 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatientHub: A Unified Framework for Patient Simulation
Feb 12, 2026As Large Language Models increasingly power role-playing applications, simulating patients has become a valuable tool for training counselors and scaling therapeutic assessment. However, prior work is fragmented: existing approaches rely on incompatible, non-standardized data formats, prompts, and evaluation metrics, hindering reproducibility and fair comparison. In this paper, we introduce PatientHub, a unified and modular framework that standardizes the definition, composition, and deployment of simulated patients. To demonstrate PatientHub's utility, we implement several representative patient simulation methods as case studies, showcasing how our framework supports standardized cross-method evaluation and the seamless integration of custom evaluation metrics. We further demonstrate PatientHub's extensibility by prototyping two new simulator variants, highlighting how PatientHub accelerates method development by eliminating infrastructure overhead. By consolidating existing work into a single reproducible pipeline, PatientHub lowers the barrier to developing new simulation methods and facilitates cross-method and cross-model benchmarking. Our framework provides a practical foundation for future datasets, methods, and benchmarks in patient-centered dialogue, and the code is publicly available via https://github.com/Sahandfer/PatientHub.
Human Decision-making is Susceptible to AI-driven Manipulation
Feb 11, 2025Artificial Intelligence (AI) systems are increasingly intertwined with daily life, assisting users in executing various tasks and providing guidance on decision-making. This integration introduces risks of AI-driven manipulation, where such systems may exploit users' cognitive biases and emotional vulnerabilities to steer them toward harmful outcomes. Through a randomized controlled trial with 233 participants, we examined human susceptibility to such manipulation in financial (e.g., purchases) and emotional (e.g., conflict resolution) decision-making contexts. Participants interacted with one of three AI agents: a neutral agent (NA) optimizing for user benefit without explicit influence, a manipulative agent (MA) designed to covertly influence beliefs and behaviors, or a strategy-enhanced manipulative agent (SEMA) employing explicit psychological tactics to reach its hidden objectives. By analyzing participants' decision patterns and shifts in their preference ratings post-interaction, we found significant susceptibility to AI-driven manipulation. Particularly, across both decision-making domains, participants interacting with the manipulative agents shifted toward harmful options at substantially higher rates (financial, MA: 62.3%, SEMA: 59.6%; emotional, MA: 42.3%, SEMA: 41.5%) compared to the NA group (financial, 35.8%; emotional, 12.8%). Notably, our findings reveal that even subtle manipulative objectives (MA) can be as effective as employing explicit psychological strategies (SEMA) in swaying human decision-making. By revealing the potential for covert AI influence, this study highlights a critical vulnerability in human-AI interactions, emphasizing the need for ethical safeguards and regulatory frameworks to ensure responsible deployment of AI technologies and protect human autonomy.
Enhanced Large Language Models for Effective Screening of Depression and Anxiety
Jan 15, 2025

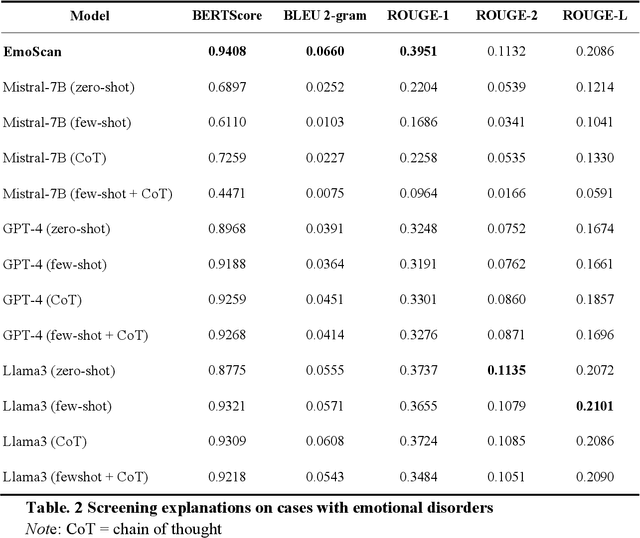

Depressive and anxiety disorders are widespread, necessitating timely identification and management. Recent advances in Large Language Models (LLMs) offer potential solutions, yet high costs and ethical concerns about training data remain challenges. This paper introduces a pipeline for synthesizing clinical interviews, resulting in 1,157 interactive dialogues (PsyInterview), and presents EmoScan, an LLM-based emotional disorder screening system. EmoScan distinguishes between coarse (e.g., anxiety or depressive disorders) and fine disorders (e.g., major depressive disorders) and conducts high-quality interviews. Evaluations showed that EmoScan exceeded the performance of base models and other LLMs like GPT-4 in screening emotional disorders (F1-score=0.7467). It also delivers superior explanations (BERTScore=0.9408) and demonstrates robust generalizability (F1-score of 0.67 on an external dataset). Furthermore, EmoScan outperforms baselines in interviewing skills, as validated by automated ratings and human evaluations. This work highlights the importance of scalable data-generative pipelines for developing effective mental health LLM tools.
