 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Transformers Have the Ability for Periodicity Generalization?
Jan 30, 2026Large language models (LLMs) based on the Transformer have demonstrated strong performance across diverse tasks. However, current models still exhibit substantial limitations in out-of-distribution (OOD) generalization compared with humans. We investigate this gap through periodicity, one of the basic OOD scenarios. Periodicity captures invariance amid variation. Periodicity generalization represents a model's ability to extract periodic patterns from training data and generalize to OOD scenarios. We introduce a unified interpretation of periodicity from the perspective of abstract algebra and reasoning, including both single and composite periodicity, to explain why Transformers struggle to generalize periodicity. Then we construct Coper about composite periodicity, a controllable generative benchmark with two OOD settings, Hollow and Extrapolation. Experiments reveal that periodicity generalization in Transformers is limited, where models can memorize periodic data during training, but cannot generalize to unseen composite periodicity. We release the source code to support future research.
EvoCoT: Overcoming the Exploration Bottleneck in Reinforcement Learning
Aug 11, 2025Reinforcement learning with verifiable reward (RLVR) has become a promising paradigm for post-training large language models (LLMs) to improve their reasoning capability. However, when the rollout accuracy is low on hard problems, the reward becomes sparse, limiting learning efficiency and causing exploration bottlenecks. Existing approaches either rely on stronger LLMs for distillation or filter out difficult problems, which limits scalability or restricts reasoning improvement through exploration. We propose EvoCoT, a self-evolving curriculum learning framework based on two-stage chain-of-thought (CoT) reasoning optimization. EvoCoT constrains the exploration space by self-generating and verifying CoT trajectories, then gradually shortens them to expand the space in a controlled way. This enables LLMs to stably learn from initially unsolved hard problems under sparse rewards. We apply EvoCoT to multiple LLM families, including Qwen, DeepSeek, and Llama. Experiments show that EvoCoT enables LLMs to solve previously unsolved problems, improves reasoning capability without external CoT supervision, and is compatible with various RL fine-tuning methods. We release the source code to support future research.
RL-PLUS: Countering Capability Boundary Collapse of LLMs in Reinforcement Learning with Hybrid-policy Optimization
Jul 31, 2025Reinforcement Learning with Verifiable Reward (RLVR) has significantly advanced the complex reasoning abilities of Large Language Models (LLMs). However, it struggles to break through the inherent capability boundaries of the base LLM, due to its inherently on-policy strategy with LLM's immense action space and sparse reward. Further, RLVR can lead to the capability boundary collapse, narrowing the LLM's problem-solving scope. To address this problem, we propose RL-PLUS, a novel approach that synergizes internal exploitation (i.e., Thinking) with external data (i.e., Learning) to achieve stronger reasoning capabilities and surpass the boundaries of base models. RL-PLUS integrates two core components: Multiple Importance Sampling to address for distributional mismatch from external data, and an Exploration-Based Advantage Function to guide the model towards high-value, unexplored reasoning paths. We provide both theoretical analysis and extensive experiments to demonstrate the superiority and generalizability of our approach. The results show that RL-PLUS achieves state-of-the-art performance compared with existing RLVR methods on six math reasoning benchmarks and exhibits superior performance on six out-of-distribution reasoning tasks. It also achieves consistent and significant gains across diverse model families, with average relative improvements ranging from 21.1\% to 69.2\%. Moreover, Pass@k curves across multiple benchmarks indicate that RL-PLUS effectively resolves the capability boundary collapse problem.
SATURN: SAT-based Reinforcement Learning to Unleash Language Model Reasoning
May 22, 2025How to design reinforcement learning (RL) tasks that effectively unleash the reasoning capability of large language models (LLMs) remains an open question. Existing RL tasks (e.g., math, programming, and constructing reasoning tasks) suffer from three key limitations: (1) Scalability. They rely heavily on human annotation or expensive LLM synthesis to generate sufficient training data. (2) Verifiability. LLMs' outputs are hard to verify automatically and reliably. (3) Controllable Difficulty. Most tasks lack fine-grained difficulty control, making it hard to train LLMs to develop reasoning ability from easy to hard. To address these limitations, we propose Saturn, a SAT-based RL framework that uses Boolean Satisfiability (SAT) problems to train and evaluate LLM reasoning. Saturn enables scalable task construction, rule-based verification, and precise difficulty control. Saturn designs a curriculum learning pipeline that continuously improves LLMs' reasoning capability by constructing SAT tasks of increasing difficulty and training LLMs from easy to hard. To ensure stable training, we design a principled mechanism to control difficulty transitions. We introduce Saturn-2.6k, a dataset of 2,660 SAT problems with varying difficulty. It supports the evaluation of how LLM reasoning changes with problem difficulty. We apply Saturn to DeepSeek-R1-Distill-Qwen and obtain Saturn-1.5B and Saturn-7B. We achieve several notable results: (1) On SAT problems, Saturn-1.5B and Saturn-7B achieve average pass@3 improvements of +14.0 and +28.1, respectively. (2) On math and programming tasks, Saturn-1.5B and Saturn-7B improve average scores by +4.9 and +1.8 on benchmarks (e.g., AIME, LiveCodeBench). (3) Compared to the state-of-the-art (SOTA) approach in constructing RL tasks, Saturn achieves further improvements of +8.8%. We release the source code, data, and models to support future research.
