 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimistic Transfer under Task Shift via Bellman Alignment
Jan 29, 2026We study online transfer reinforcement learning (RL) in episodic Markov decision processes, where experience from related source tasks is available during learning on a target task. A fundamental difficulty is that task similarity is typically defined in terms of rewards or transitions, whereas online RL algorithms operate on Bellman regression targets. As a result, naively reusing source Bellman updates introduces systematic bias and invalidates regret guarantees. We identify one-step Bellman alignment as the correct abstraction for transfer in online RL and propose re-weighted targeting (RWT), an operator-level correction that retargets continuation values and compensates for transition mismatch via a change of measure. RWT reduces task mismatch to a fixed one-step correction and enables statistically sound reuse of source data. This alignment yields a two-stage RWT $Q$-learning framework that separates variance reduction from bias correction. Under RKHS function approximation, we establish regret bounds that scale with the complexity of the task shift rather than the target MDP. Empirical results in both tabular and neural network settings demonstrate consistent improvements over single-task learning and naïve pooling, highlighting Bellman alignment as a model-agnostic transfer principle for online RL.
Low-Rank Plus Sparse Matrix Transfer Learning under Growing Representations and Ambient Dimensions
Jan 29, 2026Learning systems often expand their ambient features or latent representations over time, embedding earlier representations into larger spaces with limited new latent structure. We study transfer learning for structured matrix estimation under simultaneous growth of the ambient dimension and the intrinsic representation, where a well-estimated source task is embedded as a subspace of a higher-dimensional target task. We propose a general transfer framework in which the target parameter decomposes into an embedded source component, low-dimensional low-rank innovations, and sparse edits, and develop an anchored alternating projection estimator that preserves transferred subspaces while estimating only low-dimensional innovations and sparse modifications. We establish deterministic error bounds that separate target noise, representation growth, and source estimation error, yielding strictly improved rates when rank and sparsity increments are small. We demonstrate the generality of the framework by applying it to two canonical problems. For Markov transition matrix estimation from a single trajectory, we derive end-to-end theoretical guarantees under dependent noise. For structured covariance estimation under enlarged dimensions, we provide complementary theoretical analysis in the appendix and empirically validate consistent transfer gains.
Transfer Faster, Price Smarter: Minimax Dynamic Pricing under Cross-Market Preference Shift
May 22, 2025


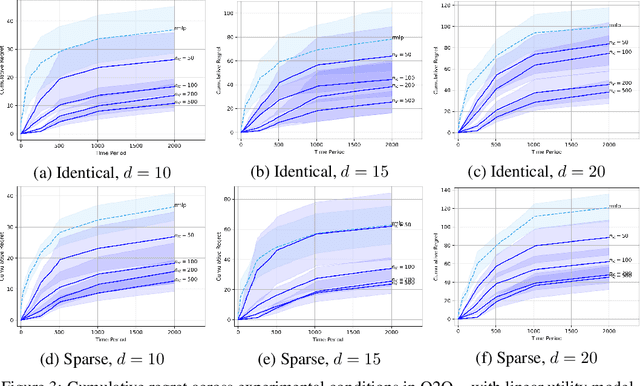
We study contextual dynamic pricing when a target market can leverage K auxiliary markets -- offline logs or concurrent streams -- whose mean utilities differ by a structured preference shift. We propose Cross-Market Transfer Dynamic Pricing (CM-TDP), the first algorithm that provably handles such model-shift transfer and delivers minimax-optimal regret for both linear and non-parametric utility models. For linear utilities of dimension d, where the difference between source- and target-task coefficients is $s_{0}$-sparse, CM-TDP attains regret $\tilde{O}((d*K^{-1}+s_{0})\log T)$. For nonlinear demand residing in a reproducing kernel Hilbert space with effective dimension $\alpha$, complexity $\beta$ and task-similarity parameter $H$, the regret becomes $\tilde{O}\!(K^{-2\alpha\beta/(2\alpha\beta+1)}T^{1/(2\alpha\beta+1)} + H^{2/(2\alpha+1)}T^{1/(2\alpha+1)})$, matching information-theoretic lower bounds up to logarithmic factors. The RKHS bound is the first of its kind for transfer pricing and is of independent interest. Extensive simulations show up to 50% lower cumulative regret and 5 times faster learning relative to single-market pricing baselines. By bridging transfer learning, robust aggregation, and revenue optimization, CM-TDP moves toward pricing systems that transfer faster, price smarter.
