 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompute-in-Memory Implementation of State Space Models for Event Sequence Processing
Nov 17, 2025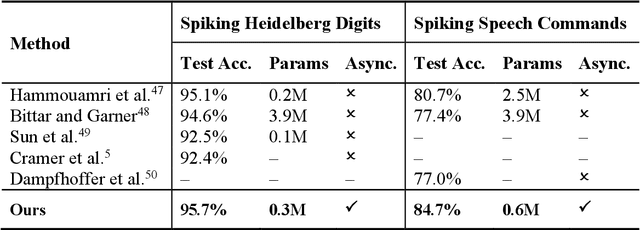
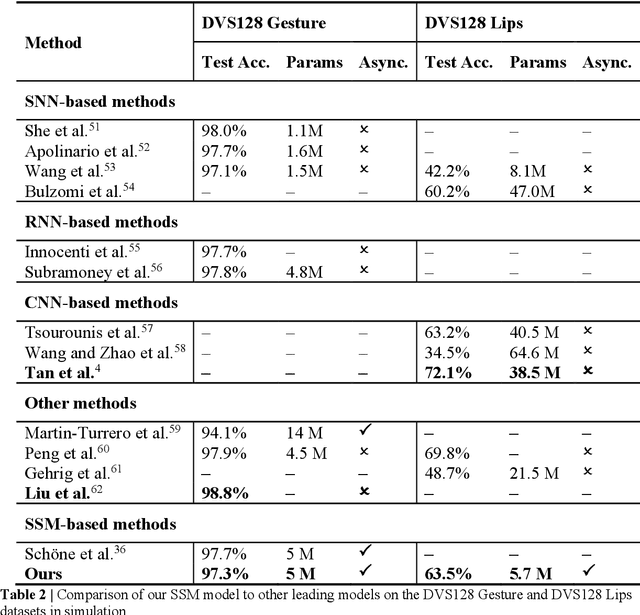
State space models (SSMs) have recently emerged as a powerful framework for long sequence processing, outperforming traditional methods on diverse benchmarks. Fundamentally, SSMs can generalize both recurrent and convolutional networks and have been shown to even capture key functions of biological systems. Here we report an approach to implement SSMs in energy-efficient compute-in-memory (CIM) hardware to achieve real-time, event-driven processing. Our work re-parameterizes the model to function with real-valued coefficients and shared decay constants, reducing the complexity of model mapping onto practical hardware systems. By leveraging device dynamics and diagonalized state transition parameters, the state evolution can be natively implemented in crossbar-based CIM systems combined with memristors exhibiting short-term memory effects. Through this algorithm and hardware co-design, we show the proposed system offers both high accuracy and high energy efficiency while supporting fully asynchronous processing for event-based vision and audio tasks.
Neuromorphic Cybersecurity with Semi-supervised Lifelong Learning
Aug 06, 2025Inspired by the brain's hierarchical processing and energy efficiency, this paper presents a Spiking Neural Network (SNN) architecture for lifelong Network Intrusion Detection System (NIDS). The proposed system first employs an efficient static SNN to identify potential intrusions, which then activates an adaptive dynamic SNN responsible for classifying the specific attack type. Mimicking biological adaptation, the dynamic classifier utilizes Grow When Required (GWR)-inspired structural plasticity and a novel Adaptive Spike-Timing-Dependent Plasticity (Ad-STDP) learning rule. These bio-plausible mechanisms enable the network to learn new threats incrementally while preserving existing knowledge. Tested on the UNSW-NB15 benchmark in a continual learning setting, the architecture demonstrates robust adaptation, reduced catastrophic forgetting, and achieves $85.3$\% overall accuracy. Furthermore, simulations using the Intel Lava framework confirm high operational sparsity, highlighting the potential for low-power deployment on neuromorphic hardware.