FANformer: Improving Large Language Models Through Effective Periodicity Modeling
Feb 28, 2025Periodicity, as one of the most important basic characteristics, lays the foundation for facilitating structured knowledge acquisition and systematic cognitive processes within human learning paradigms. However, the potential flaws of periodicity modeling in Transformer affect the learning efficiency and establishment of underlying principles from data for large language models (LLMs) built upon it. In this paper, we demonstrate that integrating effective periodicity modeling can improve the learning efficiency and performance of LLMs. We introduce FANformer, which integrates Fourier Analysis Network (FAN) into attention mechanism to achieve efficient periodicity modeling, by modifying the feature projection process of attention mechanism. Extensive experimental results on language modeling show that FANformer consistently outperforms Transformer when scaling up model size and training tokens, underscoring its superior learning efficiency. To further validate the effectiveness of FANformer, we pretrain a FANformer-1B on 1 trillion tokens. FANformer-1B exhibits marked improvements on downstream tasks compared to open-source LLMs with similar model parameters or training tokens. The results position FANformer as an effective and promising architecture for advancing LLMs.
aiXcoder-7B: A Lightweight and Effective Large Language Model for Code Completion
Oct 17, 2024


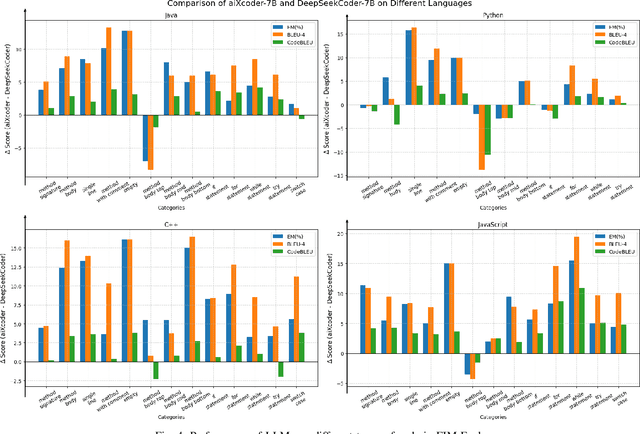
Large Language Models (LLMs) have been widely used in code completion, and researchers are focusing on scaling up LLMs to improve their accuracy. However, larger LLMs will increase the response time of code completion and decrease the developers' productivity. In this paper, we propose a lightweight and effective LLM for code completion named aiXcoder-7B. Compared to existing LLMs, aiXcoder-7B achieves higher code completion accuracy while having smaller scales (i.e., 7 billion parameters). We attribute the superiority of aiXcoder-7B to three key factors: (1) Multi-objective training. We employ three training objectives, one of which is our proposed Structured Fill-In-the-Middle (SFIM). SFIM considers the syntax structures in code and effectively improves the performance of LLMs for code. (2) Diverse data sampling strategies. They consider inter-file relationships and enhance the capability of LLMs in understanding cross-file contexts. (3) Extensive high-quality data. We establish a rigorous data collection pipeline and consume a total of 1.2 trillion unique tokens for training aiXcoder-7B. This vast volume of data enables aiXcoder-7B to learn a broad distribution of code. We evaluate aiXcoder-7B in five popular code completion benchmarks and a new benchmark collected by this paper. The results show that aiXcoder-7B outperforms the latest six LLMs with similar sizes and even surpasses four larger LLMs (e.g., StarCoder2-15B and CodeLlama-34B), positioning aiXcoder-7B as a lightweight and effective LLM for academia and industry. Finally, we summarize three valuable insights for helping practitioners train the next generations of LLMs for code. aiXcoder-7B has been open-souced and gained significant attention. As of the submission date, aiXcoder-7B has received 2,193 GitHub Stars.
