 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuromorphic Reinforcement Learning for Quadruped Locomotion Control on Uneven Terrain
May 10, 2026Reinforcement learning (RL) has enabled robust quadruped locomotion over complex terrain, but most learned controllers are trained offline with backpropagation in massively parallel simulation and deployed as fixed policies, limiting adaptation to terrain variation, payload changes, actuator wear, and other real-world conditions under onboard power constraints. Local learning provides a potential path toward energy-aware on-robot adaptation by replacing global backpropagation graphs with updates driven by local neural states, making the learning rule more compatible with neuromorphic and in-memory computing substrates. This work proposes an equilibrium-propagation (EP)-based proximal policy optimization (PPO) framework for uneven-terrain quadruped locomotion. The controller combines a bio-inspired central pattern generator (CPG) policy with a residual postural adjustment policy, while replacing conventional backpropagation-trained policy and value networks with EP-enabled local learning. To train stochastic continuous-control policies with EP, we derive an EP-compatible PPO output-nudging signal and introduce a two-sided ratio clipping mechanism that stabilizes policy updates during relaxation. Experiments on a 12-DoF A1 quadruped show that the proposed controller achieves stable policy convergence in a two-stage uneven terrain locomotion task. Its locomotion performance is comparable to a backpropagation-trained PPO baseline in success rate, velocity tracking, actuator power, and body stability, while improving GPU memory efficiency by 4.3\(\times\) compared with backpropagation through time (BPTT). These results suggest that local equilibrium-based learning can support high-dimensional embodied locomotion and provide an algorithmic foundation for low-power on-robot adaptation and fine-tuning.
Trilinear Compute-in-Memory Architecture for Energy-Efficient Transformer Acceleration
Apr 08, 2026Self-attention in Transformers generates dynamic operands that force conventional Compute-in-Memory (CIM) accelerators into costly non-volatile memory (NVM) reprogramming cycles, degrading throughput and stressing device endurance. Existing solutions either reduce but retain NVM writes through matrix decomposition or sparsity, or move attention computation to digital CMOS at the expense of NVM density. We present TrilinearCIM, a Double-Gate FeFET (DG-FeFET)-based architecture that uses back-gate modulation to realize a three-operand multiply-accumulate primitive for in-memory attention computation without dynamic ferroelectric reprogramming. Evaluated on BERT-base (GLUE) and ViT-base (ImageNet and CIFAR), TrilinearCIM outperforms conventional CIM on seven of nine GLUE tasks while achieving up to 46.6\% energy reduction and 20.4\% latency improvement over conventional FeFET CIM at 37.3\% area overhead. To our knowledge, this is the first architecture to perform complete Transformer attention computation exclusively in NVM cores without runtime reprogramming.
RMAAT: Astrocyte-Inspired Memory Compression and Replay for Efficient Long-Context Transformers
Jan 01, 2026The quadratic complexity of self-attention mechanism presents a significant impediment to applying Transformer models to long sequences. This work explores computational principles derived from astrocytes-glial cells critical for biological memory and synaptic modulation-as a complementary approach to conventional architectural modifications for efficient self-attention. We introduce the Recurrent Memory Augmented Astromorphic Transformer (RMAAT), an architecture integrating abstracted astrocyte functionalities. RMAAT employs a recurrent, segment-based processing strategy where persistent memory tokens propagate contextual information. An adaptive compression mechanism, governed by a novel retention factor derived from simulated astrocyte long-term plasticity (LTP), modulates these tokens. Attention within segments utilizes an efficient, linear-complexity mechanism inspired by astrocyte short-term plasticity (STP). Training is performed using Astrocytic Memory Replay Backpropagation (AMRB), a novel algorithm designed for memory efficiency in recurrent networks. Evaluations on the Long Range Arena (LRA) benchmark demonstrate RMAAT's competitive accuracy and substantial improvements in computational and memory efficiency, indicating the potential of incorporating astrocyte-inspired dynamics into scalable sequence models.
StochEP: Stochastic Equilibrium Propagation for Spiking Convergent Recurrent Neural Networks
Nov 14, 2025Spiking Neural Networks (SNNs) promise energy-efficient, sparse, biologically inspired computation. Training them with Backpropagation Through Time (BPTT) and surrogate gradients achieves strong performance but remains biologically implausible. Equilibrium Propagation (EP) provides a more local and biologically grounded alternative. However, existing EP frameworks, primarily based on deterministic neurons, either require complex mechanisms to handle discontinuities in spiking dynamics or fail to scale beyond simple visual tasks. Inspired by the stochastic nature of biological spiking mechanism and recent hardware trends, we propose a stochastic EP framework that integrates probabilistic spiking neurons into the EP paradigm. This formulation smoothens the optimization landscape, stabilizes training, and enables scalable learning in deep convolutional spiking convergent recurrent neural networks (CRNNs). We provide theoretical guarantees showing that the proposed stochastic EP dynamics approximate deterministic EP under mean-field theory, thereby inheriting its underlying theoretical guarantees. The proposed framework narrows the gap to both BPTT-trained SNNs and EP-trained non-spiking CRNNs in vision benchmarks while preserving locality, highlighting stochastic EP as a promising direction for neuromorphic and on-chip learning.
