 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIllusions in Humans and AI: How Visual Perception Aligns and Diverges
Aug 17, 2025By comparing biological and artificial perception through the lens of illusions, we highlight critical differences in how each system constructs visual reality. Understanding these divergences can inform the development of more robust, interpretable, and human-aligned artificial intelligence (AI) vision systems. In particular, visual illusions expose how human perception is based on contextual assumptions rather than raw sensory data. As artificial vision systems increasingly perform human-like tasks, it is important to ask: does AI experience illusions, too? Does it have unique illusions? This article explores how AI responds to classic visual illusions that involve color, size, shape, and motion. We find that some illusion-like effects can emerge in these models, either through targeted training or as by-products of pattern recognition. In contrast, we also identify illusions unique to AI, such as pixel-level sensitivity and hallucinations, that lack human counterparts. By systematically comparing human and AI responses to visual illusions, we uncover alignment gaps and AI-specific perceptual vulnerabilities invisible to human perception. These findings provide insights for future research on vision systems that preserve human-beneficial perceptual biases while avoiding distortions that undermine trust and safety.
Eye-See-You: Reverse Pass-Through VR and Head Avatars
May 24, 2025Virtual Reality (VR) headsets, while integral to the evolving digital ecosystem, present a critical challenge: the occlusion of users' eyes and portions of their faces, which hinders visual communication and may contribute to social isolation. To address this, we introduce RevAvatar, an innovative framework that leverages AI methodologies to enable reverse pass-through technology, fundamentally transforming VR headset design and interaction paradigms. RevAvatar integrates state-of-the-art generative models and multimodal AI techniques to reconstruct high-fidelity 2D facial images and generate accurate 3D head avatars from partially observed eye and lower-face regions. This framework represents a significant advancement in AI4Tech by enabling seamless interaction between virtual and physical environments, fostering immersive experiences such as VR meetings and social engagements. Additionally, we present VR-Face, a novel dataset comprising 200,000 samples designed to emulate diverse VR-specific conditions, including occlusions, lighting variations, and distortions. By addressing fundamental limitations in current VR systems, RevAvatar exemplifies the transformative synergy between AI and next-generation technologies, offering a robust platform for enhancing human connection and interaction in virtual environments.
Beyond End-to-End VLMs: Leveraging Intermediate Text Representations for Superior Flowchart Understanding
Dec 21, 2024



Flowcharts are typically presented as images, driving the trend of using vision-language models (VLMs) for end-to-end flowchart understanding. However, two key challenges arise: (i) Limited controllability--users have minimal influence over the downstream task, as they can only modify input images, while the training of VLMs is often out of reach for most researchers. (ii) Lack of explainability--it is difficult to trace VLM errors to specific causes, such as failures in visual encoding or reasoning. We propose TextFlow, addressing aforementioned issues with two stages: (i) Vision Textualizer--which generates textual representations from flowchart images; and (ii) Textual Reasoner--which performs question-answering based on the text representations. TextFlow offers three key advantages: (i) users can select the type of text representations (e.g., Graphviz, Mermaid, PlantUML), or further convert them into executable graph object to call tools, enhancing performance and controllability; (ii) it improves explainability by helping to attribute errors more clearly to visual or textual processing components; and (iii) it promotes the modularization of the solution, such as allowing advanced LLMs to be used in the Reasoner stage when VLMs underperform in end-to-end fashion. Experiments on the FlowVQA and FlowLearn benchmarks demonstrate TextFlow's state-of-the-art performance as well as its robustness. All code is publicly available.
Self-Supervised Learning for User Localization
Apr 19, 2024



Machine learning techniques have shown remarkable accuracy in localization tasks, but their dependency on vast amounts of labeled data, particularly Channel State Information (CSI) and corresponding coordinates, remains a bottleneck. Self-supervised learning techniques alleviate the need for labeled data, a potential that remains largely untapped and underexplored in existing research. Addressing this gap, we propose a pioneering approach that leverages self-supervised pretraining on unlabeled data to boost the performance of supervised learning for user localization based on CSI. We introduce two pretraining Auto Encoder (AE) models employing Multi Layer Perceptrons (MLPs) and Convolutional Neural Networks (CNNs) to glean representations from unlabeled data via self-supervised learning. Following this, we utilize the encoder portion of the AE models to extract relevant features from labeled data, and finetune an MLP-based Position Estimation Model to accurately deduce user locations. Our experimentation on the CTW-2020 dataset, which features a substantial volume of unlabeled data but limited labeled samples, demonstrates the viability of our approach. Notably, the dataset covers a vast area spanning over 646x943x41 meters, and our approach demonstrates promising results even for such expansive localization tasks.