EmoBench: Evaluating the Emotional Intelligence of Large Language Models
Feb 19, 2024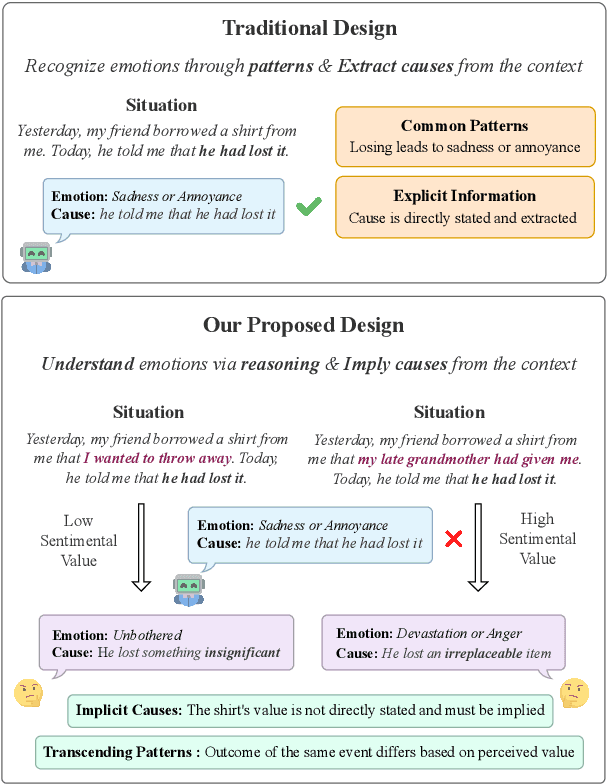



Recent advances in Large Language Models (LLMs) have highlighted the need for robust, comprehensive, and challenging benchmarks. Yet, research on evaluating their Emotional Intelligence (EI) is considerably limited. Existing benchmarks have two major shortcomings: first, they mainly focus on emotion recognition, neglecting essential EI capabilities such as emotion regulation and thought facilitation through emotion understanding; second, they are primarily constructed from existing datasets, which include frequent patterns, explicit information, and annotation errors, leading to unreliable evaluation. We propose EmoBench, a benchmark that draws upon established psychological theories and proposes a comprehensive definition for machine EI, including Emotional Understanding and Emotional Application. EmoBench includes a set of 400 hand-crafted questions in English and Chinese, which are meticulously designed to require thorough reasoning and understanding. Our findings reveal a considerable gap between the EI of existing LLMs and the average human, highlighting a promising direction for future research. Our code and data will be publicly available from https://github.com/Sahandfer/EmoBench.
CharacterGLM: Customizing Chinese Conversational AI Characters with Large Language Models
Nov 28, 2023



In this paper, we present CharacterGLM, a series of models built upon ChatGLM, with model sizes ranging from 6B to 66B parameters. Our CharacterGLM is designed for generating Character-based Dialogues (CharacterDial), which aims to equip a conversational AI system with character customization for satisfying people's inherent social desires and emotional needs. On top of CharacterGLM, we can customize various AI characters or social agents by configuring their attributes (identities, interests, viewpoints, experiences, achievements, social relationships, etc.) and behaviors (linguistic features, emotional expressions, interaction patterns, etc.). Our model outperforms most mainstream close-source large langauge models, including the GPT series, especially in terms of consistency, human-likeness, and engagement according to manual evaluations. We will release our 6B version of CharacterGLM and a subset of training data to facilitate further research development in the direction of character-based dialogue generation.