Bridging Domain Adaptation and Graph Neural Networks: A Tensor-Based Framework for Effective Label Propagation
Feb 12, 2025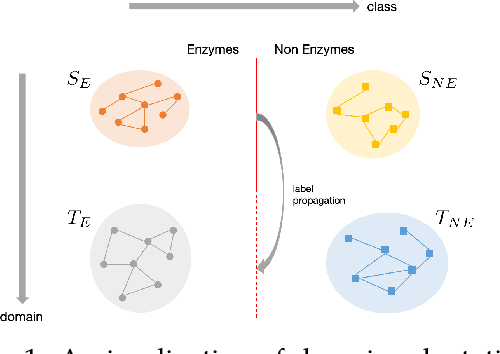
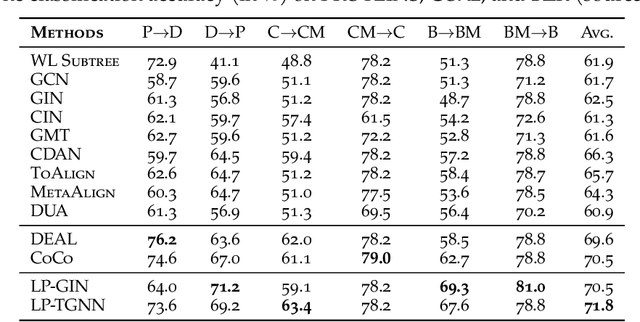
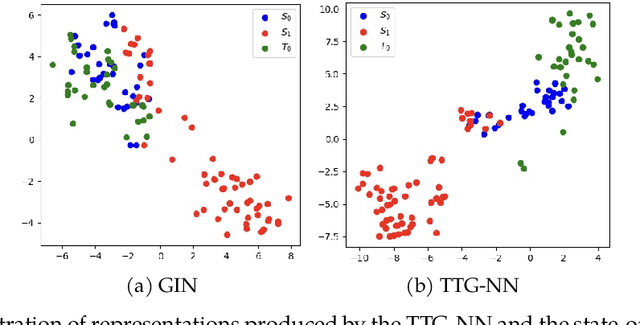
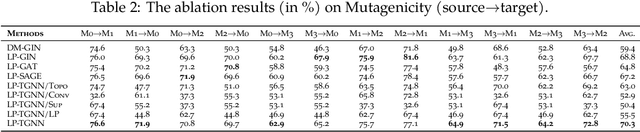
Graph Neural Networks (GNNs) have recently become the predominant tools for studying graph data. Despite state-of-the-art performance on graph classification tasks, GNNs are overwhelmingly trained in a single domain under supervision, thus necessitating a prohibitively high demand for labels and resulting in poorly transferable representations. To address this challenge, we propose the Label-Propagation Tensor Graph Neural Network (LP-TGNN) framework to bridge the gap between graph data and traditional domain adaptation methods. It extracts graph topological information holistically with a tensor architecture and then reduces domain discrepancy through label propagation. It is readily compatible with general GNNs and domain adaptation techniques with minimal adjustment through pseudo-labeling. Experiments on various real-world benchmarks show that our LP-TGNN outperforms baselines by a notable margin. We also validate and analyze each component of the proposed framework in the ablation study.
Statistical Inference for Low-Rank Tensor Models
Jan 27, 2025Statistical inference for tensors has emerged as a critical challenge in analyzing high-dimensional data in modern data science. This paper introduces a unified framework for inferring general and low-Tucker-rank linear functionals of low-Tucker-rank signal tensors for several low-rank tensor models. Our methodology tackles two primary goals: achieving asymptotic normality and constructing minimax-optimal confidence intervals. By leveraging a debiasing strategy and projecting onto the tangent space of the low-Tucker-rank manifold, we enable inference for general and structured linear functionals, extending far beyond the scope of traditional entrywise inference. Specifically, in the low-Tucker-rank tensor regression or PCA model, we establish the computational and statistical efficiency of our approach, achieving near-optimal sample size requirements (in regression model) and signal-to-noise ratio (SNR) conditions (in PCA model) for general linear functionals without requiring sparsity in the loading tensor. Our framework also attains both computationally and statistically optimal sample size and SNR thresholds for low-Tucker-rank linear functionals. Numerical experiments validate our theoretical results, showcasing the framework's utility in diverse applications. This work addresses significant methodological gaps in statistical inference, advancing tensor analysis for complex and high-dimensional data environments.
