 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory Faults in Activation-sparse Quantized Deep Neural Networks: Analysis and Mitigation using Sharpness-aware Training
Jun 15, 2024



Improving the hardware efficiency of deep neural network (DNN) accelerators with techniques such as quantization and sparsity enhancement have shown an immense promise. However, their inference accuracy in non-ideal real-world settings (such as in the presence of hardware faults) is yet to be systematically analyzed. In this work, we investigate the impact of memory faults on activation-sparse quantized DNNs (AS QDNNs). We show that a high level of activation sparsity comes at the cost of larger vulnerability to faults, with AS QDNNs exhibiting up to 11.13% lower accuracy than the standard QDNNs. We establish that the degraded accuracy correlates with a sharper minima in the loss landscape for AS QDNNs, which makes them more sensitive to perturbations in the weight values due to faults. Based on this observation, we employ sharpness-aware quantization (SAQ) training to mitigate the impact of memory faults. The AS and standard QDNNs trained with SAQ have up to 19.50% and 15.82% higher inference accuracy, respectively compared to their conventionally trained equivalents. Moreover, we show that SAQ-trained AS QDNNs show higher accuracy in faulty settings than standard QDNNs trained conventionally. Thus, sharpness-aware training can be instrumental in achieving sparsity-related latency benefits without compromising on fault tolerance.
FlatENN: Train Flat for Enhanced Fault Tolerance of Quantized Deep Neural Networks
Dec 29, 2022



Model compression via quantization and sparsity enhancement has gained an immense interest to enable the deployment of deep neural networks (DNNs) in resource-constrained edge environments. Although these techniques have shown promising results in reducing the energy, latency and memory requirements of the DNNs, their performance in non-ideal real-world settings (such as in the presence of hardware faults) is yet to be completely understood. In this paper, we investigate the impact of bit-flip and stuck-at faults on activation-sparse quantized DNNs (QDNNs). We show that a high level of activation sparsity comes at the cost of larger vulnerability to faults. For instance, activation-sparse QDNNs exhibit up to 17.32% lower accuracy than the standard QDNNs. We also establish that one of the major cause of the degraded accuracy is sharper minima in the loss landscape for activation-sparse QDNNs, which makes them more sensitive to perturbations in the weight values due to faults. Based on this observation, we propose the mitigation of the impact of faults by employing a sharpness-aware quantization (SAQ) training scheme. The activation-sparse and standard QDNNs trained with SAQ have up to 36.71% and 24.76% higher inference accuracy, respectively compared to their conventionally trained equivalents. Moreover, we show that SAQ-trained activation-sparse QDNNs show better accuracy in faulty settings than standard QDNNs trained conventionally. Thus the proposed technique can be instrumental in achieving sparsity-related energy/latency benefits without compromising on fault tolerance.
Exploiting Oxide Based Resistive RAM Variability for Bayesian Neural Network Hardware Design
Jan 02, 2020
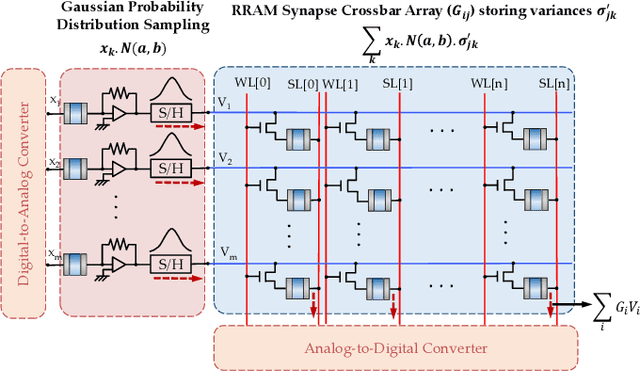

Uncertainty plays a key role in real-time machine learning. As a significant shift from standard deep networks, which does not consider any uncertainty formulation during its training or inference, Bayesian deep networks are being currently investigated where the network is envisaged as an ensemble of plausible models learnt by the Bayes' formulation in response to uncertainties in sensory data. Bayesian deep networks consider each synaptic weight as a sample drawn from a probability distribution with learnt mean and variance. This paper elaborates on a hardware design that exploits cycle-to-cycle variability of oxide based Resistive Random Access Memories (RRAMs) as a means to realize such a probabilistic sampling function, instead of viewing it as a disadvantage.