 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Homogeneous Processing Fabric for Matrix-Vector Multiplication and Associative Search Using Ferroelectric Time-Domain Compute-in-Memory
Sep 24, 2022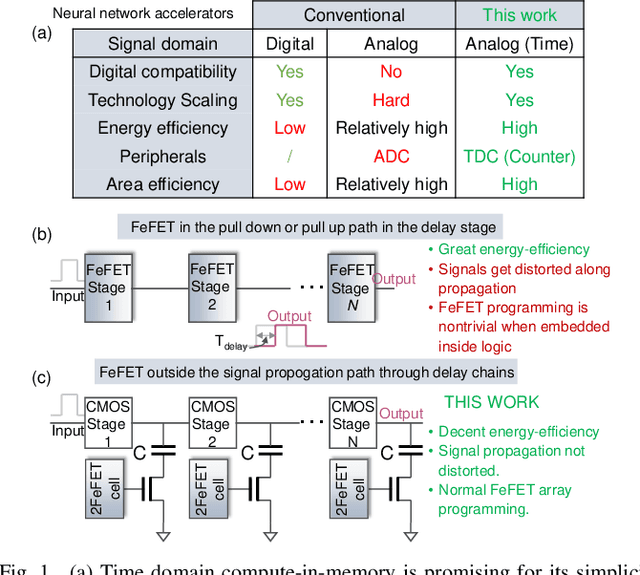
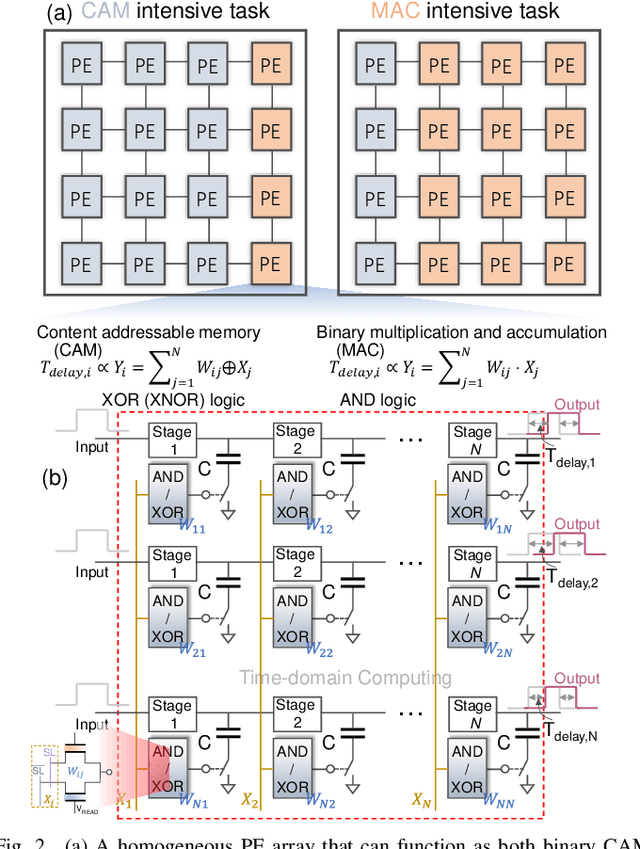
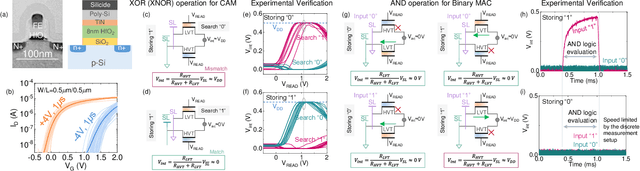
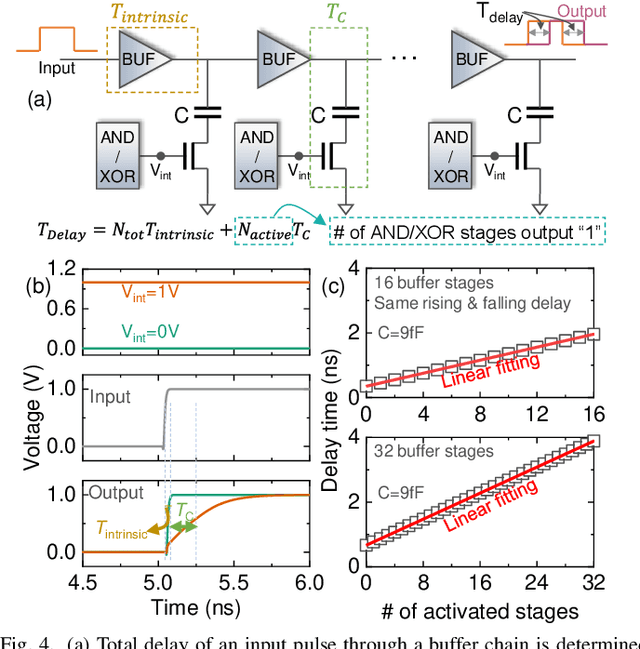
In this work, we propose a ferroelectric FET(FeFET) time-domain compute-in-memory (TD-CiM) array as a homogeneous processing fabric for binary multiplication-accumulation (MAC) and content addressable memory (CAM). We demonstrate that: i) the XOR(XNOR)/AND logic function can be realized using a single cell composed of 2FeFETs connected in series; ii) a two-phase computation in an inverter chain with each stage featuring the XOR/AND cell to control the associated capacitor loading and the computation results of binary MAC and CAM are reflected in the chain output signal delay, illustrating full digital compatibility; iii) comprehensive theoretical and experimental validation of the proposed 2FeFET cell and inverter delay chains and their robustness against FeFET variation; iv) the homogeneous processing fabric is applied in hyperdimensional computing to show dynamic and fine-grain resource allocation to accommodate different tasks requiring varying demands over the binary MAC and CAM resources.
An Ultra-Compact Single FeFET Binary and Multi-Bit Associative Search Engine
Mar 15, 2022Content addressable memory (CAM) is widely used in associative search tasks for its highly parallel pattern matching capability. To accommodate the increasingly complex and data-intensive pattern matching tasks, it is critical to keep improving the CAM density to enhance the performance and area efficiency. In this work, we demonstrate: i) a novel ultra-compact 1FeFET CAM design that enables parallel associative search and in-memory hamming distance calculation; ii) a multi-bit CAM for exact search using the same CAM cell; iii) compact device designs that integrate the series resistor current limiter into the intrinsic FeFET structure to turn the 1FeFET1R into an effective 1FeFET cell; iv) a successful 2-step search operation and a sufficient sensing margin of the proposed binary and multi-bit 1FeFET1R CAM array with sizes of practical interests in both experiments and simulations, given the existing unoptimized FeFET device variation; v) 89.9x speedup and 66.5x energy efficiency improvement over the state-of-the art alignment tools on GPU in accelerating genome pattern matching applications through the hyperdimensional computing paradigm.
