 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight True In-Pixel Encryption with FeFET Enabled Pixel Design for Secure Imaging
Apr 06, 2026Ensuring end-to-end security in image sensors has become essential as visual data can be exposed through multiple stages of the imaging pipeline. Advanced protection requires encryption to occur before pixel values appear on any readout lines. This work introduces a secure pixel sensor (SecurePix), a compact CMOS-compatible pixel architecture that performs true in-pixel encryption using a symmetric key realized through programmable, non-volatile multidomain polarization states of a ferroelectric field-effect transistor. The pixel and array operations are designed and simulated in HSPICE, while a 45 nm CMOS process design kit is used for layout drawing. The resulting layout confirms a pixel pitch of 2.33 x 3.01 um^2. Each pixel's non-volatile programming level defines its analog transfer characteristic, enabling the photodiode voltage to be converted into an encrypted analog output within the pixel. Full-image evaluation shows that ResNet-18 recognition accuracy drops from 99.29 percent to 9.58 percent on MNIST and from 91.33 percent to 6.98 percent on CIFAR-10 after encryption, indicating strong resistance to neural-network-based inference. Lookup-table-based inverse mapping enables recovery for authorized receivers using the same symmetric key. Based on HSPICE simulation, the SecurePix achieves a per-pixel programming power-delay product of 17 uW us and a per-pixel sensing power-delay product of 1.25 uW us, demonstrating low-overhead hardware-level protection.
Memory Faults in Activation-sparse Quantized Deep Neural Networks: Analysis and Mitigation using Sharpness-aware Training
Jun 15, 2024



Improving the hardware efficiency of deep neural network (DNN) accelerators with techniques such as quantization and sparsity enhancement have shown an immense promise. However, their inference accuracy in non-ideal real-world settings (such as in the presence of hardware faults) is yet to be systematically analyzed. In this work, we investigate the impact of memory faults on activation-sparse quantized DNNs (AS QDNNs). We show that a high level of activation sparsity comes at the cost of larger vulnerability to faults, with AS QDNNs exhibiting up to 11.13% lower accuracy than the standard QDNNs. We establish that the degraded accuracy correlates with a sharper minima in the loss landscape for AS QDNNs, which makes them more sensitive to perturbations in the weight values due to faults. Based on this observation, we employ sharpness-aware quantization (SAQ) training to mitigate the impact of memory faults. The AS and standard QDNNs trained with SAQ have up to 19.50% and 15.82% higher inference accuracy, respectively compared to their conventionally trained equivalents. Moreover, we show that SAQ-trained AS QDNNs show higher accuracy in faulty settings than standard QDNNs trained conventionally. Thus, sharpness-aware training can be instrumental in achieving sparsity-related latency benefits without compromising on fault tolerance.