Deep Transfer $Q$-Learning for Offline Non-Stationary Reinforcement Learning
Jan 08, 2025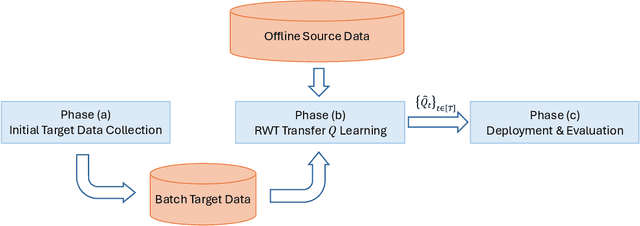

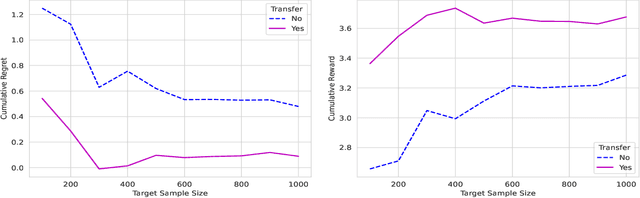
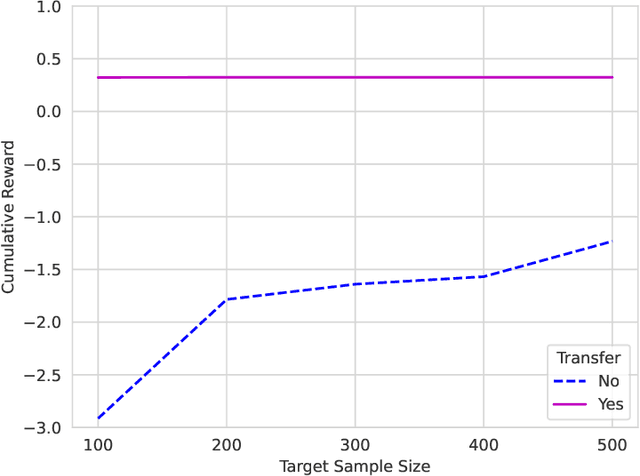
In dynamic decision-making scenarios across business and healthcare, leveraging sample trajectories from diverse populations can significantly enhance reinforcement learning (RL) performance for specific target populations, especially when sample sizes are limited. While existing transfer learning methods primarily focus on linear regression settings, they lack direct applicability to reinforcement learning algorithms. This paper pioneers the study of transfer learning for dynamic decision scenarios modeled by non-stationary finite-horizon Markov decision processes, utilizing neural networks as powerful function approximators and backward inductive learning. We demonstrate that naive sample pooling strategies, effective in regression settings, fail in Markov decision processes.To address this challenge, we introduce a novel ``re-weighted targeting procedure'' to construct ``transferable RL samples'' and propose ``transfer deep $Q^*$-learning'', enabling neural network approximation with theoretical guarantees. We assume that the reward functions are transferable and deal with both situations in which the transition densities are transferable or nontransferable. Our analytical techniques for transfer learning in neural network approximation and transition density transfers have broader implications, extending to supervised transfer learning with neural networks and domain shift scenarios. Empirical experiments on both synthetic and real datasets corroborate the advantages of our method, showcasing its potential for improving decision-making through strategically constructing transferable RL samples in non-stationary reinforcement learning contexts.
TEAFormers: TEnsor-Augmented Transformers for Multi-Dimensional Time Series Forecasting
Oct 27, 2024



Multi-dimensional time series data, such as matrix and tensor-variate time series, are increasingly prevalent in fields such as economics, finance, and climate science. Traditional Transformer models, though adept with sequential data, do not effectively preserve these multi-dimensional structures, as their internal operations in effect flatten multi-dimensional observations into vectors, thereby losing critical multi-dimensional relationships and patterns. To address this, we introduce the Tensor-Augmented Transformer (TEAFormer), a novel method that incorporates tensor expansion and compression within the Transformer framework to maintain and leverage the inherent multi-dimensional structures, thus reducing computational costs and improving prediction accuracy. The core feature of the TEAFormer, the Tensor-Augmentation (TEA) module, utilizes tensor expansion to enhance multi-view feature learning and tensor compression for efficient information aggregation and reduced computational load. The TEA module is not just a specific model architecture but a versatile component that is highly compatible with the attention mechanism and the encoder-decoder structure of Transformers, making it adaptable to existing Transformer architectures. Our comprehensive experiments, which integrate the TEA module into three popular time series Transformer models across three real-world benchmarks, show significant performance enhancements, highlighting the potential of TEAFormers for cutting-edge time series forecasting.
Conditional Uncertainty Quantification for Tensorized Topological Neural Networks
Oct 20, 2024Graph Neural Networks (GNNs) have become the de facto standard for analyzing graph-structured data, leveraging message-passing techniques to capture both structural and node feature information. However, recent studies have raised concerns about the statistical reliability of uncertainty estimates produced by GNNs. This paper addresses this crucial challenge by introducing a novel technique for quantifying uncertainty in non-exchangeable graph-structured data, while simultaneously reducing the size of label prediction sets in graph classification tasks. We propose Conformalized Tensor-based Topological Neural Networks (CF-T2NN), a new approach for rigorous prediction inference over graphs. CF-T2NN employs tensor decomposition and topological knowledge learning to navigate and interpret the inherent uncertainty in decision-making processes. This method enables a more nuanced understanding and handling of prediction uncertainties, enhancing the reliability and interpretability of neural network outcomes. Our empirical validation, conducted across 10 real-world datasets, demonstrates the superiority of CF-T2NN over a wide array of state-of-the-art methods on various graph benchmarks. This work not only enhances the GNN framework with robust uncertainty quantification capabilities but also sets a new standard for reliability and precision in graph-structured data analysis.