EAM: Enhancing Anything with Diffusion Transformers for Blind Super-Resolution
May 08, 2025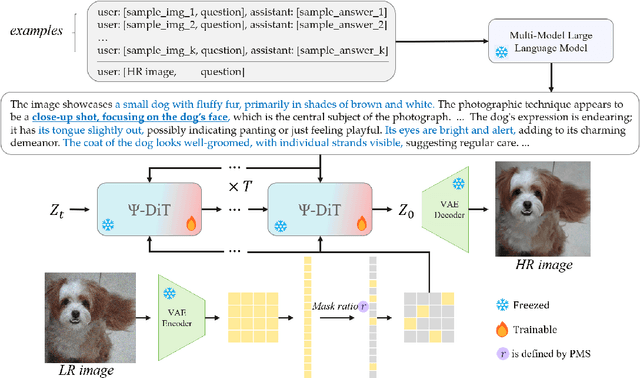
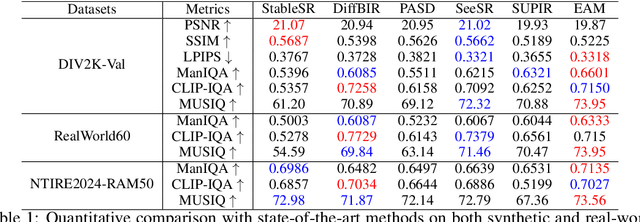
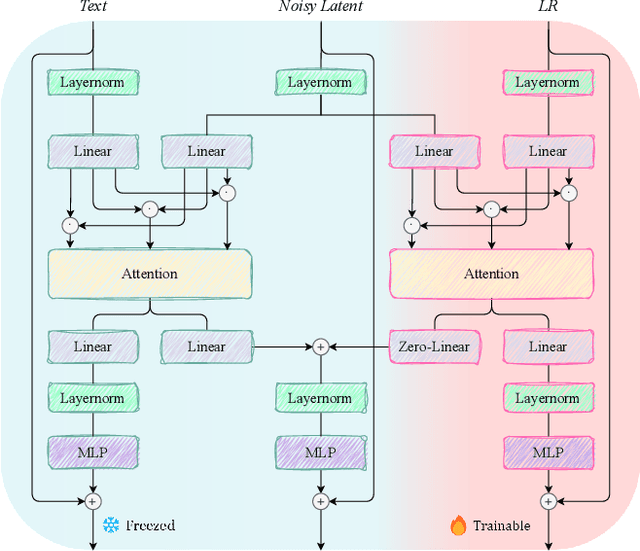

Utilizing pre-trained Text-to-Image (T2I) diffusion models to guide Blind Super-Resolution (BSR) has become a predominant approach in the field. While T2I models have traditionally relied on U-Net architectures, recent advancements have demonstrated that Diffusion Transformers (DiT) achieve significantly higher performance in this domain. In this work, we introduce Enhancing Anything Model (EAM), a novel BSR method that leverages DiT and outperforms previous U-Net-based approaches. We introduce a novel block, $\Psi$-DiT, which effectively guides the DiT to enhance image restoration. This block employs a low-resolution latent as a separable flow injection control, forming a triple-flow architecture that effectively leverages the prior knowledge embedded in the pre-trained DiT. To fully exploit the prior guidance capabilities of T2I models and enhance their generalization in BSR, we introduce a progressive Masked Image Modeling strategy, which also reduces training costs. Additionally, we propose a subject-aware prompt generation strategy that employs a robust multi-modal model in an in-context learning framework. This strategy automatically identifies key image areas, provides detailed descriptions, and optimizes the utilization of T2I diffusion priors. Our experiments demonstrate that EAM achieves state-of-the-art results across multiple datasets, outperforming existing methods in both quantitative metrics and visual quality.
Stochastic Spiking Neural Networks with First-to-Spike Coding
Apr 26, 2024
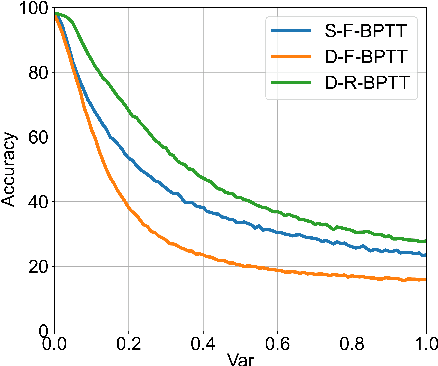


Spiking Neural Networks (SNNs), recognized as the third generation of neural networks, are known for their bio-plausibility and energy efficiency, especially when implemented on neuromorphic hardware. However, the majority of existing studies on SNNs have concentrated on deterministic neurons with rate coding, a method that incurs substantial computational overhead due to lengthy information integration times and fails to fully harness the brain's probabilistic inference capabilities and temporal dynamics. In this work, we explore the merger of novel computing and information encoding schemes in SNN architectures where we integrate stochastic spiking neuron models with temporal coding techniques. Through extensive benchmarking with other deterministic SNNs and rate-based coding, we investigate the tradeoffs of our proposal in terms of accuracy, inference latency, spiking sparsity, energy consumption, and robustness. Our work is the first to extend the scalability of direct training approaches of stochastic SNNs with temporal encoding to VGG architectures and beyond-MNIST datasets.