HI-GAN: Hierarchical Inpainting GAN with Auxiliary Inputs for Combined RGB and Depth Inpainting
Feb 15, 2024



Inpainting involves filling in missing pixels or areas in an image, a crucial technique employed in Mixed Reality environments for various applications, particularly in Diminished Reality (DR) where content is removed from a user's visual environment. Existing methods rely on digital replacement techniques which necessitate multiple cameras and incur high costs. AR devices and smartphones use ToF depth sensors to capture scene depth maps aligned with RGB images. Despite speed and affordability, ToF cameras create imperfect depth maps with missing pixels. To address the above challenges, we propose Hierarchical Inpainting GAN (HI-GAN), a novel approach comprising three GANs in a hierarchical fashion for RGBD inpainting. EdgeGAN and LabelGAN inpaint masked edge and segmentation label images respectively, while CombinedRGBD-GAN combines their latent representation outputs and performs RGB and Depth inpainting. Edge images and particularly segmentation label images as auxiliary inputs significantly enhance inpainting performance by complementary context and hierarchical optimization. We believe we make the first attempt to incorporate label images into inpainting process.Unlike previous approaches requiring multiple sequential models and separate outputs, our work operates in an end-to-end manner, training all three models simultaneously and hierarchically. Specifically, EdgeGAN and LabelGAN are first optimized separately and further optimized inside CombinedRGBD-GAN to enhance inpainting quality. Experiments demonstrate that HI-GAN works seamlessly and achieves overall superior performance compared with existing approaches.
Safety in Traffic Management Systems: A Comprehensive Survey
Aug 11, 2023Traffic management systems play a vital role in ensuring safe and efficient transportation on roads. However, the use of advanced technologies in traffic management systems has introduced new safety challenges. Therefore, it is important to ensure the safety of these systems to prevent accidents and minimize their impact on road users. In this survey, we provide a comprehensive review of the literature on safety in traffic management systems. Specifically, we discuss the different safety issues that arise in traffic management systems, the current state of research on safety in these systems, and the techniques and methods proposed to ensure the safety of these systems. We also identify the limitations of the existing research and suggest future research directions.
* Accepted by MDPI Designs journal, the Special Issue Design and Application of Intelligent Transportation Systems. 30 pages, 6 figures, published on 10 August 2023
A review of Generative Adversarial Networks and its applications in a wide variety of disciplines -- From Medical to Remote Sensing
Oct 01, 2021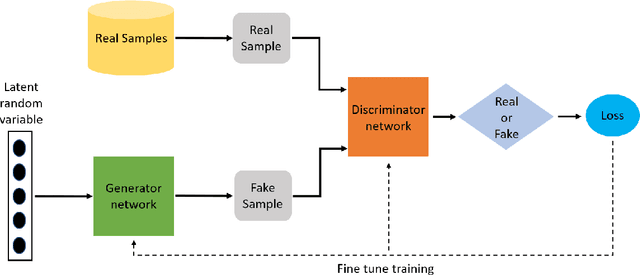
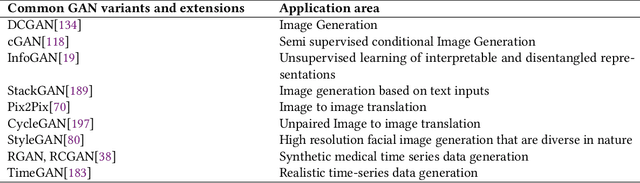
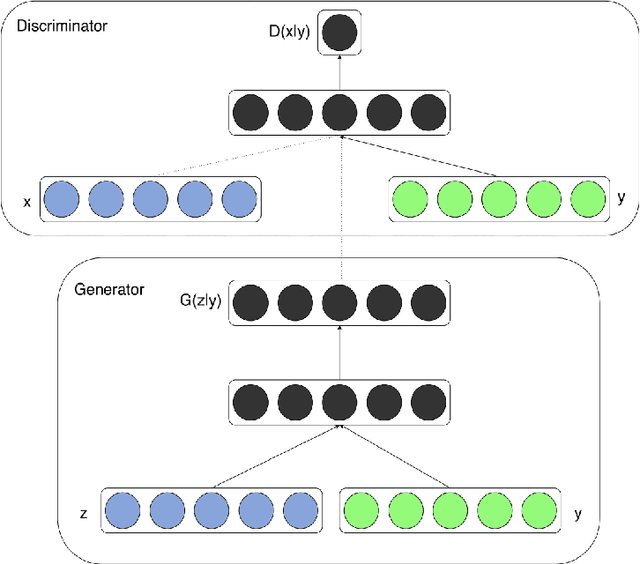
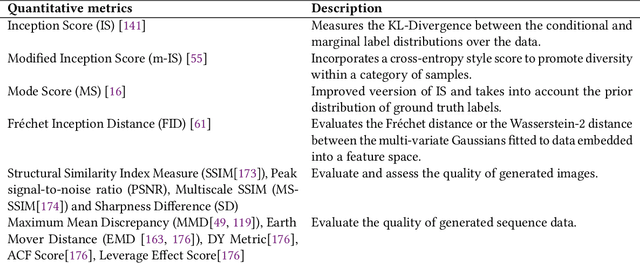
We look into Generative Adversarial Network (GAN), its prevalent variants and applications in a number of sectors. GANs combine two neural networks that compete against one another using zero-sum game theory, allowing them to create much crisper and discrete outputs. GANs can be used to perform image processing, video generation and prediction, among other computer vision applications. GANs can also be utilised for a variety of science-related activities, including protein engineering, astronomical data processing, remote sensing image dehazing, and crystal structure synthesis. Other notable fields where GANs have made gains include finance, marketing, fashion design, sports, and music. Therefore in this article we provide a comprehensive overview of the applications of GANs in a wide variety of disciplines. We first cover the theory supporting GAN, GAN variants, and the metrics to evaluate GANs. Then we present how GAN and its variants can be applied in twelve domains, ranging from STEM fields, such as astronomy and biology, to business fields, such as marketing and finance, and to arts, such as music. As a result, researchers from other fields may grasp how GANs work and apply them to their own study. To the best of our knowledge, this article provides the most comprehensive survey of GAN's applications in different fields.
