 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReddit Entity Linking Dataset
Paper and Code
Jan 04, 2021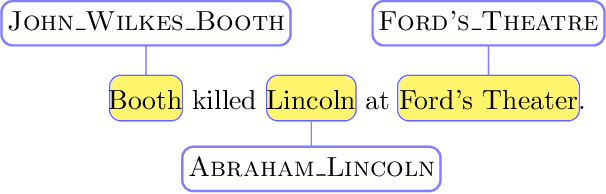
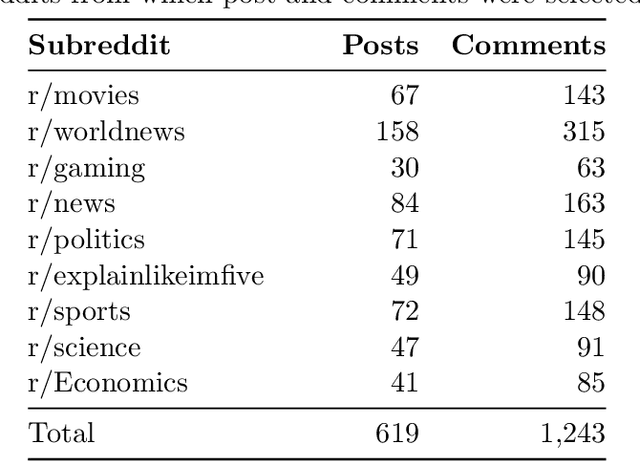

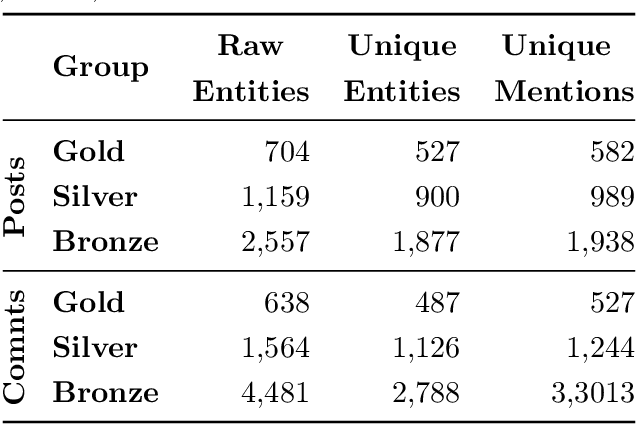
We introduce and make publicly available an entity linking dataset from Reddit that contains17,316 linked entities, each annotated by three human annotators and then grouped into Gold, Silver, and Bronze to indicate inter-annotator agreement. We analyze the different errors and disagreements made by annotators and suggest three types of corrections to the raw data. Finally, we tested existing entity linking models that are trained and tuned on text from non-social media datasets. We find that, although these existing entity linking models perform very well on their original datasets, they perform poorly on this social media dataset. We also show that the majority of these errors can be attributed to poor performance on the mention detection subtask. These results indicate the need for better entity linking models that can be applied to the enormous amount of social media text.