Benchmarking Spiking Neural Network Learning Methods with Varying Locality
Feb 01, 2024



Spiking Neural Networks (SNNs), providing more realistic neuronal dynamics, have shown to achieve performance comparable to Artificial Neural Networks (ANNs) in several machine learning tasks. Information is processed as spikes within SNNs in an event-based mechanism that significantly reduces energy consumption. However, training SNNs is challenging due to the non-differentiable nature of the spiking mechanism. Traditional approaches, such as Backpropagation Through Time (BPTT), have shown effectiveness but comes with additional computational and memory costs and are biologically implausible. In contrast, recent works propose alternative learning methods with varying degrees of locality, demonstrating success in classification tasks. In this work, we show that these methods share similarities during the training process, while they present a trade-off between biological plausibility and performance. Further, this research examines the implicitly recurrent nature of SNNs and investigates the influence of addition of explicit recurrence to SNNs. We experimentally prove that the addition of explicit recurrent weights enhances the robustness of SNNs. We also investigate the performance of local learning methods under gradient and non-gradient based adversarial attacks.
Deep Unsupervised Learning Using Spike-Timing-Dependent Plasticity
Jul 08, 2023Spike-Timing-Dependent Plasticity (STDP) is an unsupervised learning mechanism for Spiking Neural Networks (SNNs) that has received significant attention from the neuromorphic hardware community. However, scaling such local learning techniques to deeper networks and large-scale tasks has remained elusive. In this work, we investigate a Deep-STDP framework where a convolutional network is trained in tandem with pseudo-labels generated by the STDP clustering process on the network outputs. We achieve $24.56\%$ higher accuracy and $3.5\times$ faster convergence speed at iso-accuracy on a 10-class subset of the Tiny ImageNet dataset in contrast to a $k$-means clustering approach.
On the Self-Repair Role of Astrocytes in STDP Enabled Unsupervised SNNs
Sep 08, 2020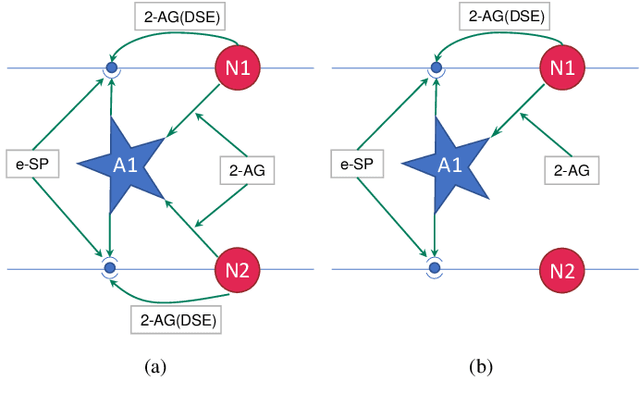
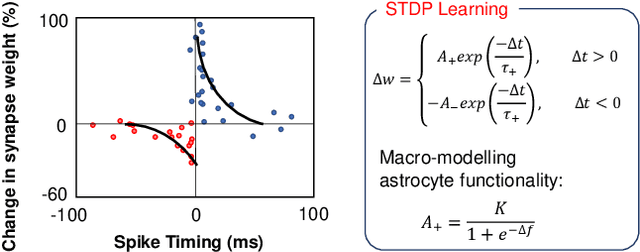
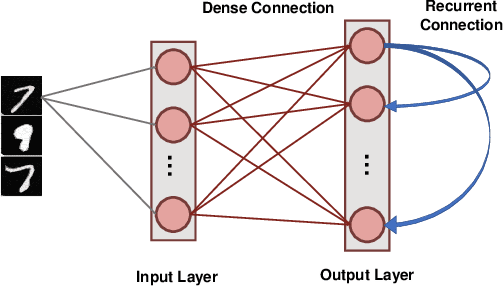
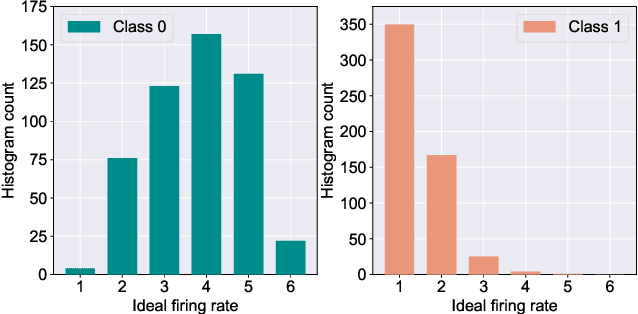
Neuromorphic computing has recently emerged as a disruptive computational paradigm that attempts to emulate various facets of the underlying structure and functionalities of the brain in the algorithm and hardware design of next-generation machine learning platforms. This work goes beyond the focus of current neuromorphic computing architectures on computational models for neuron and synapse to examine other computational units of the biological brain that might contribute to cognition and especially self-repair. We draw inspiration and insights from computational neuroscience regarding functionalities of glial cells and explore their role in the fault-tolerant capacity of Spiking Neural Networks (SNNs) trained in an unsupervised fashion using Spike-Timing Dependent Plasticity (STDP). We characterize the degree of self-repair that can be enabled in such networks with varying degree of faults ranging from 50% - 90% and evaluate our proposal on the MNIST and Fashion-MNIST datasets.
