 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion-Based Cross-Modal Feature Extraction for Multi-Label Classification
Sep 19, 2025Multi-label classification has broad applications and depends on powerful representations capable of capturing multi-label interactions. We introduce \textit{Diff-Feat}, a simple but powerful framework that extracts intermediate features from pre-trained diffusion-Transformer models for images and text, and fuses them for downstream tasks. We observe that for vision tasks, the most discriminative intermediate feature along the diffusion process occurs at the middle step and is located in the middle block in Transformer. In contrast, for language tasks, the best feature occurs at the noise-free step and is located in the deepest block. In particular, we observe a striking phenomenon across varying datasets: a mysterious "Layer $12$" consistently yields the best performance on various downstream classification tasks for images (under DiT-XL/2-256$\times$256). We devise a heuristic local-search algorithm that pinpoints the locally optimal "image-text"$\times$"block-timestep" pair among a few candidates, avoiding an exhaustive grid search. A simple fusion-linear projection followed by addition-of the selected representations yields state-of-the-art performance: 98.6\% mAP on MS-COCO-enhanced and 45.7\% mAP on Visual Genome 500, surpassing strong CNN, graph, and Transformer baselines by a wide margin. t-SNE and clustering metrics further reveal that \textit{Diff-Feat} forms tighter semantic clusters than unimodal counterparts. The code is available at https://github.com/lt-0123/Diff-Feat.
Seeker: Towards Exception Safety Code Generation with Intermediate Language Agents Framework
Dec 16, 2024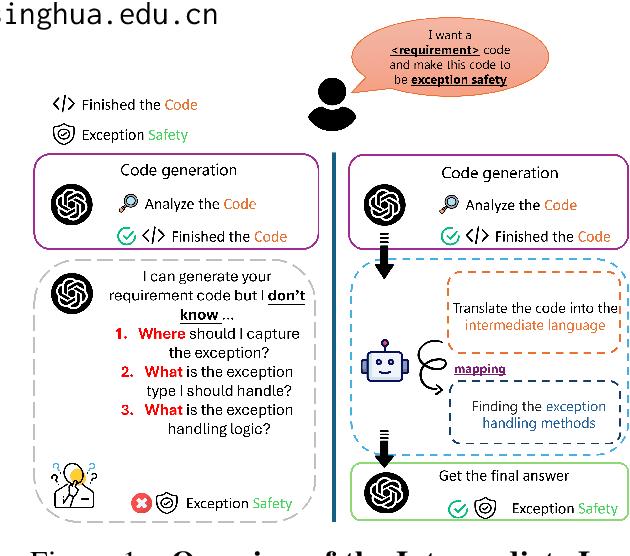
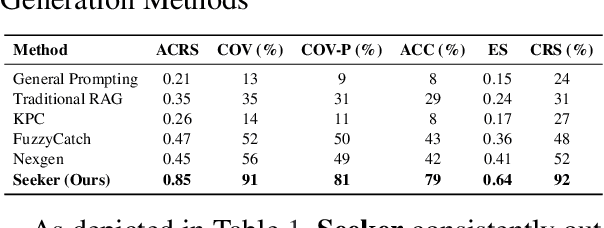
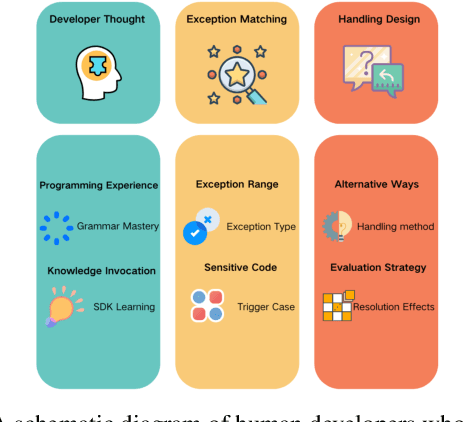
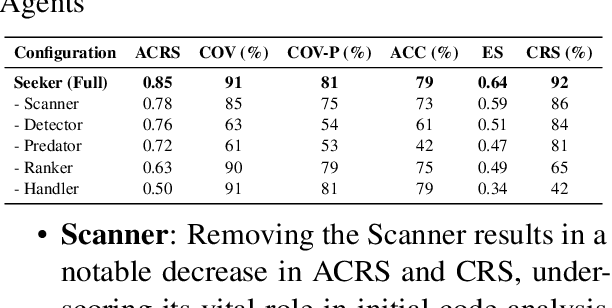
In real world software development, improper or missing exception handling can severely impact the robustness and reliability of code. Exception handling mechanisms require developers to detect, capture, and manage exceptions according to high standards, but many developers struggle with these tasks, leading to fragile code. This problem is particularly evident in open-source projects and impacts the overall quality of the software ecosystem. To address this challenge, we explore the use of large language models (LLMs) to improve exception handling in code. Through extensive analysis, we identify three key issues: Insensitive Detection of Fragile Code, Inaccurate Capture of Exception Block, and Distorted Handling Solution. These problems are widespread across real world repositories, suggesting that robust exception handling practices are often overlooked or mishandled. In response, we propose Seeker, a multi-agent framework inspired by expert developer strategies for exception handling. Seeker uses agents: Scanner, Detector, Predator, Ranker, and Handler to assist LLMs in detecting, capturing, and resolving exceptions more effectively. Our work is the first systematic study on leveraging LLMs to enhance exception handling practices in real development scenarios, providing valuable insights for future improvements in code reliability.
QuadWBG: Generalizable Quadrupedal Whole-Body Grasping
Nov 11, 2024



Legged robots with advanced manipulation capabilities have the potential to significantly improve household duties and urban maintenance. Despite considerable progress in developing robust locomotion and precise manipulation methods, seamlessly integrating these into cohesive whole-body control for real-world applications remains challenging. In this paper, we present a modular framework for robust and generalizable whole-body loco-manipulation controller based on a single arm-mounted camera. By using reinforcement learning (RL), we enable a robust low-level policy for command execution over 5 dimensions (5D) and a grasp-aware high-level policy guided by a novel metric, Generalized Oriented Reachability Map (GORM). The proposed system achieves state-of-the-art one-time grasping accuracy of 89% in the real world, including challenging tasks such as grasping transparent objects. Through extensive simulations and real-world experiments, we demonstrate that our system can effectively manage a large workspace, from floor level to above body height, and perform diverse whole-body loco-manipulation tasks.
The Irrationality of Neural Rationale Models
Oct 14, 2021



Neural rationale models are popular for interpretable predictions of NLP tasks. In these, a selector extracts segments of the input text, called rationales, and passes these segments to a classifier for prediction. Since the rationale is the only information accessible to the classifier, it is plausibly defined as the explanation. Is such a characterization unconditionally correct? In this paper, we argue to the contrary, with both philosophical perspectives and empirical evidence suggesting that rationale models are, perhaps, less rational and interpretable than expected. We call for more rigorous and comprehensive evaluations of these models to ensure desired properties of interpretability are indeed achieved. The code can be found at https://github.com/yimingz89/Neural-Rationale-Analysis.