 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Rank Plus Sparse Matrix Transfer Learning under Growing Representations and Ambient Dimensions
Jan 29, 2026Learning systems often expand their ambient features or latent representations over time, embedding earlier representations into larger spaces with limited new latent structure. We study transfer learning for structured matrix estimation under simultaneous growth of the ambient dimension and the intrinsic representation, where a well-estimated source task is embedded as a subspace of a higher-dimensional target task. We propose a general transfer framework in which the target parameter decomposes into an embedded source component, low-dimensional low-rank innovations, and sparse edits, and develop an anchored alternating projection estimator that preserves transferred subspaces while estimating only low-dimensional innovations and sparse modifications. We establish deterministic error bounds that separate target noise, representation growth, and source estimation error, yielding strictly improved rates when rank and sparsity increments are small. We demonstrate the generality of the framework by applying it to two canonical problems. For Markov transition matrix estimation from a single trajectory, we derive end-to-end theoretical guarantees under dependent noise. For structured covariance estimation under enlarged dimensions, we provide complementary theoretical analysis in the appendix and empirically validate consistent transfer gains.
Optimistic Transfer under Task Shift via Bellman Alignment
Jan 29, 2026We study online transfer reinforcement learning (RL) in episodic Markov decision processes, where experience from related source tasks is available during learning on a target task. A fundamental difficulty is that task similarity is typically defined in terms of rewards or transitions, whereas online RL algorithms operate on Bellman regression targets. As a result, naively reusing source Bellman updates introduces systematic bias and invalidates regret guarantees. We identify one-step Bellman alignment as the correct abstraction for transfer in online RL and propose re-weighted targeting (RWT), an operator-level correction that retargets continuation values and compensates for transition mismatch via a change of measure. RWT reduces task mismatch to a fixed one-step correction and enables statistically sound reuse of source data. This alignment yields a two-stage RWT $Q$-learning framework that separates variance reduction from bias correction. Under RKHS function approximation, we establish regret bounds that scale with the complexity of the task shift rather than the target MDP. Empirical results in both tabular and neural network settings demonstrate consistent improvements over single-task learning and naïve pooling, highlighting Bellman alignment as a model-agnostic transfer principle for online RL.
HalluGuard: Demystifying Data-Driven and Reasoning-Driven Hallucinations in LLMs
Jan 26, 2026The reliability of Large Language Models (LLMs) in high-stakes domains such as healthcare, law, and scientific discovery is often compromised by hallucinations. These failures typically stem from two sources: data-driven hallucinations and reasoning-driven hallucinations. However, existing detection methods usually address only one source and rely on task-specific heuristics, limiting their generalization to complex scenarios. To overcome these limitations, we introduce the Hallucination Risk Bound, a unified theoretical framework that formally decomposes hallucination risk into data-driven and reasoning-driven components, linked respectively to training-time mismatches and inference-time instabilities. This provides a principled foundation for analyzing how hallucinations emerge and evolve. Building on this foundation, we introduce HalluGuard, an NTK-based score that leverages the induced geometry and captured representations of the NTK to jointly identify data-driven and reasoning-driven hallucinations. We evaluate HalluGuard on 10 diverse benchmarks, 11 competitive baselines, and 9 popular LLM backbones, consistently achieving state-of-the-art performance in detecting diverse forms of LLM hallucinations.
GENUINE: Graph Enhanced Multi-level Uncertainty Estimation for Large Language Models
Sep 09, 2025Uncertainty estimation is essential for enhancing the reliability of Large Language Models (LLMs), particularly in high-stakes applications. Existing methods often overlook semantic dependencies, relying on token-level probability measures that fail to capture structural relationships within the generated text. We propose GENUINE: Graph ENhanced mUlti-level uncertaINty Estimation for Large Language Models, a structure-aware framework that leverages dependency parse trees and hierarchical graph pooling to refine uncertainty quantification. By incorporating supervised learning, GENUINE effectively models semantic and structural relationships, improving confidence assessments. Extensive experiments across NLP tasks show that GENUINE achieves up to 29% higher AUROC than semantic entropy-based approaches and reduces calibration errors by over 15%, demonstrating the effectiveness of graph-based uncertainty modeling. The code is available at https://github.com/ODYSSEYWT/GUQ.