Neuromorphic Cybersecurity with Semi-supervised Lifelong Learning
Aug 06, 2025Inspired by the brain's hierarchical processing and energy efficiency, this paper presents a Spiking Neural Network (SNN) architecture for lifelong Network Intrusion Detection System (NIDS). The proposed system first employs an efficient static SNN to identify potential intrusions, which then activates an adaptive dynamic SNN responsible for classifying the specific attack type. Mimicking biological adaptation, the dynamic classifier utilizes Grow When Required (GWR)-inspired structural plasticity and a novel Adaptive Spike-Timing-Dependent Plasticity (Ad-STDP) learning rule. These bio-plausible mechanisms enable the network to learn new threats incrementally while preserving existing knowledge. Tested on the UNSW-NB15 benchmark in a continual learning setting, the architecture demonstrates robust adaptation, reduced catastrophic forgetting, and achieves $85.3$\% overall accuracy. Furthermore, simulations using the Intel Lava framework confirm high operational sparsity, highlighting the potential for low-power deployment on neuromorphic hardware.
Dendritic Computing with Multi-Gate Ferroelectric Field-Effect Transistors
May 02, 2025



Although inspired by neuronal systems in the brain, artificial neural networks generally employ point-neurons, which offer far less computational complexity than their biological counterparts. Neurons have dendritic arbors that connect to different sets of synapses and offer local non-linear accumulation - playing a pivotal role in processing and learning. Inspired by this, we propose a novel neuron design based on a multi-gate ferroelectric field-effect transistor that mimics dendrites. It leverages ferroelectric nonlinearity for local computations within dendritic branches, while utilizing the transistor action to generate the final neuronal output. The branched architecture paves the way for utilizing smaller crossbar arrays in hardware integration, leading to greater efficiency. Using an experimentally calibrated device-circuit-algorithm co-simulation framework, we demonstrate that networks incorporating our dendritic neurons achieve superior performance in comparison to much larger networks without dendrites ($\sim$17$\times$ fewer trainable weight parameters). These findings suggest that dendritic hardware can significantly improve computational efficiency, and learning capacity of neuromorphic systems optimized for edge applications.
Toward Spiking Neural Network Local Learning Modules Resistant to Adversarial Attacks
Apr 11, 2025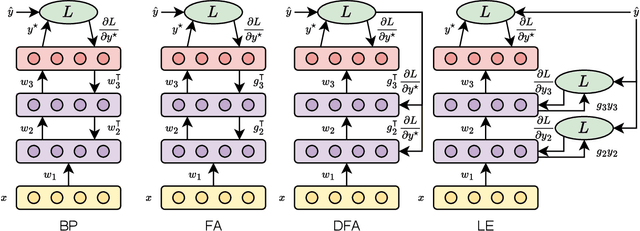
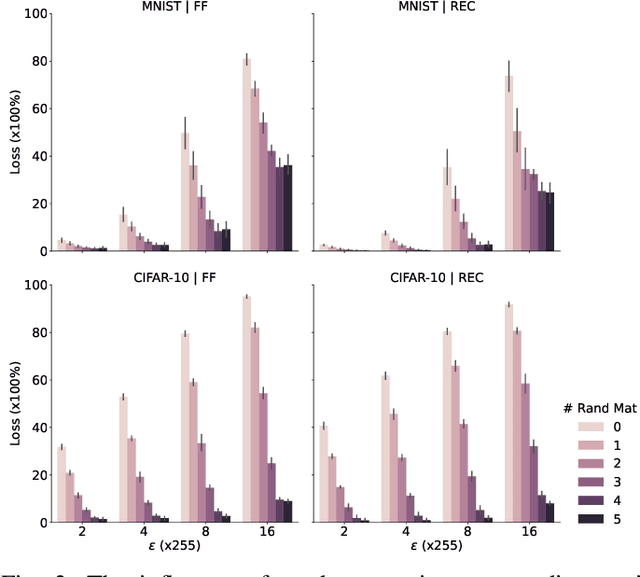
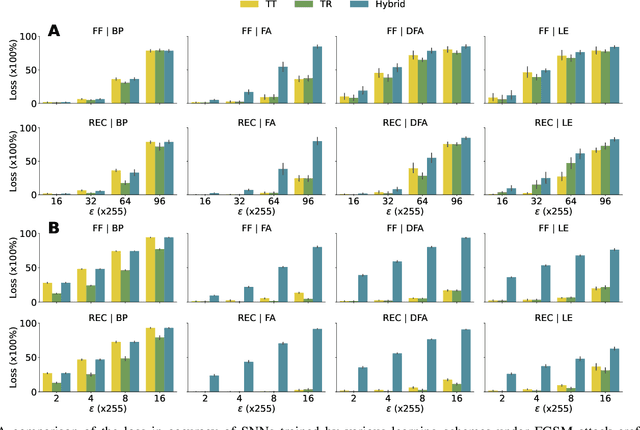
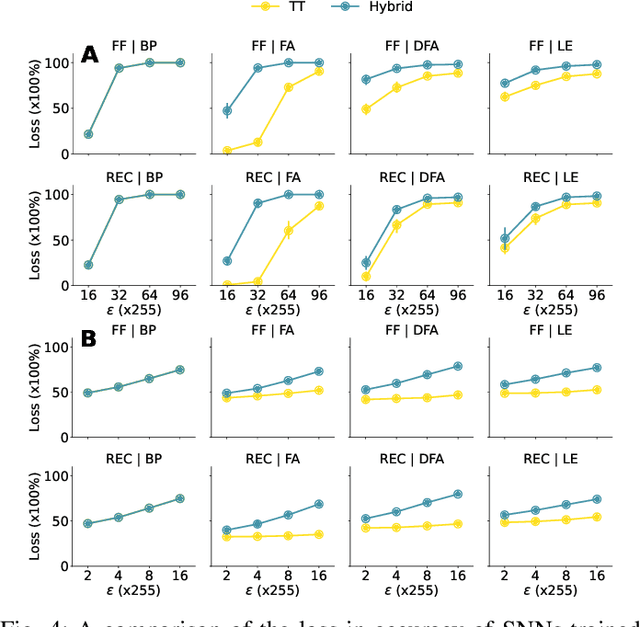
