 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Large Language Models on Solved and Unsolved Problems in Graph Theory: Implications for Computing Education
Feb 04, 2026Large Language Models are increasingly used by students to explore advanced material in computer science, including graph theory. As these tools become integrated into undergraduate and graduate coursework, it is important to understand how reliably they support mathematically rigorous thinking. This study examines the performance of a LLM on two related graph theoretic problems: a solved problem concerning the gracefulness of line graphs and an open problem for which no solution is currently known. We use an eight stage evaluation protocol that reflects authentic mathematical inquiry, including interpretation, exploration, strategy formation, and proof construction. The model performed strongly on the solved problem, producing correct definitions, identifying relevant structures, recalling appropriate results without hallucination, and constructing a valid proof confirmed by a graph theory expert. For the open problem, the model generated coherent interpretations and plausible exploratory strategies but did not advance toward a solution. It did not fabricate results and instead acknowledged uncertainty, which is consistent with the explicit prompting instructions that directed the model to avoid inventing theorems or unsupported claims. These findings indicate that LLMs can support exploration of established material but remain limited in tasks requiring novel mathematical insight or critical structural reasoning. For computing education, this distinction highlights the importance of guiding students to use LLMs for conceptual exploration while relying on independent verification and rigorous argumentation for formal problem solving.
How Reasoning Influences Intersectional Biases in Vision Language Models
Nov 08, 2025Vision Language Models (VLMs) are increasingly deployed across downstream tasks, yet their training data often encode social biases that surface in outputs. Unlike humans, who interpret images through contextual and social cues, VLMs process them through statistical associations, often leading to reasoning that diverges from human reasoning. By analyzing how a VLM reasons, we can understand how inherent biases are perpetuated and can adversely affect downstream performance. To examine this gap, we systematically analyze social biases in five open-source VLMs for an occupation prediction task, on the FairFace dataset. Across 32 occupations and three different prompting styles, we elicit both predictions and reasoning. Our findings reveal that the biased reasoning patterns systematically underlie intersectional disparities, highlighting the need to align VLM reasoning with human values prior to its downstream deployment.
MuGa-VTON: Multi-Garment Virtual Try-On via Diffusion Transformers with Prompt Customization
Aug 11, 2025Virtual try-on seeks to generate photorealistic images of individuals in desired garments, a task that must simultaneously preserve personal identity and garment fidelity for practical use in fashion retail and personalization. However, existing methods typically handle upper and lower garments separately, rely on heavy preprocessing, and often fail to preserve person-specific cues such as tattoos, accessories, and body shape-resulting in limited realism and flexibility. To this end, we introduce MuGa-VTON, a unified multi-garment diffusion framework that jointly models upper and lower garments together with person identity in a shared latent space. Specifically, we proposed three key modules: the Garment Representation Module (GRM) for capturing both garment semantics, the Person Representation Module (PRM) for encoding identity and pose cues, and the A-DiT fusion module, which integrates garment, person, and text-prompt features through a diffusion transformer. This architecture supports prompt-based customization, allowing fine-grained garment modifications with minimal user input. Extensive experiments on the VITON-HD and DressCode benchmarks demonstrate that MuGa-VTON outperforms existing methods in both qualitative and quantitative evaluations, producing high-fidelity, identity-preserving results suitable for real-world virtual try-on applications.
An Empirical Study of Using ChatGPT for Fact Verification Task
Nov 11, 2023



ChatGPT has recently emerged as a powerful tool for performing diverse NLP tasks. However, ChatGPT has been criticized for generating nonfactual responses, raising concerns about its usability for sensitive tasks like fact verification. This study investigates three key research questions: (1) Can ChatGPT be used for fact verification tasks? (2) What are different prompts performance using ChatGPT for fact verification tasks? (3) For the best-performing prompt, what common mistakes does ChatGPT make? Specifically, this study focuses on conducting a comprehensive and systematic analysis by designing and comparing the performance of three different prompts for fact verification tasks on the benchmark FEVER dataset using ChatGPT.
Zero-shot Approach to Overcome Perturbation Sensitivity of Prompts
May 25, 2023
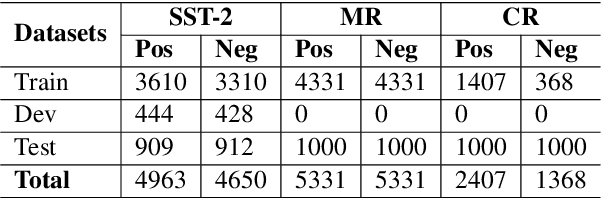
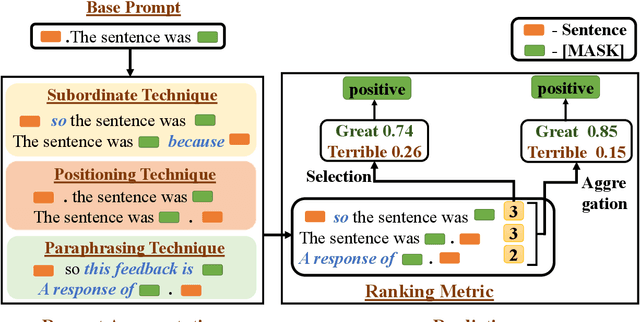
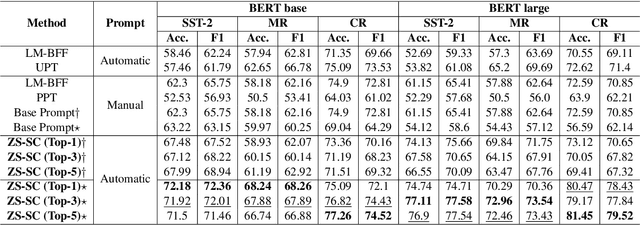
Recent studies have demonstrated that natural-language prompts can help to leverage the knowledge learned by pre-trained language models for the binary sentence-level sentiment classification task. Specifically, these methods utilize few-shot learning settings to fine-tune the sentiment classification model using manual or automatically generated prompts. However, the performance of these methods is sensitive to the perturbations of the utilized prompts. Furthermore, these methods depend on a few labeled instances for automatic prompt generation and prompt ranking. This study aims to find high-quality prompts for the given task in a zero-shot setting. Given a base prompt, our proposed approach automatically generates multiple prompts similar to the base prompt employing positional, reasoning, and paraphrasing techniques and then ranks the prompts using a novel metric. We empirically demonstrate that the top-ranked prompts are high-quality and significantly outperform the base prompt and the prompts generated using few-shot learning for the binary sentence-level sentiment classification task.