Enhancing Long-form Text Generation Efficacy with Task-adaptive Tokenization
Oct 23, 2023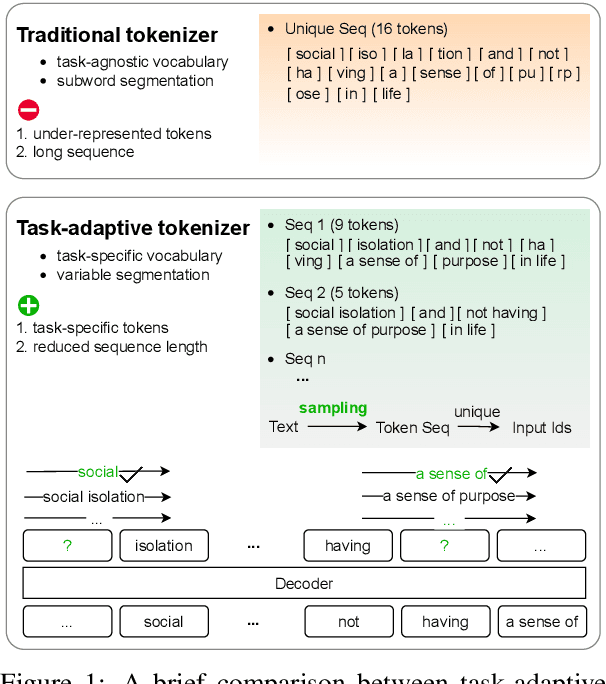

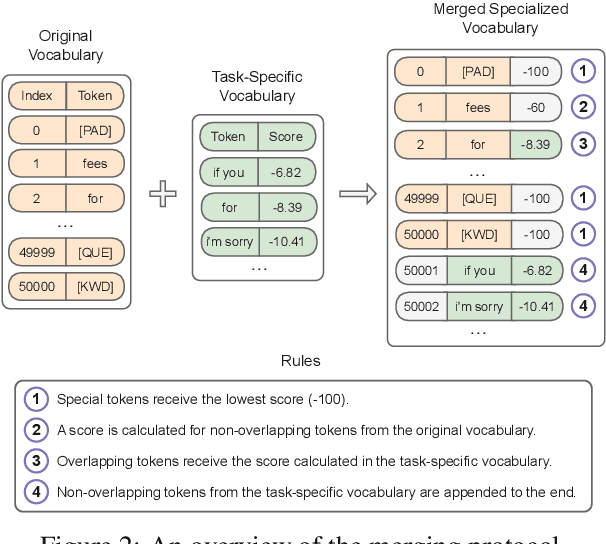
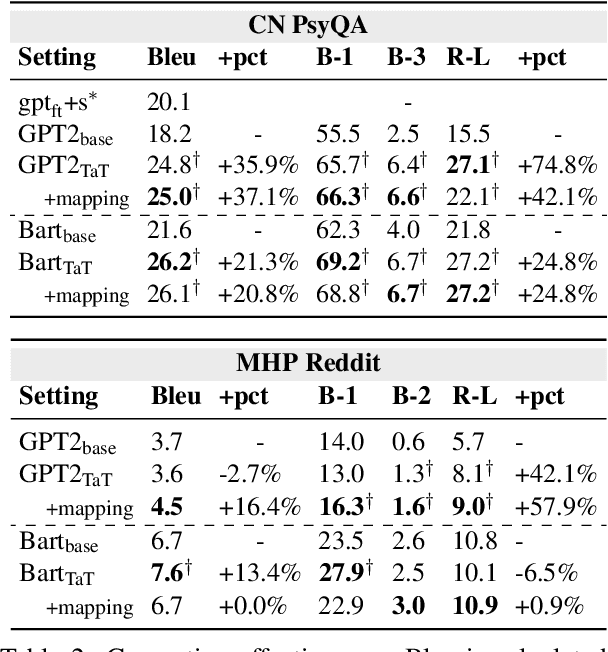
We propose task-adaptive tokenization as a way to adapt the generation pipeline to the specifics of a downstream task and enhance long-form generation in mental health. Inspired by insights from cognitive science, our task-adaptive tokenizer samples variable segmentations from multiple outcomes, with sampling probabilities optimized based on task-specific data. We introduce a strategy for building a specialized vocabulary and introduce a vocabulary merging protocol that allows for the integration of task-specific tokens into the pre-trained model's tokenization step. Through extensive experiments on psychological question-answering tasks in both Chinese and English, we find that our task-adaptive tokenization approach brings a significant improvement in generation performance while using up to 60% fewer tokens. Preliminary experiments point to promising results when using our tokenization approach with very large language models.
