 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing LLM-Based Data Annotation with Error Decomposition
Jan 17, 2026Large language models offer a scalable alternative to human coding for data annotation tasks, enabling the scale-up of research across data-intensive domains. While LLMs are already achieving near-human accuracy on objective annotation tasks, their performance on subjective annotation tasks, such as those involving psychological constructs, is less consistent and more prone to errors. Standard evaluation practices typically collapse all annotation errors into a single alignment metric, but this simplified approach may obscure different kinds of errors that affect final analytical conclusions in different ways. Here, we propose a diagnostic evaluation paradigm that incorporates a human-in-the-loop step to separate task-inherent ambiguity from model-driven inaccuracies and assess annotation quality in terms of their potential downstream impacts. We refine this paradigm on ordinal annotation tasks, which are common in subjective annotation. The refined paradigm includes: (1) a diagnostic taxonomy that categorizes LLM annotation errors along two dimensions: source (model-specific vs. task-inherent) and type (boundary ambiguity vs. conceptual misidentification); (2) a lightweight human annotation test to estimate task-inherent ambiguity from LLM annotations; and (3) a computational method to decompose observed LLM annotation errors following our taxonomy. We validate this paradigm on four educational annotation tasks, demonstrating both its conceptual validity and practical utility. Theoretically, our work provides empirical evidence for why excessively high alignment is unrealistic in specific annotation tasks and why single alignment metrics inadequately reflect the quality of LLM annotations. In practice, our paradigm can be a low-cost diagnostic tool that assesses the suitability of a given task for LLM annotation and provides actionable insights for further technical optimization.
Budget-Aware Anytime Reasoning with LLM-Synthesized Preference Data
Jan 16, 2026We study the reasoning behavior of large language models (LLMs) under limited computation budgets. In such settings, producing useful partial solutions quickly is often more practical than exhaustive reasoning, which incurs high inference costs. Many real-world tasks, such as trip planning, require models to deliver the best possible output within a fixed reasoning budget. We introduce an anytime reasoning framework and the Anytime Index, a metric that quantifies how effectively solution quality improves as reasoning tokens increase. To further enhance efficiency, we propose an inference-time self-improvement method using LLM-synthesized preference data, where models learn from their own reasoning comparisons to produce better intermediate solutions. Experiments on NaturalPlan (Trip), AIME, and GPQA datasets show consistent gains across Grok-3, GPT-oss, GPT-4.1/4o, and LLaMA models, improving both reasoning quality and efficiency under budget constraints.
DoubleAgents: Exploring Mechanisms of Building Trust with Proactive AI
Sep 16, 2025Agentic workflows promise efficiency, but adoption hinges on whether people actually trust systems that act on their behalf. We present DoubleAgents, an agentic planning tool that embeds transparency and control through user intervention, value-reflecting policies, rich state visualizations, and uncertainty flagging for human coordination tasks. A built-in respondent simulation generates realistic scenarios, allowing users to rehearse, refine policies, and calibrate their reliance before live use. We evaluate DoubleAgents in a two-day lab study (n=10), two deployments (n=2), and a technical evaluation. Results show that participants initially hesitated to delegate but grew more reliant as they experienced transparency, control, and adaptive learning during simulated cases. Deployment results demonstrate DoubleAgents' real-world relevance and usefulness, showing that the effort required scaled appropriately with task complexity and contextual data. We contribute trust-by-design patterns and mechanisms for proactive AI -- consistency, controllability, and explainability -- along with simulation as a safe path to build and calibrate trust over time.
