 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFANformer: Improving Large Language Models Through Effective Periodicity Modeling
Feb 28, 2025Periodicity, as one of the most important basic characteristics, lays the foundation for facilitating structured knowledge acquisition and systematic cognitive processes within human learning paradigms. However, the potential flaws of periodicity modeling in Transformer affect the learning efficiency and establishment of underlying principles from data for large language models (LLMs) built upon it. In this paper, we demonstrate that integrating effective periodicity modeling can improve the learning efficiency and performance of LLMs. We introduce FANformer, which integrates Fourier Analysis Network (FAN) into attention mechanism to achieve efficient periodicity modeling, by modifying the feature projection process of attention mechanism. Extensive experimental results on language modeling show that FANformer consistently outperforms Transformer when scaling up model size and training tokens, underscoring its superior learning efficiency. To further validate the effectiveness of FANformer, we pretrain a FANformer-1B on 1 trillion tokens. FANformer-1B exhibits marked improvements on downstream tasks compared to open-source LLMs with similar model parameters or training tokens. The results position FANformer as an effective and promising architecture for advancing LLMs.
aiXcoder-7B: A Lightweight and Effective Large Language Model for Code Completion
Oct 17, 2024


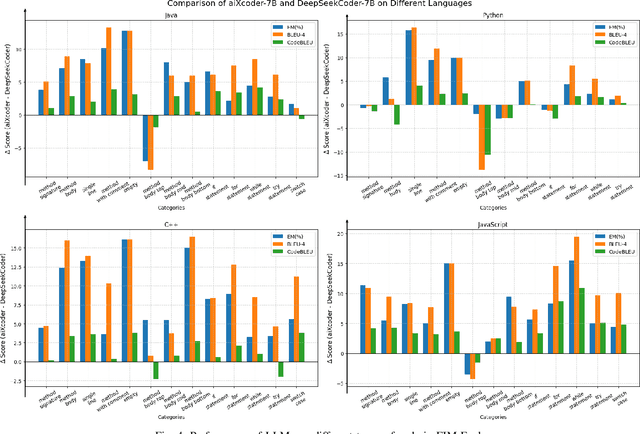
Large Language Models (LLMs) have been widely used in code completion, and researchers are focusing on scaling up LLMs to improve their accuracy. However, larger LLMs will increase the response time of code completion and decrease the developers' productivity. In this paper, we propose a lightweight and effective LLM for code completion named aiXcoder-7B. Compared to existing LLMs, aiXcoder-7B achieves higher code completion accuracy while having smaller scales (i.e., 7 billion parameters). We attribute the superiority of aiXcoder-7B to three key factors: (1) Multi-objective training. We employ three training objectives, one of which is our proposed Structured Fill-In-the-Middle (SFIM). SFIM considers the syntax structures in code and effectively improves the performance of LLMs for code. (2) Diverse data sampling strategies. They consider inter-file relationships and enhance the capability of LLMs in understanding cross-file contexts. (3) Extensive high-quality data. We establish a rigorous data collection pipeline and consume a total of 1.2 trillion unique tokens for training aiXcoder-7B. This vast volume of data enables aiXcoder-7B to learn a broad distribution of code. We evaluate aiXcoder-7B in five popular code completion benchmarks and a new benchmark collected by this paper. The results show that aiXcoder-7B outperforms the latest six LLMs with similar sizes and even surpasses four larger LLMs (e.g., StarCoder2-15B and CodeLlama-34B), positioning aiXcoder-7B as a lightweight and effective LLM for academia and industry. Finally, we summarize three valuable insights for helping practitioners train the next generations of LLMs for code. aiXcoder-7B has been open-souced and gained significant attention. As of the submission date, aiXcoder-7B has received 2,193 GitHub Stars.
DevEval: A Manually-Annotated Code Generation Benchmark Aligned with Real-World Code Repositories
May 30, 2024How to evaluate the coding abilities of Large Language Models (LLMs) remains an open question. We find that existing benchmarks are poorly aligned with real-world code repositories and are insufficient to evaluate the coding abilities of LLMs. To address the knowledge gap, we propose a new benchmark named DevEval, which has three advances. (1) DevEval aligns with real-world repositories in multiple dimensions, e.g., code distributions and dependency distributions. (2) DevEval is annotated by 13 developers and contains comprehensive annotations (e.g., requirements, original repositories, reference code, and reference dependencies). (3) DevEval comprises 1,874 testing samples from 117 repositories, covering 10 popular domains (e.g., Internet, Database). Based on DevEval, we propose repository-level code generation and evaluate 8 popular LLMs on DevEval (e.g., gpt-4, gpt-3.5, StarCoder 2, DeepSeek Coder, CodeLLaMa). Our experiments reveal these LLMs' coding abilities in real-world code repositories. For example, in our experiments, the highest Pass@1 of gpt-4-turbo is only 53.04%. We also analyze LLMs' failed cases and summarize their shortcomings. We hope DevEval can facilitate the development of LLMs in real code repositories. DevEval, prompts, and LLMs' predictions have been released.
DevEval: Evaluating Code Generation in Practical Software Projects
Jan 26, 2024



How to evaluate Large Language Models (LLMs) in code generation is an open question. Many benchmarks have been proposed but are inconsistent with practical software projects, e.g., unreal program distributions, insufficient dependencies, and small-scale project contexts. Thus, the capabilities of LLMs in practical projects are still unclear. In this paper, we propose a new benchmark named DevEval, aligned with Developers' experiences in practical projects. DevEval is collected through a rigorous pipeline, containing 2,690 samples from 119 practical projects and covering 10 domains. Compared to previous benchmarks, DevEval aligns to practical projects in multiple dimensions, e.g., real program distributions, sufficient dependencies, and enough-scale project contexts. We assess five popular LLMs on DevEval (e.g., gpt-4, gpt-3.5-turbo, CodeLLaMa, and StarCoder) and reveal their actual abilities in code generation. For instance, the highest Pass@1 of gpt-3.5-turbo only is 42 in our experiments. We also discuss the challenges and future directions of code generation in practical projects. We open-source DevEval and hope it can facilitate the development of code generation in practical projects.