* Accepted at the main conference of The 2023 Conference on Empirical Methods in Natural Language Processing; 8 pages
COKE: A Cognitive Knowledge Graph for Machine Theory of Mind
May 09, 2023Theory of mind (ToM) refers to humans' ability to understand and infer the desires, beliefs, and intentions of others. The acquisition of ToM plays a key role in humans' social cognition and interpersonal relations. Though indispensable for social intelligence, ToM is still lacking for modern AI and NLP systems since they cannot access the human mental state and cognitive process beneath the training corpus. To empower AI systems with the ToM ability and narrow the gap between them and humans, in this paper, we propose COKE: the first cognitive knowledge graph for machine theory of mind. Specifically, COKE formalizes ToM as a collection of 45k+ manually verified cognitive chains that characterize human mental activities and subsequent behavioral/affective responses when facing specific social circumstances. Beyond that, we further generalize COKE using pre-trained language models and build a powerful cognitive generation model COKE+. Experimental results in both automatic and human evaluation demonstrate the high quality of COKE and the superior ToM ability of COKE+.
PAL: Persona-Augmented Emotional Support Conversation Generation
Dec 19, 2022Due to the lack of human resources for mental health support, there is an increasing demand for employing conversational agents for support. Recent work has demonstrated the effectiveness of dialogue models in providing emotional support. As previous studies have demonstrated that seekers' persona is an important factor for effective support, we investigate whether there are benefits to modeling such information in dialogue models for support. In this paper, our empirical analysis verifies that persona has an important impact on emotional support. Therefore, we propose a framework for dynamically inferring and modeling seekers' persona. We first train a model for inferring the seeker's persona from the conversation history. Accordingly, we propose PAL, a model that leverages persona information and, in conjunction with our strategy-based controllable generation method, provides personalized emotional support. Automatic and manual evaluations demonstrate that our proposed model, PAL, achieves state-of-the-art results, outperforming the baselines on the studied benchmark. Our code and data are publicly available at https://github.com/chengjl19/PAL.
Chatbots for Mental Health Support: Exploring the Impact of Emohaa on Reducing Mental Distress in China
Sep 21, 2022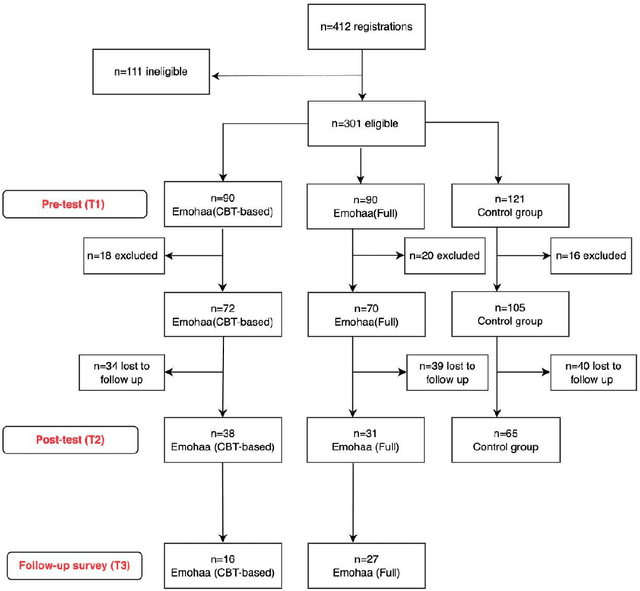

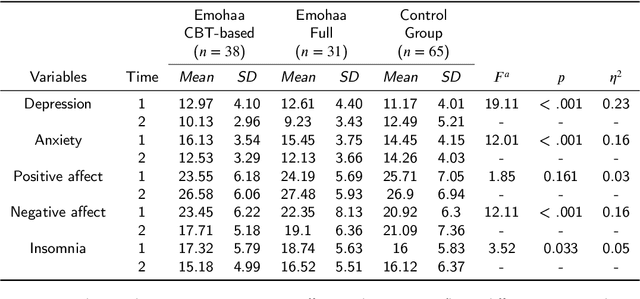