Recent research has shown the vulnerability of Spiking Neural Networks (SNNs) under adversarial examples that are nearly indistinguishable from clean data in the context of frame-based and event-based information. The majority of these studies are constrained in generating adversarial examples using Backpropagation Through Time (BPTT), a gradient-based method which lacks biological plausibility. In contrast, local learning methods, which relax many of BPTT's constraints, remain under-explored in the context of adversarial attacks. To address this problem, we examine adversarial robustness in SNNs through the framework of four types of training algorithms. We provide an in-depth analysis of the ineffectiveness of gradient-based adversarial attacks to generate adversarial instances in this scenario. To overcome these limitations, we introduce a hybrid adversarial attack paradigm that leverages the transferability of adversarial instances. The proposed hybrid approach demonstrates superior performance, outperforming existing adversarial attack methods. Furthermore, the generalizability of the method is assessed under multi-step adversarial attacks, adversarial attacks in black-box FGSM scenarios, and within the non-spiking domain.
Rethinking Spiking Neural Networks as State Space Models
Jun 05, 2024Spiking neural networks (SNNs) are posited as a biologically plausible alternative to conventional neural architectures, with their core computational framework resting on the extensively studied leaky integrate-and-fire (LIF) neuron design. The stateful nature of LIF neurons has spurred ongoing discussions about the ability of SNNs to process sequential data, akin to recurrent neural networks (RNNs). Despite this, there remains a significant gap in the exploration of current SNNs within the realm of long-range dependency tasks. In this study, to extend the analysis of neuronal dynamics beyond simplistic LIF mechanism, we present a novel class of stochastic spiking neuronal model grounded in state space models. We expand beyond the scalar hidden state representation of LIF neurons, which traditionally comprises only the membrane potential, by proposing an n-dimensional hidden state. Additionally, we enable fine-tuned formulation of neuronal dynamics across each layer by introducing learnable parameters, as opposed to the fixed dynamics in LIF neurons. We also develop a robust framework for scaling these neuronal models to deep SNN-based architectures, ensuring efficient parallel training while also adeptly addressing the challenge of non-differentiability of stochastic spiking operation during the backward phase. Our models attain state-of-the-art performance among SNN models across diverse long-range dependency tasks, encompassing the Long Range Arena benchmark, permuted sequential MNIST, and the Speech Command dataset. Moreover, we provide an analysis of the energy efficiency advantages, emphasizing the sparse activity pattern intrinsic to this spiking model.