MetaMind: Modeling Human Social Thoughts with Metacognitive Multi-Agent Systems
May 25, 2025
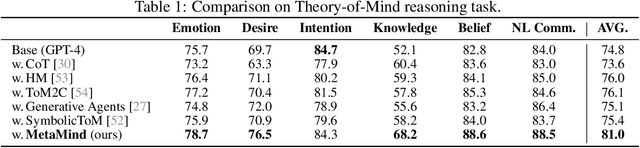
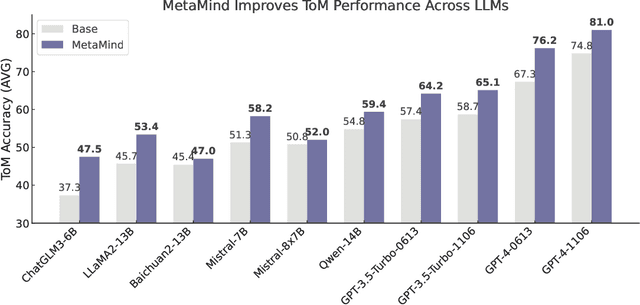
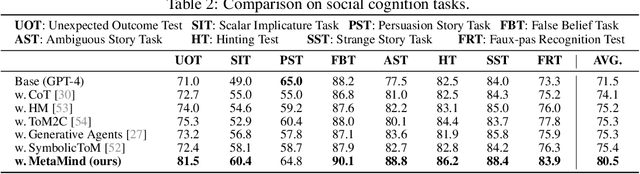
Human social interactions depend on the ability to infer others' unspoken intentions, emotions, and beliefs-a cognitive skill grounded in the psychological concept of Theory of Mind (ToM). While large language models (LLMs) excel in semantic understanding tasks, they struggle with the ambiguity and contextual nuance inherent in human communication. To bridge this gap, we introduce MetaMind, a multi-agent framework inspired by psychological theories of metacognition, designed to emulate human-like social reasoning. MetaMind decomposes social understanding into three collaborative stages: (1) a Theory-of-Mind Agent generates hypotheses user mental states (e.g., intent, emotion), (2) a Domain Agent refines these hypotheses using cultural norms and ethical constraints, and (3) a Response Agent generates contextually appropriate responses while validating alignment with inferred intent. Our framework achieves state-of-the-art performance across three challenging benchmarks, with 35.7% improvement in real-world social scenarios and 6.2% gain in ToM reasoning. Notably, it enables LLMs to match human-level performance on key ToM tasks for the first time. Ablation studies confirm the necessity of all components, which showcase the framework's ability to balance contextual plausibility, social appropriateness, and user adaptation. This work advances AI systems toward human-like social intelligence, with applications in empathetic dialogue and culturally sensitive interactions. Code is available at https://github.com/XMZhangAI/MetaMind.
Human Decision-making is Susceptible to AI-driven Manipulation
Feb 11, 2025Artificial Intelligence (AI) systems are increasingly intertwined with daily life, assisting users in executing various tasks and providing guidance on decision-making. This integration introduces risks of AI-driven manipulation, where such systems may exploit users' cognitive biases and emotional vulnerabilities to steer them toward harmful outcomes. Through a randomized controlled trial with 233 participants, we examined human susceptibility to such manipulation in financial (e.g., purchases) and emotional (e.g., conflict resolution) decision-making contexts. Participants interacted with one of three AI agents: a neutral agent (NA) optimizing for user benefit without explicit influence, a manipulative agent (MA) designed to covertly influence beliefs and behaviors, or a strategy-enhanced manipulative agent (SEMA) employing explicit psychological tactics to reach its hidden objectives. By analyzing participants' decision patterns and shifts in their preference ratings post-interaction, we found significant susceptibility to AI-driven manipulation. Particularly, across both decision-making domains, participants interacting with the manipulative agents shifted toward harmful options at substantially higher rates (financial, MA: 62.3%, SEMA: 59.6%; emotional, MA: 42.3%, SEMA: 41.5%) compared to the NA group (financial, 35.8%; emotional, 12.8%). Notably, our findings reveal that even subtle manipulative objectives (MA) can be as effective as employing explicit psychological strategies (SEMA) in swaying human decision-making. By revealing the potential for covert AI influence, this study highlights a critical vulnerability in human-AI interactions, emphasizing the need for ethical safeguards and regulatory frameworks to ensure responsible deployment of AI technologies and protect human autonomy.
Why language models collapse when trained on recursively generated text
Dec 19, 2024



Language models (LMs) have been widely used to generate text on the Internet. The generated text is often collected into the training corpus of the next generations of LMs. Previous work has experimentally found that LMs collapse when trained on recursively generated text. This paper contributes to existing knowledge from two aspects. We present a theoretical proof of LM collapse. Our proof reveals the cause of LM collapse and proves that all auto-regressive LMs will definitely collapse. We present a new finding: the performance of LMs gradually declines when trained on recursively generated text until they perform no better than a randomly initialized LM. The trained LMs produce large amounts of repetitive text and perform poorly across a wide range of natural language tasks. The above proof and new findings deepen our understanding of LM collapse and offer valuable insights that may inspire new training techniques to mitigate this threat.