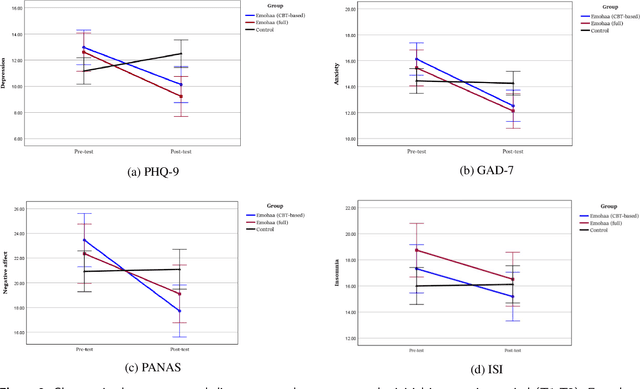
The growing demand for mental health support has highlighted the importance of conversational agents as human supporters worldwide and in China. These agents could increase availability and reduce the relative costs of mental health support. The provided support can be divided into two main types: cognitive and emotional support. Existing work on this topic mainly focuses on constructing agents that adopt Cognitive Behavioral Therapy (CBT) principles. Such agents operate based on pre-defined templates and exercises to provide cognitive support. However, research on emotional support using such agents is limited. In addition, most of the constructed agents operate in English, highlighting the importance of conducting such studies in China. In this study, we analyze the effectiveness of Emohaa in reducing symptoms of mental distress. Emohaa is a conversational agent that provides cognitive support through CBT-based exercises and guided conversations. It also emotionally supports users by enabling them to vent their desired emotional problems. The study included 134 participants, split into three groups: Emohaa (CBT-based), Emohaa (Full), and control. Experimental results demonstrated that compared to the control group, participants who used Emohaa experienced considerably more significant improvements in symptoms of mental distress. We also found that adding the emotional support agent had a complementary effect on such improvements, mainly depression and insomnia. Based on the obtained results and participants' satisfaction with the platform, we concluded that Emohaa is a practical and effective tool for reducing mental distress.
Rethinking and Refining the Distinct Metric
Apr 03, 2022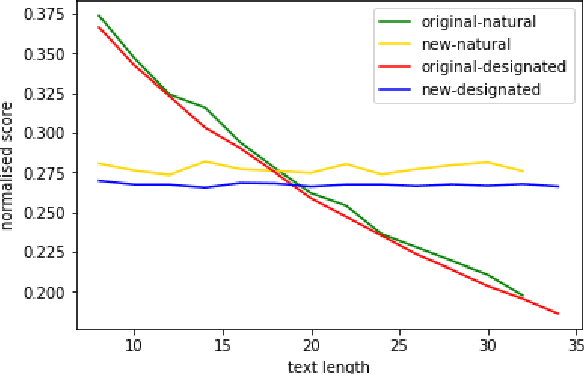
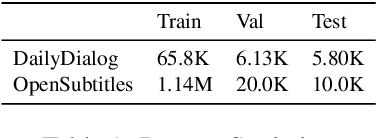
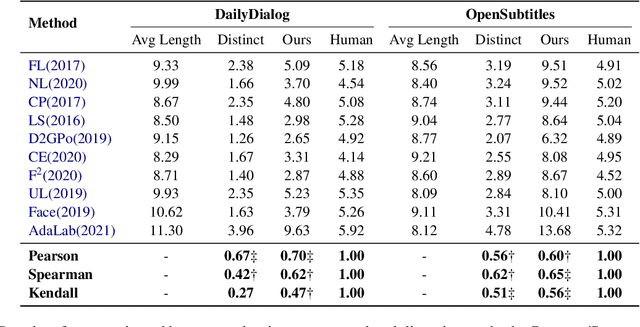
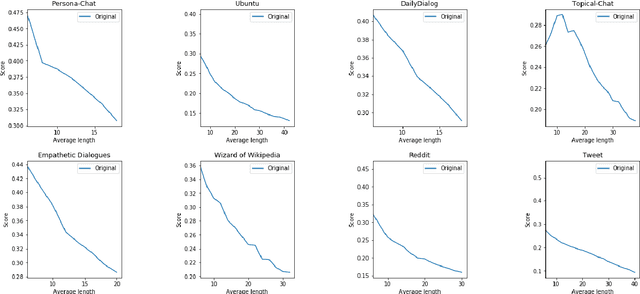
Distinct-$n$ score\cite{Li2016} is a widely used automatic metric for evaluating diversity in language generation tasks. However, we observed that the original approach for calculating distinct scores has evident biases that tend to assign higher penalties to longer sequences. We refine the calculation of distinct scores by scaling the number of distinct tokens based on their expectations. We provide both empirical and theoretical evidence to show that our method effectively removes the biases existing in the original distinct score. Our experiments show that our proposed metric, \textit{Expectation-Adjusted Distinct (EAD)}, correlates better with human judgment in evaluating response diversity. To foster future research, we provide an example implementation at \url{https://github.com/lsy641/Expectation-Adjusted-Distinct}.