 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvoCoT: Overcoming the Exploration Bottleneck in Reinforcement Learning
Aug 11, 2025Reinforcement learning with verifiable reward (RLVR) has become a promising paradigm for post-training large language models (LLMs) to improve their reasoning capability. However, when the rollout accuracy is low on hard problems, the reward becomes sparse, limiting learning efficiency and causing exploration bottlenecks. Existing approaches either rely on stronger LLMs for distillation or filter out difficult problems, which limits scalability or restricts reasoning improvement through exploration. We propose EvoCoT, a self-evolving curriculum learning framework based on two-stage chain-of-thought (CoT) reasoning optimization. EvoCoT constrains the exploration space by self-generating and verifying CoT trajectories, then gradually shortens them to expand the space in a controlled way. This enables LLMs to stably learn from initially unsolved hard problems under sparse rewards. We apply EvoCoT to multiple LLM families, including Qwen, DeepSeek, and Llama. Experiments show that EvoCoT enables LLMs to solve previously unsolved problems, improves reasoning capability without external CoT supervision, and is compatible with various RL fine-tuning methods. We release the source code to support future research.
Why language models collapse when trained on recursively generated text
Dec 19, 2024



Language models (LMs) have been widely used to generate text on the Internet. The generated text is often collected into the training corpus of the next generations of LMs. Previous work has experimentally found that LMs collapse when trained on recursively generated text. This paper contributes to existing knowledge from two aspects. We present a theoretical proof of LM collapse. Our proof reveals the cause of LM collapse and proves that all auto-regressive LMs will definitely collapse. We present a new finding: the performance of LMs gradually declines when trained on recursively generated text until they perform no better than a randomly initialized LM. The trained LMs produce large amounts of repetitive text and perform poorly across a wide range of natural language tasks. The above proof and new findings deepen our understanding of LM collapse and offer valuable insights that may inspire new training techniques to mitigate this threat.
RoboMIND: Benchmark on Multi-embodiment Intelligence Normative Data for Robot Manipulation
Dec 18, 2024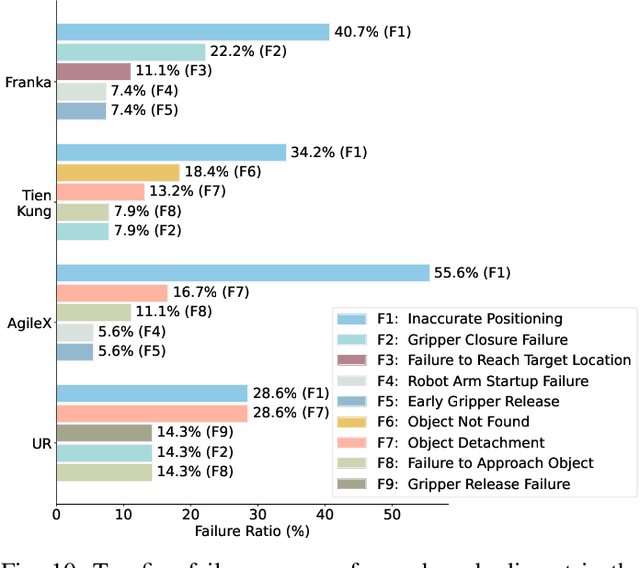
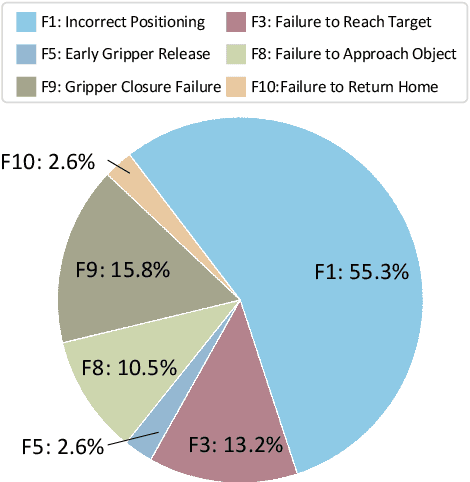
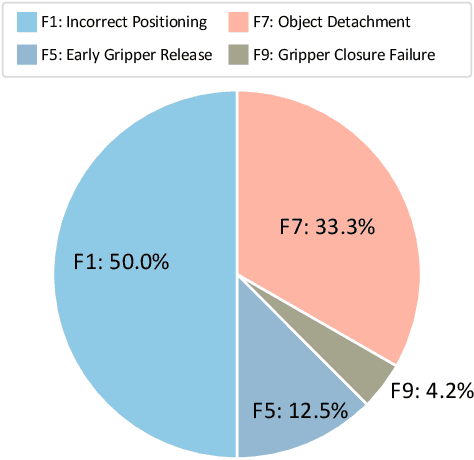
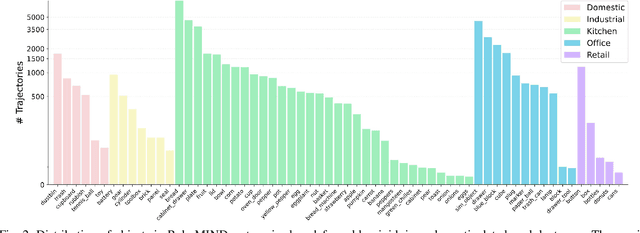
Developing robust and general-purpose robotic manipulation policies is a key goal in the field of robotics. To achieve effective generalization, it is essential to construct comprehensive datasets that encompass a large number of demonstration trajectories and diverse tasks. Unlike vision or language data that can be collected from the Internet, robotic datasets require detailed observations and manipulation actions, necessitating significant investment in hardware-software infrastructure and human labor. While existing works have focused on assembling various individual robot datasets, there remains a lack of a unified data collection standard and insufficient diversity in tasks, scenarios, and robot types. In this paper, we introduce RoboMIND (Multi-embodiment Intelligence Normative Data for Robot manipulation), featuring 55k real-world demonstration trajectories across 279 diverse tasks involving 61 different object classes. RoboMIND is collected through human teleoperation and encompasses comprehensive robotic-related information, including multi-view RGB-D images, proprioceptive robot state information, end effector details, and linguistic task descriptions. To ensure dataset consistency and reliability during policy learning, RoboMIND is built on a unified data collection platform and standardized protocol, covering four distinct robotic embodiments. We provide a thorough quantitative and qualitative analysis of RoboMIND across multiple dimensions, offering detailed insights into the diversity of our datasets. In our experiments, we conduct extensive real-world testing with four state-of-the-art imitation learning methods, demonstrating that training with RoboMIND data results in a high manipulation success rate and strong generalization. Our project is at https://x-humanoid-robomind.github.io/.
Generating Equivalent Representations of Code By A Self-Reflection Approach
Oct 04, 2024