High Resolution Solar Image Generation using Generative Adversarial Networks
Jun 07, 2021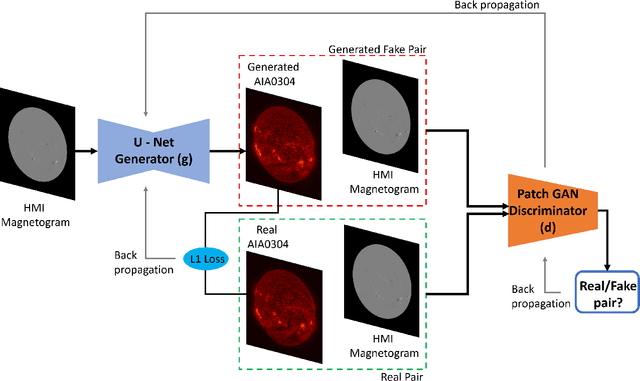
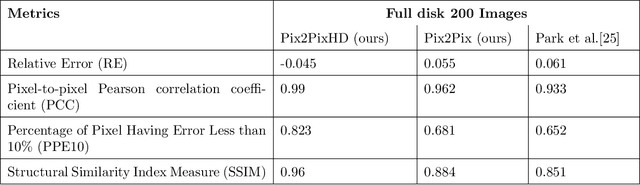
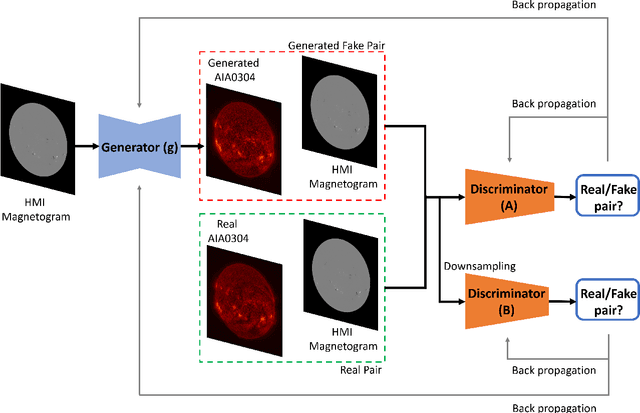

We applied Deep Learning algorithm known as Generative Adversarial Networks (GANs) to perform solar image-to-image translation. That is, from Solar Dynamics Observatory (SDO)/Helioseismic and Magnetic Imager(HMI) line of sight magnetogram images to SDO/Atmospheric Imaging Assembly(AIA) 0304-{\AA} images. The Ultraviolet(UV)/Extreme Ultraviolet(EUV) observations like the SDO/AIA0304-{\AA} images were only made available to scientists in the late 1990s even though the magenetic field observations like the SDO/HMI have been available since the 1970s. Therefore by leveraging Deep Learning algorithms like GANs we can give scientists access to complete datasets for analysis. For generating high resolution solar images we use the Pix2PixHD and Pix2Pix algorithms. The Pix2PixHD algorithm was specifically designed for high resolution image generation tasks, and the Pix2Pix algorithm is by far the most widely used image to image translation algorithm. For training and testing we used the data for the year 2012, 2013 and 2014. The results show that our deep learning models are capable of generating high resolution(1024 x 1024 pixels) AIA0304 images from HMI magnetograms. Specifically, the pixel-to-pixel Pearson Correlation Coefficient of the images generated by Pix2PixHD and original images is as high as 0.99. The number is 0.962 if Pix2Pix is used to generate images. The results we get for our Pix2PixHD model is better than the results obtained by previous works done by others to generate AIA0304 images. Thus, we can use these models to generate AIA0304 images when the AIA0304 data is not available which can be used for understanding space weather and giving researchers the capability to predict solar events such as Solar Flares and Coronal Mass Ejections. As far as we know, our work is the first attempt to leverage Pix2PixHD algorithm for SDO/HMI to SDO/AIA0304 image-to-image translation.