 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphScale: A Framework to Enable Machine Learning over Billion-node Graphs
Jul 22, 2024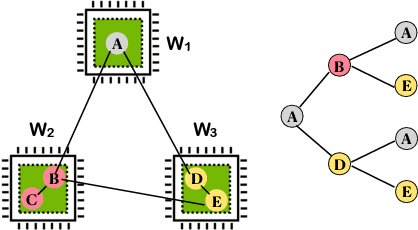
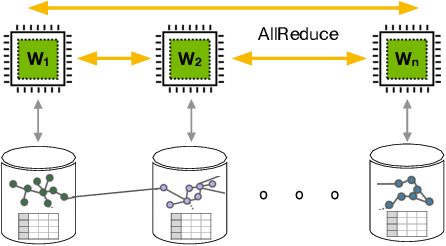
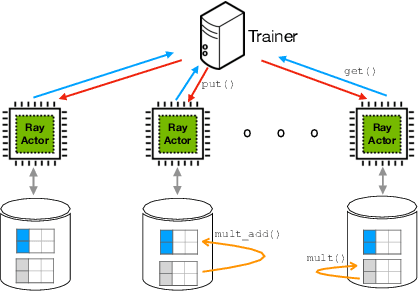

Graph Neural Networks (GNNs) have emerged as powerful tools for supervised machine learning over graph-structured data, while sampling-based node representation learning is widely utilized in unsupervised learning. However, scalability remains a major challenge in both supervised and unsupervised learning for large graphs (e.g., those with over 1 billion nodes). The scalability bottleneck largely stems from the mini-batch sampling phase in GNNs and the random walk sampling phase in unsupervised methods. These processes often require storing features or embeddings in memory. In the context of distributed training, they require frequent, inefficient random access to data stored across different workers. Such repeated inter-worker communication for each mini-batch leads to high communication overhead and computational inefficiency. We propose GraphScale, a unified framework for both supervised and unsupervised learning to store and process large graph data distributedly. The key insight in our design is the separation of workers who store data and those who perform the training. This separation allows us to decouple computing and storage in graph training, thus effectively building a pipeline where data fetching and data computation can overlap asynchronously. Our experiments show that GraphScale outperforms state-of-the-art methods for distributed training of both GNNs and node embeddings. We evaluate GraphScale both on public and proprietary graph datasets and observe a reduction of at least 40% in end-to-end training times compared to popular distributed frameworks, without any loss in performance. While most existing methods don't support billion-node graphs for training node embeddings, GraphScale is currently deployed in production at TikTok enabling efficient learning over such large graphs.
* Published in the Proceedings of the 33rd ACM International Conference on Information and Knowledge Management (CIKM 2024), 8 Pages, 12 Figures