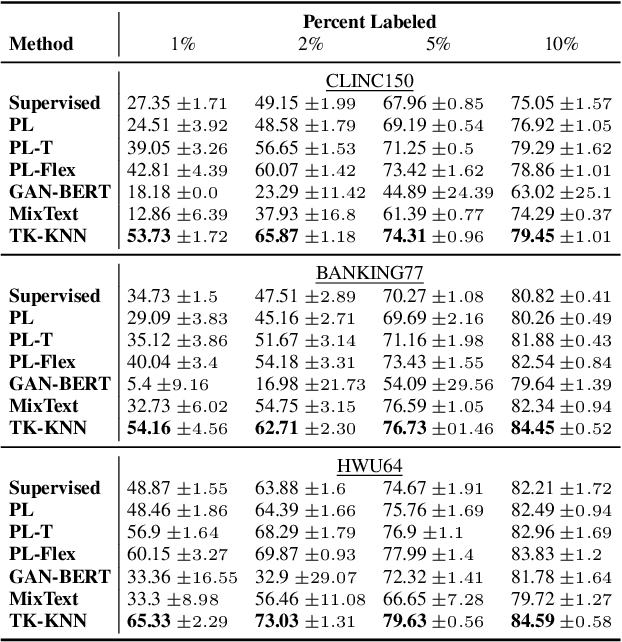
The ability to detect intent in dialogue systems has become increasingly important in modern technology. These systems often generate a large amount of unlabeled data, and manually labeling this data requires substantial human effort. Semi-supervised methods attempt to remedy this cost by using a model trained on a few labeled examples and then by assigning pseudo-labels to further a subset of unlabeled examples that has a model prediction confidence higher than a certain threshold. However, one particularly perilous consequence of these methods is the risk of picking an imbalanced set of examples across classes, which could lead to poor labels. In the present work, we describe Top-K K-Nearest Neighbor (TK-KNN), which uses a more robust pseudo-labeling approach based on distance in the embedding space while maintaining a balanced set of pseudo-labeled examples across classes through a ranking-based approach. Experiments on several datasets show that TK-KNN outperforms existing models, particularly when labeled data is scarce on popular datasets such as CLINC150 and Banking77. Code is available at https://github.com/ServiceNow/tk-knn
Posthoc Verification and the Fallibility of the Ground Truth
Jun 02, 2021
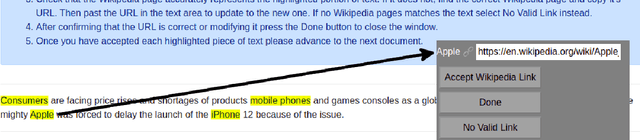
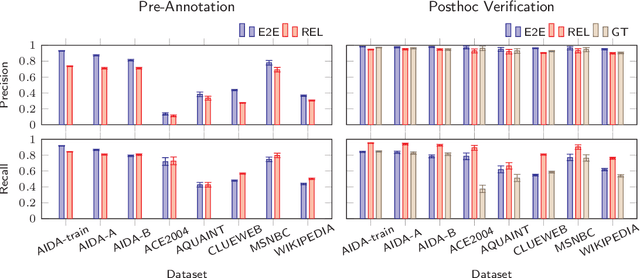
Classifiers commonly make use of pre-annotated datasets, wherein a model is evaluated by pre-defined metrics on a held-out test set typically made of human-annotated labels. Metrics used in these evaluations are tied to the availability of well-defined ground truth labels, and these metrics typically do not allow for inexact matches. These noisy ground truth labels and strict evaluation metrics may compromise the validity and realism of evaluation results. In the present work, we discuss these concerns and conduct a systematic posthoc verification experiment on the entity linking (EL) task. Unlike traditional methodologies, which asks annotators to provide free-form annotations, we ask annotators to verify the correctness of annotations after the fact (i.e., posthoc). Compared to pre-annotation evaluation, state-of-the-art EL models performed extremely well according to the posthoc evaluation methodology. Posthoc validation also permits the validation of the ground truth dataset. Surprisingly, we find predictions from EL models had a similar or higher verification rate than the ground truth. We conclude with a discussion on these findings and recommendations for future evaluations.