Deep Random Forest with Ferroelectric Analog Content Addressable Memory
Oct 06, 2021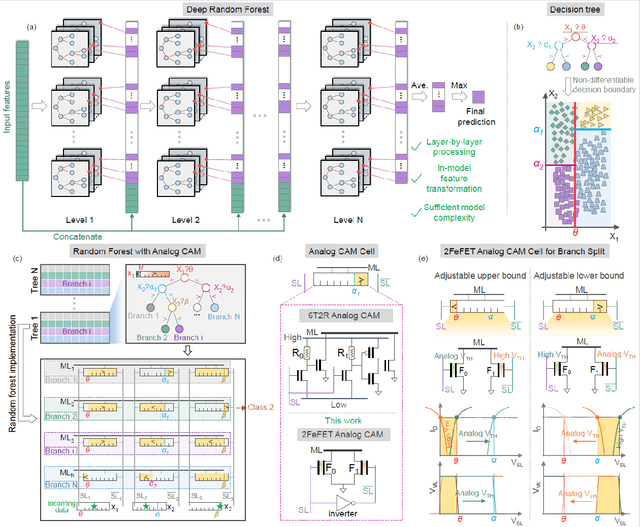
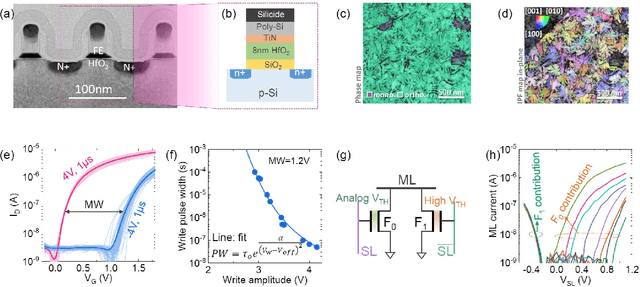
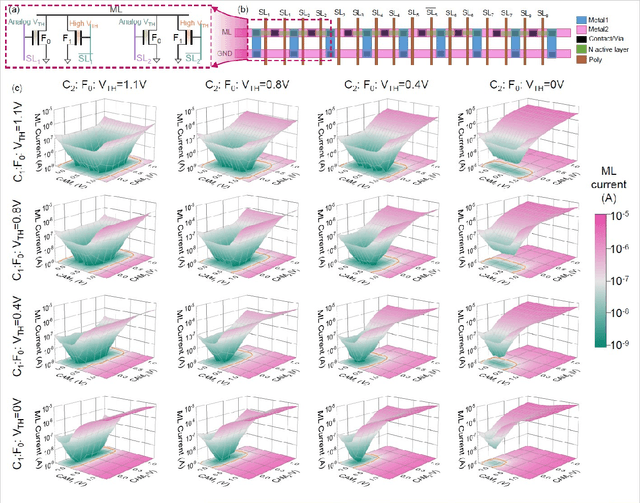
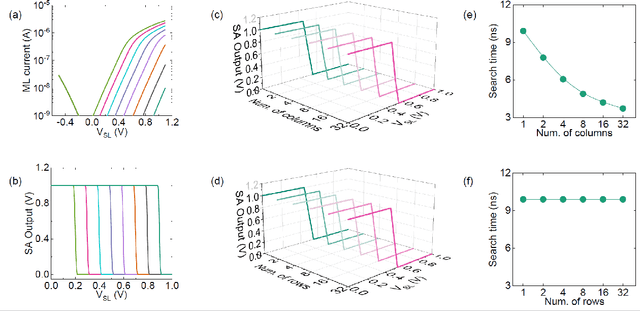
Deep random forest (DRF), which incorporates the core features of deep learning and random forest (RF), exhibits comparable classification accuracy, interpretability, and low memory and computational overhead when compared with deep neural networks (DNNs) in various information processing tasks for edge intelligence. However, the development of efficient hardware to accelerate DRF is lagging behind its DNN counterparts. The key for hardware acceleration of DRF lies in efficiently realizing the branch-split operation at decision nodes when traversing a decision tree. In this work, we propose to implement DRF through simple associative searches realized with ferroelectric analog content addressable memory (ACAM). Utilizing only two ferroelectric field effect transistors (FeFETs), the ultra-compact ACAM cell can perform a branch-split operation with an energy-efficient associative search by storing the decision boundaries as the analog polarization states in an FeFET. The DRF accelerator architecture and the corresponding mapping of the DRF model to the ACAM arrays are presented. The functionality, characteristics, and scalability of the FeFET ACAM based DRF and its robustness against FeFET device non-idealities are validated both in experiments and simulations. Evaluation results show that the FeFET ACAM DRF accelerator exhibits 10^6x/16x and 10^6x/2.5x improvements in terms of energy and latency when compared with other deep random forest hardware implementations on the state-of-the-art CPU/ReRAM, respectively.