Seeker: Towards Exception Safety Code Generation with Intermediate Language Agents Framework
Dec 16, 2024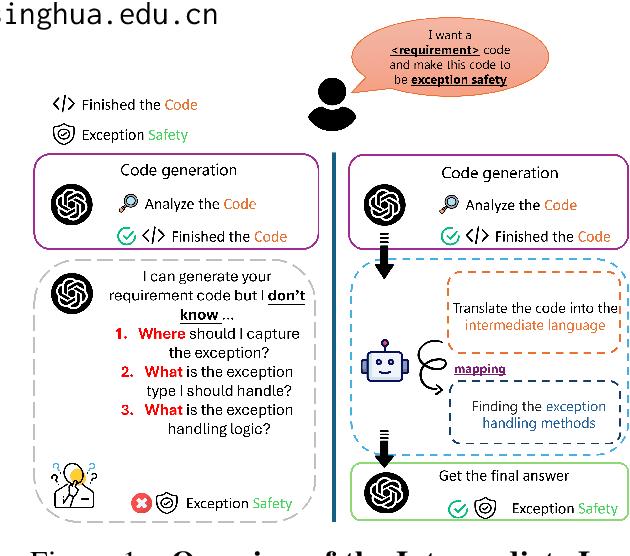
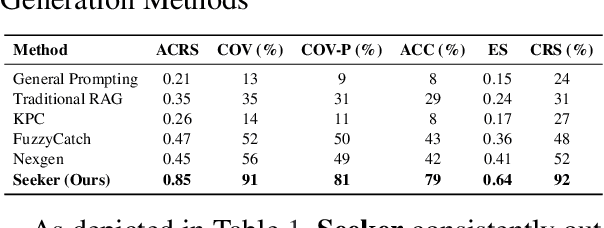
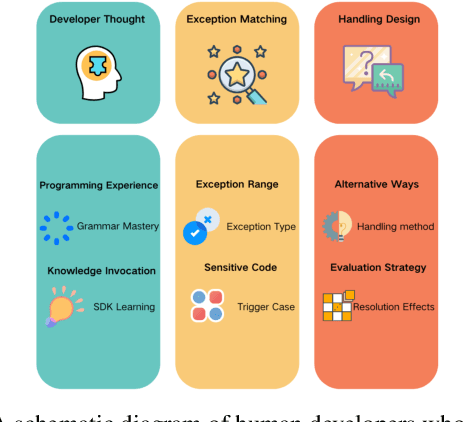
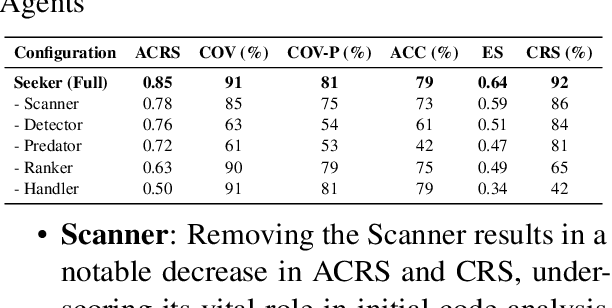
In real world software development, improper or missing exception handling can severely impact the robustness and reliability of code. Exception handling mechanisms require developers to detect, capture, and manage exceptions according to high standards, but many developers struggle with these tasks, leading to fragile code. This problem is particularly evident in open-source projects and impacts the overall quality of the software ecosystem. To address this challenge, we explore the use of large language models (LLMs) to improve exception handling in code. Through extensive analysis, we identify three key issues: Insensitive Detection of Fragile Code, Inaccurate Capture of Exception Block, and Distorted Handling Solution. These problems are widespread across real world repositories, suggesting that robust exception handling practices are often overlooked or mishandled. In response, we propose Seeker, a multi-agent framework inspired by expert developer strategies for exception handling. Seeker uses agents: Scanner, Detector, Predator, Ranker, and Handler to assist LLMs in detecting, capturing, and resolving exceptions more effectively. Our work is the first systematic study on leveraging LLMs to enhance exception handling practices in real development scenarios, providing valuable insights for future improvements in code reliability.
Seeker: Enhancing Exception Handling in Code with LLM-based Multi-Agent Approach
Oct 09, 2024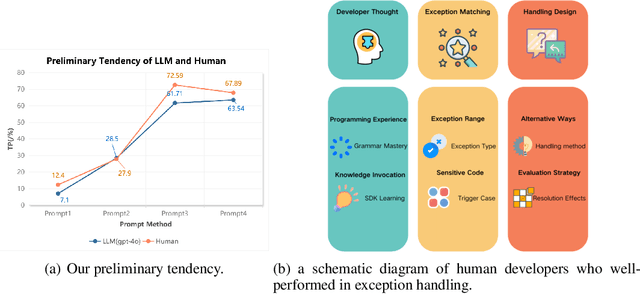

In real world software development, improper or missing exception handling can severely impact the robustness and reliability of code. Exception handling mechanisms require developers to detect, capture, and manage exceptions according to high standards, but many developers struggle with these tasks, leading to fragile code. This problem is particularly evident in open source projects and impacts the overall quality of the software ecosystem. To address this challenge, we explore the use of large language models (LLMs) to improve exception handling in code. Through extensive analysis, we identify three key issues: Insensitive Detection of Fragile Code, Inaccurate Capture of Exception Types, and Distorted Handling Solutions. These problems are widespread across real world repositories, suggesting that robust exception handling practices are often overlooked or mishandled. In response, we propose Seeker, a multi agent framework inspired by expert developer strategies for exception handling. Seeker uses agents: Scanner, Detector, Predator, Ranker, and Handler to assist LLMs in detecting, capturing, and resolving exceptions more effectively. Our work is the first systematic study on leveraging LLMs to enhance exception handling practices, providing valuable insights for future improvements in code reliability.