Equivalent Representations (ERs) of code are textual representations that preserve the same semantics as the code itself, e.g., natural language comments and pseudocode. ERs play a critical role in software development and maintenance. However, how to automatically generate ERs of code remains an open challenge. In this paper, we propose a self-reflection approach to generating ERs of code. It enables two Large Language Models (LLMs) to work mutually and produce an ER through a reflection process. Depending on whether constraints on ERs are applied, our approach generates ERs in both open and constrained settings. We conduct a empirical study to generate ERs in two settings and obtain eight findings. (1) Generating ERs in the open setting. In the open setting, we allow LLMs to represent code without any constraints, analyzing the resulting ERs and uncovering five key findings. These findings shed light on how LLMs comprehend syntactic structures, APIs, and numerical computations in code. (2) Generating ERs in the constrained setting. In the constrained setting, we impose constraints on ERs, such as natural language comments, pseudocode, and flowcharts. This allows our approach to address a range of software engineering tasks. Based on our experiments, we have three findings demonstrating that our approach can effectively generate ERs that adhere to specific constraints, thus supporting various software engineering tasks. (3) Future directions. We also discuss potential future research directions, such as deriving intermediate languages for code generation, exploring LLM-friendly requirement descriptions, and further supporting software engineering tasks. We believe that this paper will spark discussions in research communities and inspire many follow-up studies.
DevEval: A Manually-Annotated Code Generation Benchmark Aligned with Real-World Code Repositories
May 30, 2024How to evaluate the coding abilities of Large Language Models (LLMs) remains an open question. We find that existing benchmarks are poorly aligned with real-world code repositories and are insufficient to evaluate the coding abilities of LLMs. To address the knowledge gap, we propose a new benchmark named DevEval, which has three advances. (1) DevEval aligns with real-world repositories in multiple dimensions, e.g., code distributions and dependency distributions. (2) DevEval is annotated by 13 developers and contains comprehensive annotations (e.g., requirements, original repositories, reference code, and reference dependencies). (3) DevEval comprises 1,874 testing samples from 117 repositories, covering 10 popular domains (e.g., Internet, Database). Based on DevEval, we propose repository-level code generation and evaluate 8 popular LLMs on DevEval (e.g., gpt-4, gpt-3.5, StarCoder 2, DeepSeek Coder, CodeLLaMa). Our experiments reveal these LLMs' coding abilities in real-world code repositories. For example, in our experiments, the highest Pass@1 of gpt-4-turbo is only 53.04%. We also analyze LLMs' failed cases and summarize their shortcomings. We hope DevEval can facilitate the development of LLMs in real code repositories. DevEval, prompts, and LLMs' predictions have been released.
DevEval: Evaluating Code Generation in Practical Software Projects
Jan 26, 2024



How to evaluate Large Language Models (LLMs) in code generation is an open question. Many benchmarks have been proposed but are inconsistent with practical software projects, e.g., unreal program distributions, insufficient dependencies, and small-scale project contexts. Thus, the capabilities of LLMs in practical projects are still unclear. In this paper, we propose a new benchmark named DevEval, aligned with Developers' experiences in practical projects. DevEval is collected through a rigorous pipeline, containing 2,690 samples from 119 practical projects and covering 10 domains. Compared to previous benchmarks, DevEval aligns to practical projects in multiple dimensions, e.g., real program distributions, sufficient dependencies, and enough-scale project contexts. We assess five popular LLMs on DevEval (e.g., gpt-4, gpt-3.5-turbo, CodeLLaMa, and StarCoder) and reveal their actual abilities in code generation. For instance, the highest Pass@1 of gpt-3.5-turbo only is 42 in our experiments. We also discuss the challenges and future directions of code generation in practical projects. We open-source DevEval and hope it can facilitate the development of code generation in practical projects.