 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking and Refining the Distinct Metric
Paper and Code
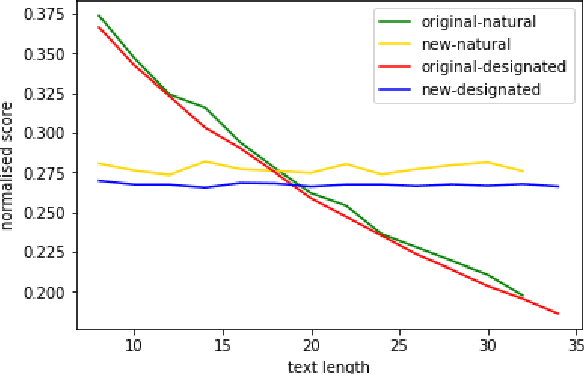
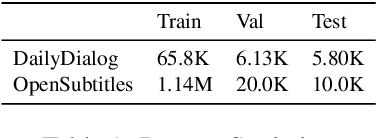
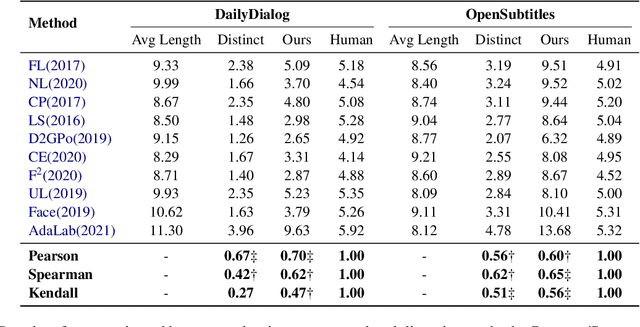
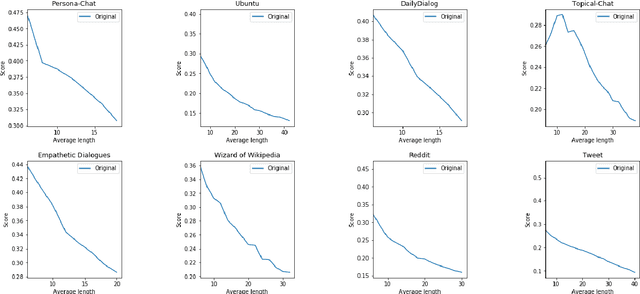
Distinct-$n$ score\cite{Li2016} is a widely used automatic metric for evaluating diversity in language generation tasks. However, we observed that the original approach for calculating distinct scores has evident biases that tend to assign higher penalties to longer sequences. We refine the calculation of distinct scores by scaling the number of distinct tokens based on their expectations. We provide both empirical and theoretical evidence to show that our method effectively removes the biases existing in the original distinct score. Our experiments show that our proposed metric, \textit{Expectation-Adjusted Distinct (EAD)}, correlates better with human judgment in evaluating response diversity. To foster future research, we provide an example implementation at \url{https://github.com/lsy641/Expectation-Adjusted-Distinct}.