Exploring Extreme Quantization in Spiking Language Models
May 07, 2024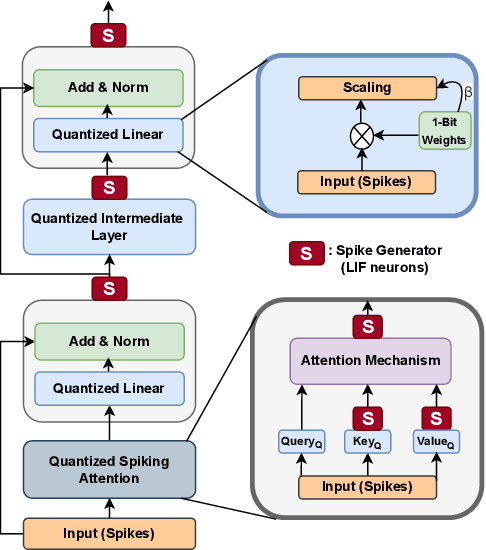
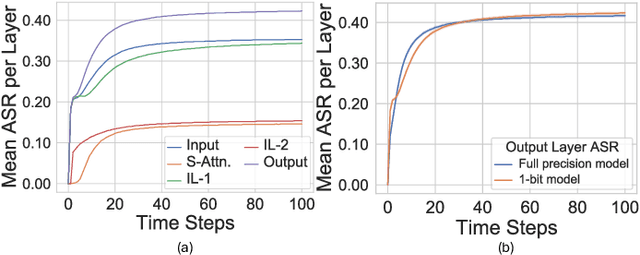
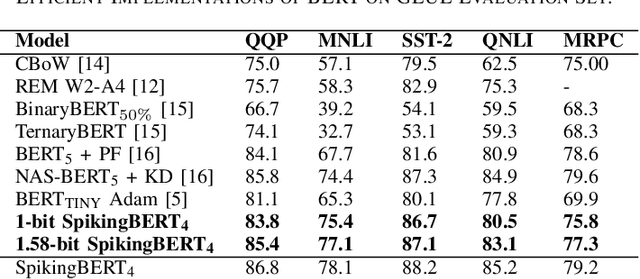
Despite the growing prevalence of large language model (LLM) architectures, a crucial concern persists regarding their energy and power consumption, which still lags far behind the remarkable energy efficiency of the human brain. Recent strides in spiking language models (LM) and transformer architectures aim to address this concern by harnessing the spiking activity of biological neurons to enhance energy/power efficiency. Doubling down on the principles of model quantization and energy efficiency, this paper proposes the development of a novel binary/ternary (1/1.58-bit) spiking LM architecture. Achieving scalability comparable to a deep spiking LM architecture is facilitated by an efficient knowledge distillation technique, wherein knowledge from a non-spiking full-precision "teacher" model is transferred to an extremely weight quantized spiking "student" LM. Our proposed model represents a significant advancement as the first-of-its-kind 1/1.58-bit spiking LM, and its performance is rigorously evaluated on multiple text classification tasks of the GLUE benchmark.
Scaling SNNs Trained Using Equilibrium Propagation to Convolutional Architectures
May 04, 2024Equilibrium Propagation (EP) is a biologically plausible local learning algorithm initially developed for convergent recurrent neural networks (RNNs), where weight updates rely solely on the connecting neuron states across two phases. The gradient calculations in EP have been shown to approximate the gradients computed by Backpropagation Through Time (BPTT) when an infinitesimally small nudge factor is used. This property makes EP a powerful candidate for training Spiking Neural Networks (SNNs), which are commonly trained by BPTT. However, in the spiking domain, previous studies on EP have been limited to architectures involving few linear layers. In this work, for the first time we provide a formulation for training convolutional spiking convergent RNNs using EP, bridging the gap between spiking and non-spiking convergent RNNs. We demonstrate that for spiking convergent RNNs, there is a mismatch in the maximum pooling and its inverse operation, leading to inaccurate gradient estimation in EP. Substituting this with average pooling resolves this issue and enables accurate gradient estimation for spiking convergent RNNs. We also highlight the memory efficiency of EP compared to BPTT. In the regime of SNNs trained by EP, our experimental results indicate state-of-the-art performance on the MNIST and FashionMNIST datasets, with test errors of 0.97% and 8.89%, respectively. These results are comparable to those of convergent RNNs and SNNs trained by BPTT. These findings underscore EP as an optimal choice for on-chip training and a biologically-plausible method for computing error gradients.