Exploring the Connection Between Binary and Spiking Neural Networks
Feb 24, 2020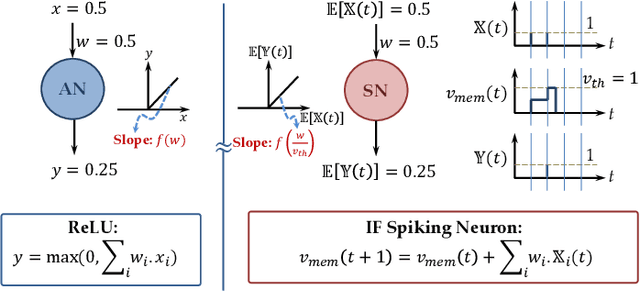
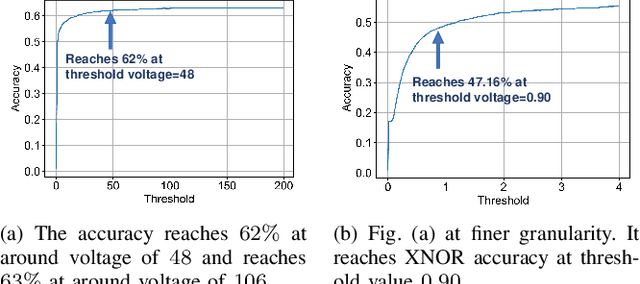
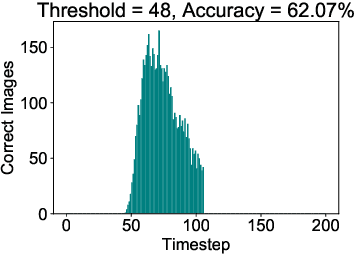
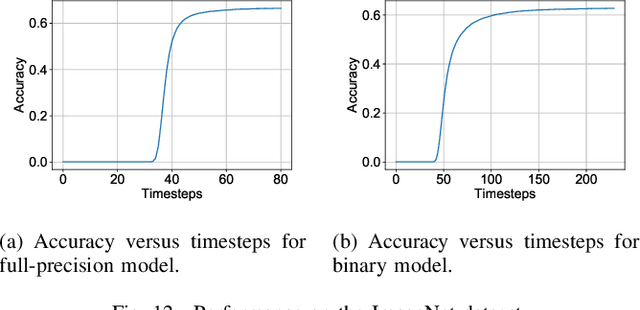
On-chip edge intelligence has necessitated the exploration of algorithmic techniques to reduce the compute requirements of current machine learning frameworks. This work aims to bridge the recent algorithmic progress in training Binary Neural Networks and Spiking Neural Networks - both of which are driven by the same motivation and yet synergies between the two have not been fully explored. We show that training Spiking Neural Networks in the extreme quantization regime results in near full precision accuracies on large-scale datasets like CIFAR-$100$ and ImageNet. An important implication of this work is that Binary Spiking Neural Networks can be enabled by "In-Memory" hardware accelerators catered for Binary Neural Networks without suffering any accuracy degradation due to binarization. We utilize standard training techniques for non-spiking networks to generate our spiking networks by conversion process and also perform an extensive empirical analysis and explore simple design-time and run-time optimization techniques for reducing inference latency of spiking networks (both for binary and full-precision models) by an order of magnitude over prior work.
Exploiting Oxide Based Resistive RAM Variability for Bayesian Neural Network Hardware Design
Jan 02, 2020
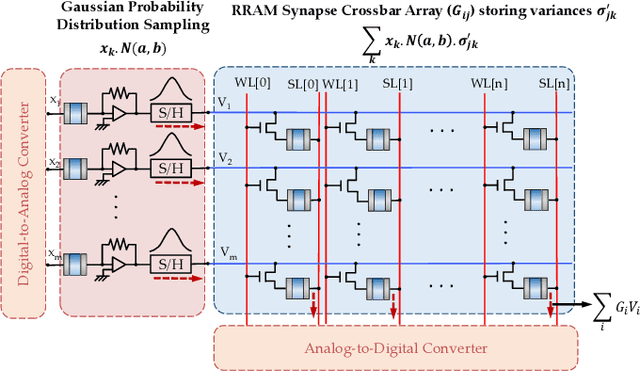

Uncertainty plays a key role in real-time machine learning. As a significant shift from standard deep networks, which does not consider any uncertainty formulation during its training or inference, Bayesian deep networks are being currently investigated where the network is envisaged as an ensemble of plausible models learnt by the Bayes' formulation in response to uncertainties in sensory data. Bayesian deep networks consider each synaptic weight as a sample drawn from a probability distribution with learnt mean and variance. This paper elaborates on a hardware design that exploits cycle-to-cycle variability of oxide based Resistive Random Access Memories (RRAMs) as a means to realize such a probabilistic sampling function, instead of viewing it as a disadvantage.