Non-exchangeable Conformal Prediction for Temporal Graph Neural Networks
Jul 02, 2025Conformal prediction for graph neural networks (GNNs) offers a promising framework for quantifying uncertainty, enhancing GNN reliability in high-stakes applications. However, existing methods predominantly focus on static graphs, neglecting the evolving nature of real-world graphs. Temporal dependencies in graph structure, node attributes, and ground truth labels violate the fundamental exchangeability assumption of standard conformal prediction methods, limiting their applicability. To address these challenges, in this paper, we introduce NCPNET, a novel end-to-end conformal prediction framework tailored for temporal graphs. Our approach extends conformal prediction to dynamic settings, mitigating statistical coverage violations induced by temporal dependencies. To achieve this, we propose a diffusion-based non-conformity score that captures both topological and temporal uncertainties within evolving networks. Additionally, we develop an efficiency-aware optimization algorithm that improves the conformal prediction process, enhancing computational efficiency and reducing coverage violations. Extensive experiments on diverse real-world temporal graphs, including WIKI, REDDIT, DBLP, and IBM Anti-Money Laundering dataset, demonstrate NCPNET's capability to ensure guaranteed coverage in temporal graphs, achieving up to a 31% reduction in prediction set size on the WIKI dataset, significantly improving efficiency compared to state-of-the-art methods. Our data and code are available at https://github.com/ODYSSEYWT/NCPNET.
Judging with Many Minds: Do More Perspectives Mean Less Prejudice?
May 26, 2025LLM-as-Judge has emerged as a scalable alternative to human evaluation, enabling large language models (LLMs) to provide reward signals in trainings. While recent work has explored multi-agent extensions such as multi-agent debate and meta-judging to enhance evaluation quality, the question of how intrinsic biases manifest in these settings remains underexplored. In this study, we conduct a systematic analysis of four diverse bias types: position bias, verbosity bias, chain-of-thought bias, and bandwagon bias. We evaluate these biases across two widely adopted multi-agent LLM-as-Judge frameworks: Multi-Agent-Debate and LLM-as-Meta-Judge. Our results show that debate framework amplifies biases sharply after the initial debate, and this increased bias is sustained in subsequent rounds, while meta-judge approaches exhibit greater resistance. We further investigate the incorporation of PINE, a leading single-agent debiasing method, as a bias-free agent within these systems. The results reveal that this bias-free agent effectively reduces biases in debate settings but provides less benefit in meta-judge scenarios. Our work provides a comprehensive study of bias behavior in multi-agent LLM-as-Judge systems and highlights the need for targeted bias mitigation strategies in collaborative evaluation settings.
Transfer Faster, Price Smarter: Minimax Dynamic Pricing under Cross-Market Preference Shift
May 22, 2025


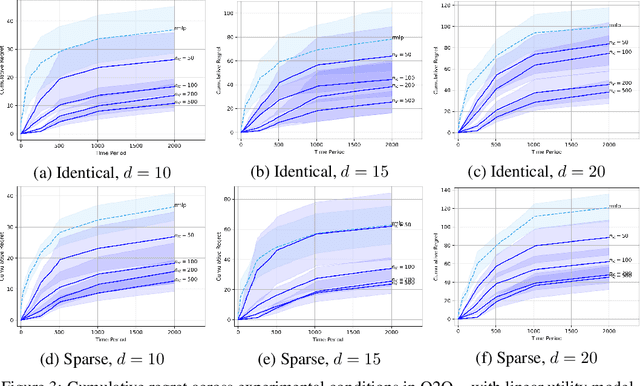
We study contextual dynamic pricing when a target market can leverage K auxiliary markets -- offline logs or concurrent streams -- whose mean utilities differ by a structured preference shift. We propose Cross-Market Transfer Dynamic Pricing (CM-TDP), the first algorithm that provably handles such model-shift transfer and delivers minimax-optimal regret for both linear and non-parametric utility models. For linear utilities of dimension d, where the difference between source- and target-task coefficients is $s_{0}$-sparse, CM-TDP attains regret $\tilde{O}((d*K^{-1}+s_{0})\log T)$. For nonlinear demand residing in a reproducing kernel Hilbert space with effective dimension $\alpha$, complexity $\beta$ and task-similarity parameter $H$, the regret becomes $\tilde{O}\!(K^{-2\alpha\beta/(2\alpha\beta+1)}T^{1/(2\alpha\beta+1)} + H^{2/(2\alpha+1)}T^{1/(2\alpha+1)})$, matching information-theoretic lower bounds up to logarithmic factors. The RKHS bound is the first of its kind for transfer pricing and is of independent interest. Extensive simulations show up to 50% lower cumulative regret and 5 times faster learning relative to single-market pricing baselines. By bridging transfer learning, robust aggregation, and revenue optimization, CM-TDP moves toward pricing systems that transfer faster, price smarter.