Reimagining Sense Amplifiers: Harnessing Phase Transition Materials for Current and Voltage Sensing
Aug 30, 2023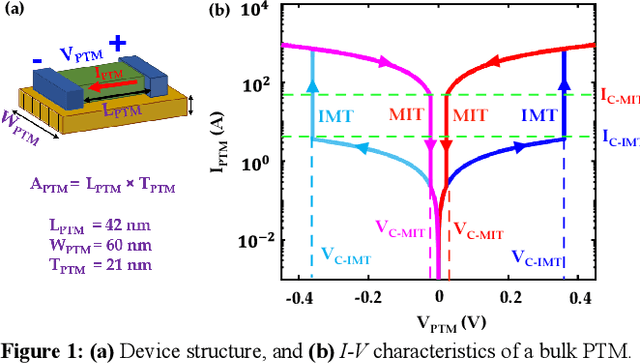
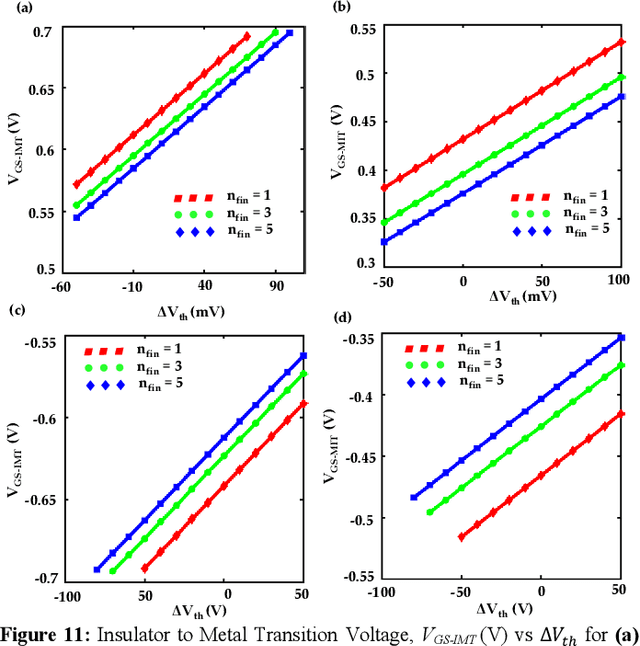
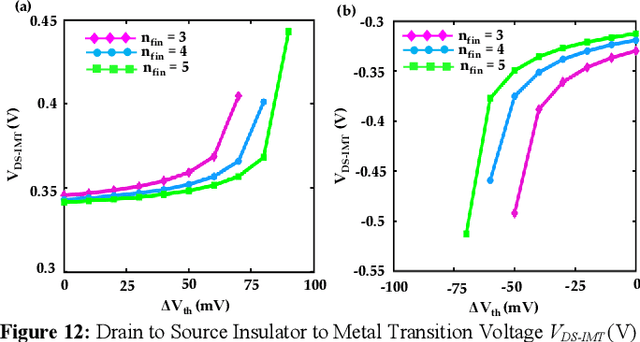
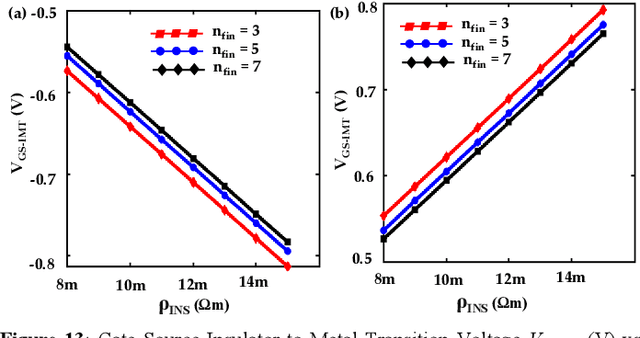
Energy-efficient sense amplifier (SA) circuits are essential for reliable detection of stored memory states in emerging memory systems. In this work, we present four novel sense amplifier (SA) topologies based on phase transition material (PTM) tailored for non-volatile memory applications. We utilize the abrupt switching and volatile hysteretic characteristics of PTMs which enables efficient and fast sensing operation in our proposed SA topologies. We provide comprehensive details of their functionality and assess how process variations impact their performance metrics. Our proposed sense amplifier topologies manifest notable performance enhancement. We achieve a ~67% reduction in sensing delay and a ~80% decrease in sensing power for current sensing. For voltage sensing, we achieve a ~75% reduction in sensing delay and a ~33% decrease in sensing power. Moreover, the proposed SA topologies exhibit improved variation robustness compared to conventional SAs. We also scrutinize the dependence of transistor mirroring window and PTM transition voltages on several device parameters to determine the optimum operating conditions and stance of tunability for each of the proposed SA topologies.
FlatENN: Train Flat for Enhanced Fault Tolerance of Quantized Deep Neural Networks
Dec 29, 2022



Model compression via quantization and sparsity enhancement has gained an immense interest to enable the deployment of deep neural networks (DNNs) in resource-constrained edge environments. Although these techniques have shown promising results in reducing the energy, latency and memory requirements of the DNNs, their performance in non-ideal real-world settings (such as in the presence of hardware faults) is yet to be completely understood. In this paper, we investigate the impact of bit-flip and stuck-at faults on activation-sparse quantized DNNs (QDNNs). We show that a high level of activation sparsity comes at the cost of larger vulnerability to faults. For instance, activation-sparse QDNNs exhibit up to 17.32% lower accuracy than the standard QDNNs. We also establish that one of the major cause of the degraded accuracy is sharper minima in the loss landscape for activation-sparse QDNNs, which makes them more sensitive to perturbations in the weight values due to faults. Based on this observation, we propose the mitigation of the impact of faults by employing a sharpness-aware quantization (SAQ) training scheme. The activation-sparse and standard QDNNs trained with SAQ have up to 36.71% and 24.76% higher inference accuracy, respectively compared to their conventionally trained equivalents. Moreover, we show that SAQ-trained activation-sparse QDNNs show better accuracy in faulty settings than standard QDNNs trained conventionally. Thus the proposed technique can be instrumental in achieving sparsity-related energy/latency benefits without compromising on fault tolerance.
