 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning Factor Augmented Neural Lasso for Heterogeneous Environments
Apr 14, 2026Fine-tuning is a widely used strategy for adapting pre-trained models to new tasks, yet its methodology and theoretical properties in high-dimensional nonparametric settings with variable selection have not yet been developed. This paper introduces the fine-tuning factor augmented neural Lasso (FAN-Lasso), a transfer learning framework for high-dimensional nonparametric regression with variable selection that simultaneously handles covariate and posterior shifts. We use a low-rank factor structure to manage high-dimensional dependent covariates and propose a novel residual fine-tuning decomposition in which the target function is expressed as a transformation of a frozen source function and other variables to achieve transfer learning and nonparametric variable selection. This augmented feature from the source predictor allows for the transfer of knowledge to the target domain and reduces model complexity there. We derive minimax-optimal excess risk bounds for the fine-tuning FAN-Lasso, characterizing the precise conditions, in terms of relative sample sizes and function complexities, under which fine-tuning yields statistical acceleration over single-task learning. The proposed framework also provides a theoretical perspective on parameter-efficient fine-tuning methods. Extensive numerical experiments across diverse covariate- and posterior-shift scenarios demonstrate that the fine-tuning FAN-Lasso consistently outperforms standard baselines and achieves near-oracle performance even under severe target sample size constraints, empirically validating the derived rates.
Low-Rank Plus Sparse Matrix Transfer Learning under Growing Representations and Ambient Dimensions
Jan 29, 2026Learning systems often expand their ambient features or latent representations over time, embedding earlier representations into larger spaces with limited new latent structure. We study transfer learning for structured matrix estimation under simultaneous growth of the ambient dimension and the intrinsic representation, where a well-estimated source task is embedded as a subspace of a higher-dimensional target task. We propose a general transfer framework in which the target parameter decomposes into an embedded source component, low-dimensional low-rank innovations, and sparse edits, and develop an anchored alternating projection estimator that preserves transferred subspaces while estimating only low-dimensional innovations and sparse modifications. We establish deterministic error bounds that separate target noise, representation growth, and source estimation error, yielding strictly improved rates when rank and sparsity increments are small. We demonstrate the generality of the framework by applying it to two canonical problems. For Markov transition matrix estimation from a single trajectory, we derive end-to-end theoretical guarantees under dependent noise. For structured covariance estimation under enlarged dimensions, we provide complementary theoretical analysis in the appendix and empirically validate consistent transfer gains.
Optimistic Transfer under Task Shift via Bellman Alignment
Jan 29, 2026We study online transfer reinforcement learning (RL) in episodic Markov decision processes, where experience from related source tasks is available during learning on a target task. A fundamental difficulty is that task similarity is typically defined in terms of rewards or transitions, whereas online RL algorithms operate on Bellman regression targets. As a result, naively reusing source Bellman updates introduces systematic bias and invalidates regret guarantees. We identify one-step Bellman alignment as the correct abstraction for transfer in online RL and propose re-weighted targeting (RWT), an operator-level correction that retargets continuation values and compensates for transition mismatch via a change of measure. RWT reduces task mismatch to a fixed one-step correction and enables statistically sound reuse of source data. This alignment yields a two-stage RWT $Q$-learning framework that separates variance reduction from bias correction. Under RKHS function approximation, we establish regret bounds that scale with the complexity of the task shift rather than the target MDP. Empirical results in both tabular and neural network settings demonstrate consistent improvements over single-task learning and naïve pooling, highlighting Bellman alignment as a model-agnostic transfer principle for online RL.