DevEval: A Manually-Annotated Code Generation Benchmark Aligned with Real-World Code Repositories
May 30, 2024How to evaluate the coding abilities of Large Language Models (LLMs) remains an open question. We find that existing benchmarks are poorly aligned with real-world code repositories and are insufficient to evaluate the coding abilities of LLMs. To address the knowledge gap, we propose a new benchmark named DevEval, which has three advances. (1) DevEval aligns with real-world repositories in multiple dimensions, e.g., code distributions and dependency distributions. (2) DevEval is annotated by 13 developers and contains comprehensive annotations (e.g., requirements, original repositories, reference code, and reference dependencies). (3) DevEval comprises 1,874 testing samples from 117 repositories, covering 10 popular domains (e.g., Internet, Database). Based on DevEval, we propose repository-level code generation and evaluate 8 popular LLMs on DevEval (e.g., gpt-4, gpt-3.5, StarCoder 2, DeepSeek Coder, CodeLLaMa). Our experiments reveal these LLMs' coding abilities in real-world code repositories. For example, in our experiments, the highest Pass@1 of gpt-4-turbo is only 53.04%. We also analyze LLMs' failed cases and summarize their shortcomings. We hope DevEval can facilitate the development of LLMs in real code repositories. DevEval, prompts, and LLMs' predictions have been released.
Generalization or Memorization: Data Contamination and Trustworthy Evaluation for Large Language Models
Feb 24, 2024Recent statements about the impressive capabilities of large language models (LLMs) are usually supported by evaluating on open-access benchmarks. Considering the vast size and wide-ranging sources of LLMs' training data, it could explicitly or implicitly include test data, leading to LLMs being more susceptible to data contamination. However, due to the opacity of training data, the black-box access of models, and the rapid growth of synthetic training data, detecting and mitigating data contamination for LLMs faces significant challenges. In this paper, we propose CDD, which stands for Contamination Detection via output Distribution for LLMs. CDD necessitates only the sampled texts to detect data contamination, by identifying the peakedness of LLM's output distribution. To mitigate the impact of data contamination in evaluation, we also present TED: Trustworthy Evaluation via output Distribution, based on the correction of LLM's output distribution. To facilitate this study, we introduce two benchmarks, i.e., DetCon and ComiEval, for data contamination detection and contamination mitigation evaluation tasks. Extensive experimental results show that CDD achieves the average relative improvements of 21.8\%-30.2\% over other contamination detection approaches in terms of Accuracy, F1 Score, and AUC metrics, and can effectively detect contamination caused by the variants of test data. TED significantly mitigates performance improvements up to 66.9\% attributed to data contamination across 24 settings and 21 contamination degrees. In real-world applications, we reveal that ChatGPT exhibits a high potential to suffer from data contamination on HumanEval benchmark.
DevEval: Evaluating Code Generation in Practical Software Projects
Jan 26, 2024



How to evaluate Large Language Models (LLMs) in code generation is an open question. Many benchmarks have been proposed but are inconsistent with practical software projects, e.g., unreal program distributions, insufficient dependencies, and small-scale project contexts. Thus, the capabilities of LLMs in practical projects are still unclear. In this paper, we propose a new benchmark named DevEval, aligned with Developers' experiences in practical projects. DevEval is collected through a rigorous pipeline, containing 2,690 samples from 119 practical projects and covering 10 domains. Compared to previous benchmarks, DevEval aligns to practical projects in multiple dimensions, e.g., real program distributions, sufficient dependencies, and enough-scale project contexts. We assess five popular LLMs on DevEval (e.g., gpt-4, gpt-3.5-turbo, CodeLLaMa, and StarCoder) and reveal their actual abilities in code generation. For instance, the highest Pass@1 of gpt-3.5-turbo only is 42 in our experiments. We also discuss the challenges and future directions of code generation in practical projects. We open-source DevEval and hope it can facilitate the development of code generation in practical projects.
Flowmind2Digital: The First Comprehensive Flowmind Recognition and Conversion Approach
Jan 08, 2024Flowcharts and mind maps, collectively known as flowmind, are vital in daily activities, with hand-drawn versions facilitating real-time collaboration. However, there's a growing need to digitize them for efficient processing. Automated conversion methods are essential to overcome manual conversion challenges. Existing sketch recognition methods face limitations in practical situations, being field-specific and lacking digital conversion steps. Our paper introduces the Flowmind2digital method and hdFlowmind dataset to address these challenges. Flowmind2digital, utilizing neural networks and keypoint detection, achieves a record 87.3% accuracy on our dataset, surpassing previous methods by 11.9%. The hdFlowmind dataset, comprising 1,776 annotated flowminds across 22 scenarios, outperforms existing datasets. Additionally, our experiments emphasize the importance of simple graphics, enhancing accuracy by 9.3%.