Reddit Entity Linking Dataset
Jan 04, 2021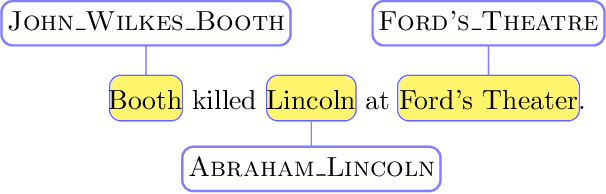
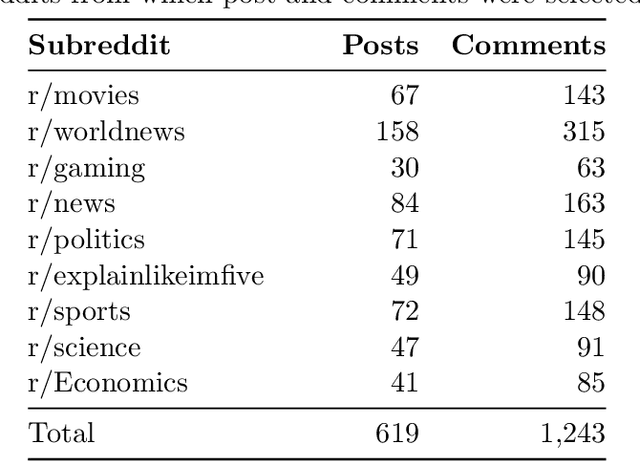

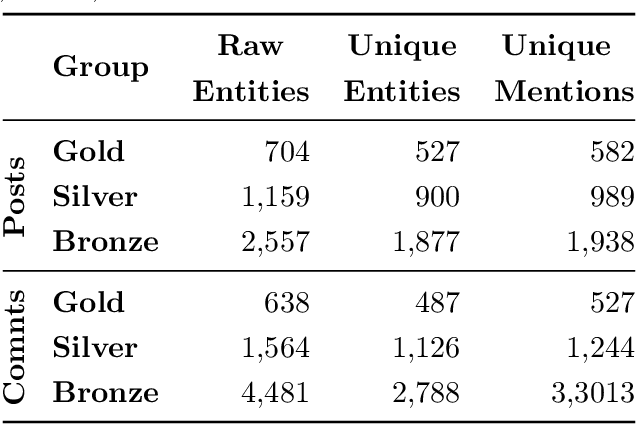
We introduce and make publicly available an entity linking dataset from Reddit that contains17,316 linked entities, each annotated by three human annotators and then grouped into Gold, Silver, and Bronze to indicate inter-annotator agreement. We analyze the different errors and disagreements made by annotators and suggest three types of corrections to the raw data. Finally, we tested existing entity linking models that are trained and tuned on text from non-social media datasets. We find that, although these existing entity linking models perform very well on their original datasets, they perform poorly on this social media dataset. We also show that the majority of these errors can be attributed to poor performance on the mention detection subtask. These results indicate the need for better entity linking models that can be applied to the enormous amount of social media text.
HetSeq: Distributed GPU Training on Heterogeneous Infrastructure
Sep 25, 2020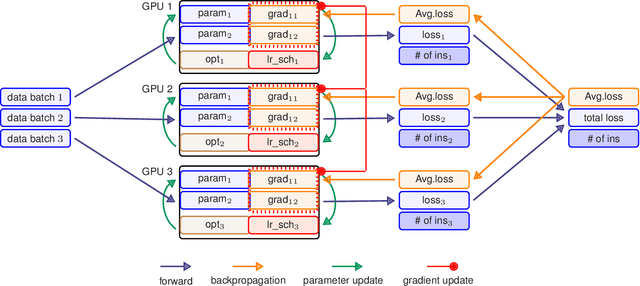
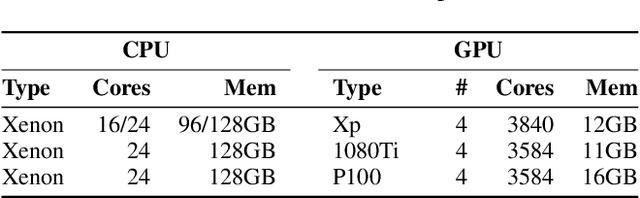
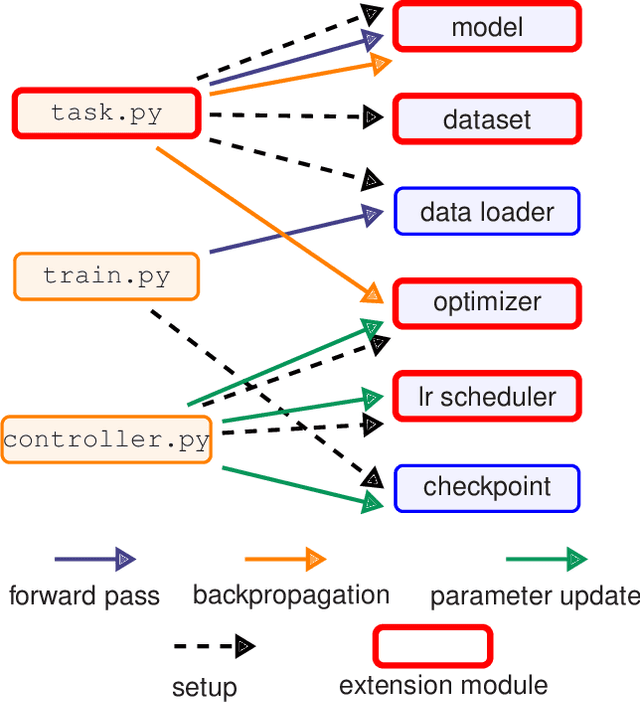

Modern deep learning systems like PyTorch and Tensorflow are able to train enormous models with billions (or trillions) of parameters on a distributed infrastructure. These systems require that the internal nodes have the same memory capacity and compute performance. Unfortunately, most organizations, especially universities, have a piecemeal approach to purchasing computer systems resulting in a heterogeneous infrastructure, which cannot be used to compute large models. The present work describes HetSeq, a software package adapted from the popular PyTorch package that provides the capability to train large neural network models on heterogeneous infrastructure. Experiments with transformer translation and BERT language model shows that HetSeq scales over heterogeneous systems. HetSeq can be easily extended to other models like image classification. Package with supported document is publicly available at https://github.com/yifding/hetseq.