TiM-DNN: Ternary in-Memory accelerator for Deep Neural Networks
Sep 30, 2019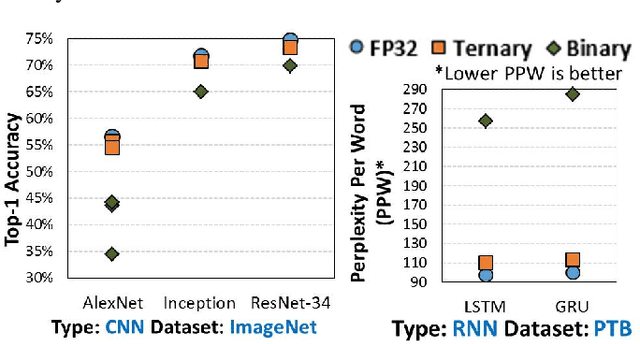
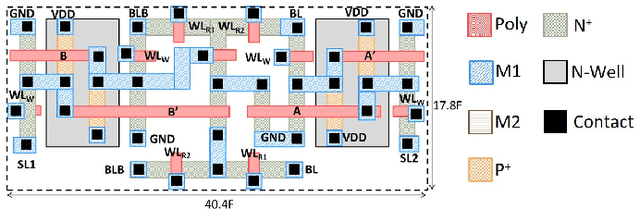
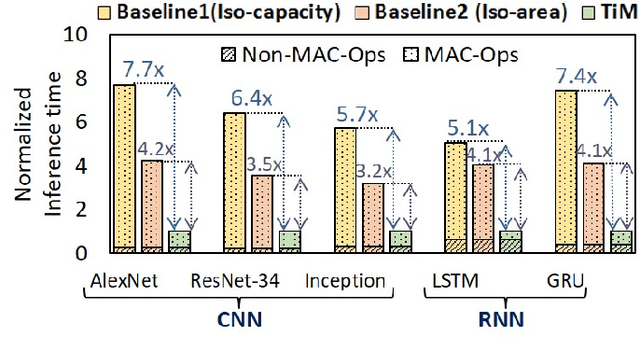

The use of lower precision has emerged as a popular technique to optimize the compute and storage requirements of complex Deep Neural Networks (DNNs). In the quest for lower precision, recent studies have shown that ternary DNNs, which represent weights and activations by signed ternary values, represent a promising sweet spot, and achieve accuracy close to full-precision networks on complex tasks such as language modeling and image classification. We propose TiM-DNN, a programmable, in-memory accelerator that is specifically designed to execute ternary DNNs. TiM-DNN supports various ternary representations including unweighted (-1,0,1), symmetric weighted (-a,0,a), and asymmetric weighted (-a,0,b) ternary systems. TiM-DNN is designed using TiM tiles -- specialized memory arrays that perform massively parallel signed vector-matrix multiplications on ternary values with a single access. TiM tiles are in turn composed of Ternary Processing Cells (TPCs), new bit-cells that function as both ternary storage units and signed scalar multiplication units. We evaluate an implementation of TiM-DNN in 32nm technology using an architectural simulator calibrated with SPICE simulations and RTL synthesis. TiM-DNN achieves a peak performance of 114 TOPs/s, consumes 0.9W power, and occupies 1.96mm2 chip area, representing a 300X and 388X improvement in TOPS/W and TOPS/mm2, respectively, compared to a state-of-the-art NVIDIA Tesla V100 GPU. In comparison to popular DNN accelerators, TiM-DNN achieves 55.2X-240X and 160X-291X improvement in TOPS/W and TOPS/mm2, respectively. We compare TiM-DNN with a well-optimized near-memory accelerator for ternary DNNs across a suite of state-of-the-art DNN benchmarks including both deep convolutional and recurrent neural networks, demonstrating 3.9x-4.7x improvement in system-level energy and 3.2x-4.2x speedup.