 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Extreme Quantization in Spiking Language Models
Paper and Code
May 07, 2024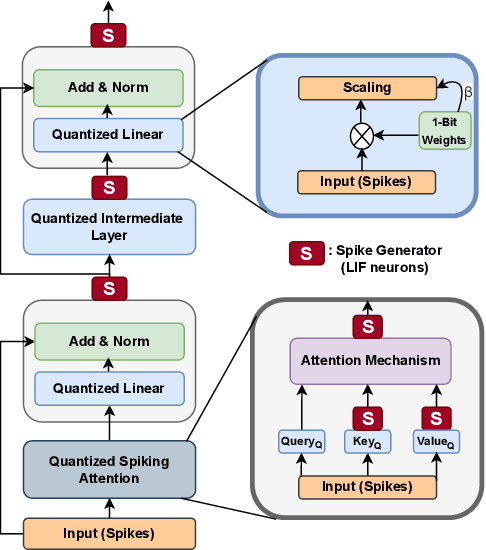
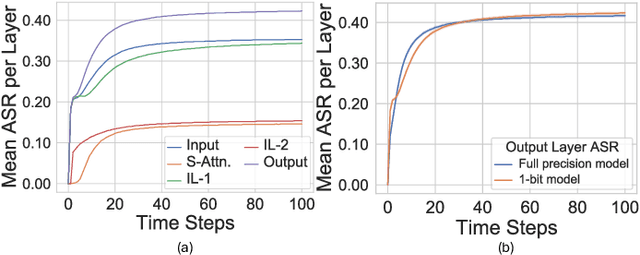
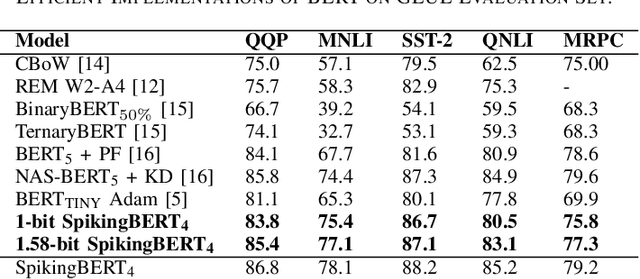
Despite the growing prevalence of large language model (LLM) architectures, a crucial concern persists regarding their energy and power consumption, which still lags far behind the remarkable energy efficiency of the human brain. Recent strides in spiking language models (LM) and transformer architectures aim to address this concern by harnessing the spiking activity of biological neurons to enhance energy/power efficiency. Doubling down on the principles of model quantization and energy efficiency, this paper proposes the development of a novel binary/ternary (1/1.58-bit) spiking LM architecture. Achieving scalability comparable to a deep spiking LM architecture is facilitated by an efficient knowledge distillation technique, wherein knowledge from a non-spiking full-precision "teacher" model is transferred to an extremely weight quantized spiking "student" LM. Our proposed model represents a significant advancement as the first-of-its-kind 1/1.58-bit spiking LM, and its performance is rigorously evaluated on multiple text classification tasks of the GLUE benchmark.