Deep Transfer $Q$-Learning for Offline Non-Stationary Reinforcement Learning
Jan 08, 2025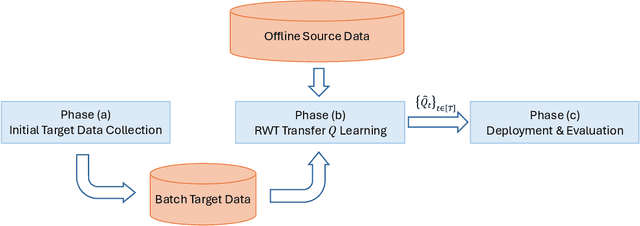

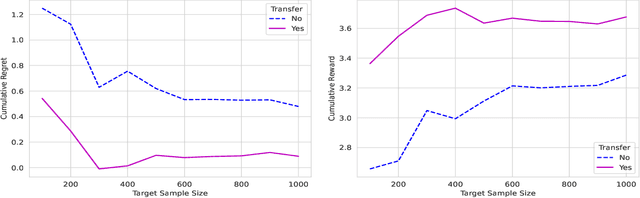
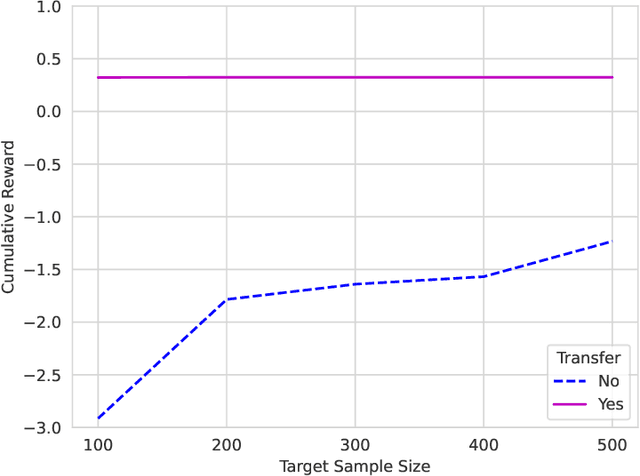
In dynamic decision-making scenarios across business and healthcare, leveraging sample trajectories from diverse populations can significantly enhance reinforcement learning (RL) performance for specific target populations, especially when sample sizes are limited. While existing transfer learning methods primarily focus on linear regression settings, they lack direct applicability to reinforcement learning algorithms. This paper pioneers the study of transfer learning for dynamic decision scenarios modeled by non-stationary finite-horizon Markov decision processes, utilizing neural networks as powerful function approximators and backward inductive learning. We demonstrate that naive sample pooling strategies, effective in regression settings, fail in Markov decision processes.To address this challenge, we introduce a novel ``re-weighted targeting procedure'' to construct ``transferable RL samples'' and propose ``transfer deep $Q^*$-learning'', enabling neural network approximation with theoretical guarantees. We assume that the reward functions are transferable and deal with both situations in which the transition densities are transferable or nontransferable. Our analytical techniques for transfer learning in neural network approximation and transition density transfers have broader implications, extending to supervised transfer learning with neural networks and domain shift scenarios. Empirical experiments on both synthetic and real datasets corroborate the advantages of our method, showcasing its potential for improving decision-making through strategically constructing transferable RL samples in non-stationary reinforcement learning contexts.
Localized exploration in contextual dynamic pricing achieves dimension-free regret
Dec 26, 2024We study the problem of contextual dynamic pricing with a linear demand model. We propose a novel localized exploration-then-commit (LetC) algorithm which starts with a pure exploration stage, followed by a refinement stage that explores near the learned optimal pricing policy, and finally enters a pure exploitation stage. The algorithm is shown to achieve a minimax optimal, dimension-free regret bound when the time horizon exceeds a polynomial of the covariate dimension. Furthermore, we provide a general theoretical framework that encompasses the entire time spectrum, demonstrating how to balance exploration and exploitation when the horizon is limited. The analysis is powered by a novel critical inequality that depicts the exploration-exploitation trade-off in dynamic pricing, mirroring its existing counterpart for the bias-variance trade-off in regularized regression. Our theoretical results are validated by extensive experiments on synthetic and real-world data.
Structured Matrix Learning under Arbitrary Entrywise Dependence and Estimation of Markov Transition Kernel
Jan 04, 2024The problem of structured matrix estimation has been studied mostly under strong noise dependence assumptions. This paper considers a general framework of noisy low-rank-plus-sparse matrix recovery, where the noise matrix may come from any joint distribution with arbitrary dependence across entries. We propose an incoherent-constrained least-square estimator and prove its tightness both in the sense of deterministic lower bound and matching minimax risks under various noise distributions. To attain this, we establish a novel result asserting that the difference between two arbitrary low-rank incoherent matrices must spread energy out across its entries, in other words cannot be too sparse, which sheds light on the structure of incoherent low-rank matrices and may be of independent interest. We then showcase the applications of our framework to several important statistical machine learning problems. In the problem of estimating a structured Markov transition kernel, the proposed method achieves the minimax optimality and the result can be extended to estimating the conditional mean operator, a crucial component in reinforcement learning. The applications to multitask regression and structured covariance estimation are also presented. We propose an alternating minimization algorithm to approximately solve the potentially hard optimization problem. Numerical results corroborate the effectiveness of our method which typically converges in a few steps.