Conditional Prediction ROC Bands for Graph Classification
Oct 20, 2024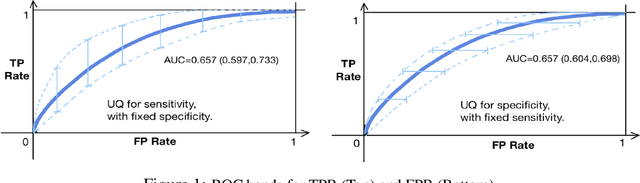

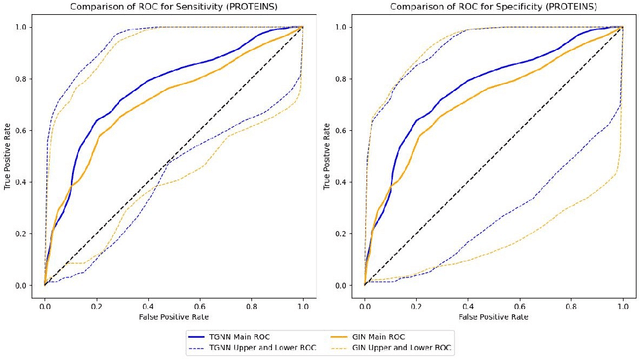
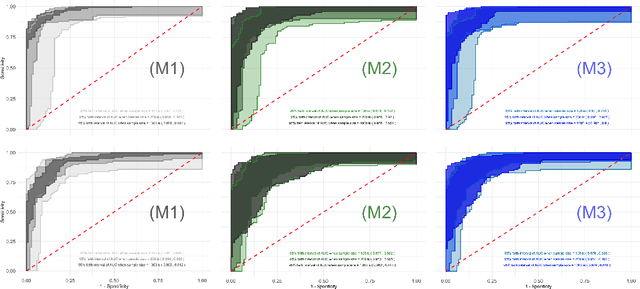
Graph classification in medical imaging and drug discovery requires accuracy and robust uncertainty quantification. To address this need, we introduce Conditional Prediction ROC (CP-ROC) bands, offering uncertainty quantification for ROC curves and robustness to distributional shifts in test data. Although developed for Tensorized Graph Neural Networks (TGNNs), CP-ROC is adaptable to general Graph Neural Networks (GNNs) and other machine learning models. We establish statistically guaranteed coverage for CP-ROC under a local exchangeability condition. This addresses uncertainty challenges for ROC curves under non-iid setting, ensuring reliability when test graph distributions differ from training data. Empirically, to establish local exchangeability for TGNNs, we introduce a data-driven approach to construct local calibration sets for graphs. Comprehensive evaluations show that CP-ROC significantly improves prediction reliability across diverse tasks. This method enhances uncertainty quantification efficiency and reliability for ROC curves, proving valuable for real-world applications with non-iid objects.
Tensor-Fused Multi-View Graph Contrastive Learning
Oct 20, 2024



Graph contrastive learning (GCL) has emerged as a promising approach to enhance graph neural networks' (GNNs) ability to learn rich representations from unlabeled graph-structured data. However, current GCL models face challenges with computational demands and limited feature utilization, often relying only on basic graph properties like node degrees and edge attributes. This constrains their capacity to fully capture the complex topological characteristics of real-world phenomena represented by graphs. To address these limitations, we propose Tensor-Fused Multi-View Graph Contrastive Learning (TensorMV-GCL), a novel framework that integrates extended persistent homology (EPH) with GCL representations and facilitates multi-scale feature extraction. Our approach uniquely employs tensor aggregation and compression to fuse information from graph and topological features obtained from multiple augmented views of the same graph. By incorporating tensor concatenation and contraction modules, we reduce computational overhead by separating feature tensor aggregation and transformation. Furthermore, we enhance the quality of learned topological features and model robustness through noise-injected EPH. Experiments on molecular, bioinformatic, and social network datasets demonstrate TensorMV-GCL's superiority, outperforming 15 state-of-the-art methods in graph classification tasks across 9 out of 11 benchmarks while achieving comparable results on the remaining two. The code for this paper is publicly available at https://github.com/CS-SAIL/Tensor-MV-GCL.git.