DECOR: Improving Coherence in L2 English Writing with a Novel Benchmark for Incoherence Detection, Reasoning, and Rewriting
Jun 28, 2024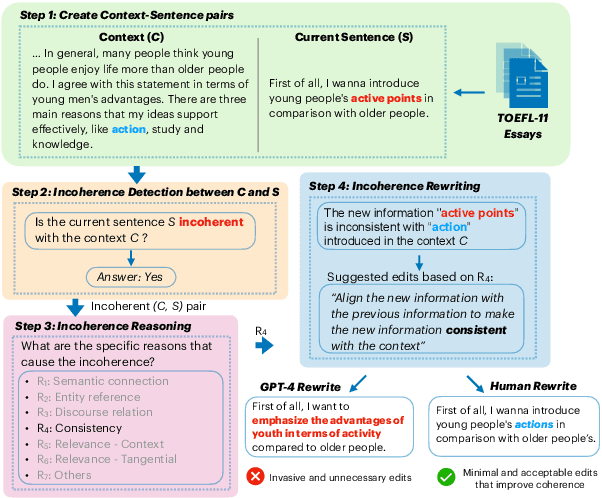


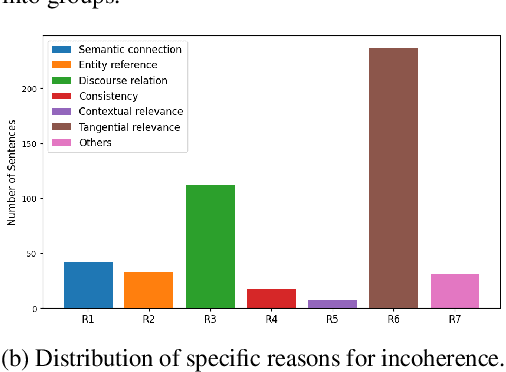
Coherence in writing, an aspect that second-language (L2) English learners often struggle with, is crucial in assessing L2 English writing. Existing automated writing evaluation systems primarily use basic surface linguistic features to detect coherence in writing. However, little effort has been made to correct the detected incoherence, which could significantly benefit L2 language learners seeking to improve their writing. To bridge this gap, we introduce DECOR, a novel benchmark that includes expert annotations for detecting incoherence in L2 English writing, identifying the underlying reasons, and rewriting the incoherent sentences. To our knowledge, DECOR is the first coherence assessment dataset specifically designed for improving L2 English writing, featuring pairs of original incoherent sentences alongside their expert-rewritten counterparts. Additionally, we fine-tuned models to automatically detect and rewrite incoherence in student essays. We find that incorporating specific reasons for incoherence during fine-tuning consistently improves the quality of the rewrites, achieving a result that is favored in both automatic and human evaluations.
VarBench: Robust Language Model Benchmarking Through Dynamic Variable Perturbation
Jun 26, 2024



As large language models achieve impressive scores on traditional benchmarks, an increasing number of researchers are becoming concerned about benchmark data leakage during pre-training, commonly known as the data contamination problem. To ensure fair evaluation, recent benchmarks release only the training and validation sets, keeping the test set labels closed-source. They require anyone wishing to evaluate his language model to submit the model's predictions for centralized processing and then publish the model's result on their leaderboard. However, this submission process is inefficient and prevents effective error analysis. To address this issue, we propose to variabilize benchmarks and evaluate language models dynamically. Specifically, we extract variables from each test case and define a value range for each variable. For each evaluation, we sample new values from these value ranges to create unique test cases, thus ensuring a fresh evaluation each time. We applied this variable perturbation method to four datasets: GSM8K, ARC, CommonsenseQA, and TruthfulQA, which cover mathematical generation and multiple-choice tasks. Our experimental results demonstrate that this approach provides a more accurate assessment of the true capabilities of language models, effectively mitigating the contamination problem.