Exploring Consistency in Graph Representations:from Graph Kernels to Graph Neural Networks
Oct 31, 2024Graph Neural Networks (GNNs) have emerged as a dominant approach in graph representation learning, yet they often struggle to capture consistent similarity relationships among graphs. While graph kernel methods such as the Weisfeiler-Lehman subtree (WL-subtree) and Weisfeiler-Lehman optimal assignment (WLOA) kernels are effective in capturing similarity relationships, they rely heavily on predefined kernels and lack sufficient non-linearity for more complex data patterns. Our work aims to bridge the gap between neural network methods and kernel approaches by enabling GNNs to consistently capture relational structures in their learned representations. Given the analogy between the message-passing process of GNNs and WL algorithms, we thoroughly compare and analyze the properties of WL-subtree and WLOA kernels. We find that the similarities captured by WLOA at different iterations are asymptotically consistent, ensuring that similar graphs remain similar in subsequent iterations, thereby leading to superior performance over the WL-subtree kernel. Inspired by these findings, we conjecture that the consistency in the similarities of graph representations across GNN layers is crucial in capturing relational structures and enhancing graph classification performance. Thus, we propose a loss to enforce the similarity of graph representations to be consistent across different layers. Our empirical analysis verifies our conjecture and shows that our proposed consistency loss can significantly enhance graph classification performance across several GNN backbones on various datasets.
GraphScale: A Framework to Enable Machine Learning over Billion-node Graphs
Jul 22, 2024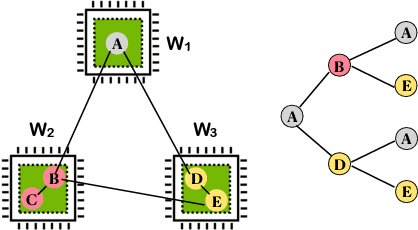
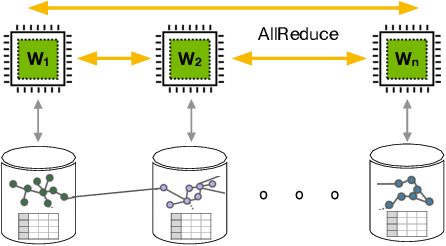
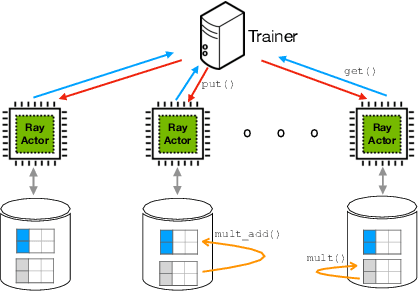

Graph Neural Networks (GNNs) have emerged as powerful tools for supervised machine learning over graph-structured data, while sampling-based node representation learning is widely utilized in unsupervised learning. However, scalability remains a major challenge in both supervised and unsupervised learning for large graphs (e.g., those with over 1 billion nodes). The scalability bottleneck largely stems from the mini-batch sampling phase in GNNs and the random walk sampling phase in unsupervised methods. These processes often require storing features or embeddings in memory. In the context of distributed training, they require frequent, inefficient random access to data stored across different workers. Such repeated inter-worker communication for each mini-batch leads to high communication overhead and computational inefficiency. We propose GraphScale, a unified framework for both supervised and unsupervised learning to store and process large graph data distributedly. The key insight in our design is the separation of workers who store data and those who perform the training. This separation allows us to decouple computing and storage in graph training, thus effectively building a pipeline where data fetching and data computation can overlap asynchronously. Our experiments show that GraphScale outperforms state-of-the-art methods for distributed training of both GNNs and node embeddings. We evaluate GraphScale both on public and proprietary graph datasets and observe a reduction of at least 40% in end-to-end training times compared to popular distributed frameworks, without any loss in performance. While most existing methods don't support billion-node graphs for training node embeddings, GraphScale is currently deployed in production at TikTok enabling efficient learning over such large graphs.
* Published in the Proceedings of the 33rd ACM International Conference on Information and Knowledge Management (CIKM 2024), 8 Pages, 12 Figures
Sharpness-diversity tradeoff: improving flat ensembles with SharpBalance
Jul 17, 2024



Recent studies on deep ensembles have identified the sharpness of the local minima of individual learners and the diversity of the ensemble members as key factors in improving test-time performance. Building on this, our study investigates the interplay between sharpness and diversity within deep ensembles, illustrating their crucial role in robust generalization to both in-distribution (ID) and out-of-distribution (OOD) data. We discover a trade-off between sharpness and diversity: minimizing the sharpness in the loss landscape tends to diminish the diversity of individual members within the ensemble, adversely affecting the ensemble's improvement. The trade-off is justified through our theoretical analysis and verified empirically through extensive experiments. To address the issue of reduced diversity, we introduce SharpBalance, a novel training approach that balances sharpness and diversity within ensembles. Theoretically, we show that our training strategy achieves a better sharpness-diversity trade-off. Empirically, we conducted comprehensive evaluations in various data sets (CIFAR-10, CIFAR-100, TinyImageNet) and showed that SharpBalance not only effectively improves the sharpness-diversity trade-off, but also significantly improves ensemble performance in ID and OOD scenarios.