 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-guided Chemical Process Optimization with a Multi-Agent Approach
Jun 26, 2025Chemical process optimization is crucial to maximize production efficiency and economic performance. Traditional methods, including gradient-based solvers, evolutionary algorithms, and parameter grid searches, become impractical when operating constraints are ill-defined or unavailable, requiring engineers to rely on subjective heuristics to estimate feasible parameter ranges. To address this constraint definition bottleneck, we present a multi-agent framework of large language model (LLM) agents that autonomously infer operating constraints from minimal process descriptions, then collaboratively guide optimization using the inferred constraints. Our AutoGen-based agentic framework employs OpenAI's o3 model, with specialized agents for constraint generation, parameter validation, simulation execution, and optimization guidance. Through two phases - autonomous constraint generation using embedded domain knowledge, followed by iterative multi-agent optimization - the framework eliminates the need for predefined operational bounds. Validated on the hydrodealkylation process across cost, yield, and yield-to-cost ratio metrics, the framework demonstrated competitive performance with conventional optimization methods while achieving better computational efficiency, requiring fewer iterations to converge. Our approach converged in under 20 minutes, achieving a 31-fold speedup over grid search. Beyond computational efficiency, the framework's reasoning-guided search demonstrates sophisticated process understanding, correctly identifying utility trade-offs, and applying domain-informed heuristics. This approach shows significant potential for optimization scenarios where operational constraints are poorly characterized or unavailable, particularly for emerging processes and retrofit applications.
Scientific Hypothesis Generation and Validation: Methods, Datasets, and Future Directions
May 06, 2025Large Language Models (LLMs) are transforming scientific hypothesis generation and validation by enabling information synthesis, latent relationship discovery, and reasoning augmentation. This survey provides a structured overview of LLM-driven approaches, including symbolic frameworks, generative models, hybrid systems, and multi-agent architectures. We examine techniques such as retrieval-augmented generation, knowledge-graph completion, simulation, causal inference, and tool-assisted reasoning, highlighting trade-offs in interpretability, novelty, and domain alignment. We contrast early symbolic discovery systems (e.g., BACON, KEKADA) with modern LLM pipelines that leverage in-context learning and domain adaptation via fine-tuning, retrieval, and symbolic grounding. For validation, we review simulation, human-AI collaboration, causal modeling, and uncertainty quantification, emphasizing iterative assessment in open-world contexts. The survey maps datasets across biomedicine, materials science, environmental science, and social science, introducing new resources like AHTech and CSKG-600. Finally, we outline a roadmap emphasizing novelty-aware generation, multimodal-symbolic integration, human-in-the-loop systems, and ethical safeguards, positioning LLMs as agents for principled, scalable scientific discovery.
Are Vision LLMs Road-Ready? A Comprehensive Benchmark for Safety-Critical Driving Video Understanding
Apr 20, 2025Vision Large Language Models (VLLMs) have demonstrated impressive capabilities in general visual tasks such as image captioning and visual question answering. However, their effectiveness in specialized, safety-critical domains like autonomous driving remains largely unexplored. Autonomous driving systems require sophisticated scene understanding in complex environments, yet existing multimodal benchmarks primarily focus on normal driving conditions, failing to adequately assess VLLMs' performance in safety-critical scenarios. To address this, we introduce DVBench, a pioneering benchmark designed to evaluate the performance of VLLMs in understanding safety-critical driving videos. Built around a hierarchical ability taxonomy that aligns with widely adopted frameworks for describing driving scenarios used in assessing highly automated driving systems, DVBench features 10,000 multiple-choice questions with human-annotated ground-truth answers, enabling a comprehensive evaluation of VLLMs' capabilities in perception and reasoning. Experiments on 14 SOTA VLLMs, ranging from 0.5B to 72B parameters, reveal significant performance gaps, with no model achieving over 40% accuracy, highlighting critical limitations in understanding complex driving scenarios. To probe adaptability, we fine-tuned selected models using domain-specific data from DVBench, achieving accuracy gains ranging from 5.24 to 10.94 percentage points, with relative improvements of up to 43.59%. This improvement underscores the necessity of targeted adaptation to bridge the gap between general-purpose VLLMs and mission-critical driving applications. DVBench establishes an essential evaluation framework and research roadmap for developing VLLMs that meet the safety and robustness requirements for real-world autonomous systems. We released the benchmark toolbox and the fine-tuned model at: https://github.com/tong-zeng/DVBench.git.
GotFunding: A grant recommendation system based on scientific articles
May 21, 2024Obtaining funding is an important part of becoming a successful scientist. Junior faculty spend a great deal of time finding the right agencies and programs that best match their research profile. But what are the factors that influence the best publication--grant matching? Some universities might employ pre-award personnel to understand these factors, but not all institutions can afford to hire them. Historical records of publications funded by grants can help us understand the matching process and also help us develop recommendation systems to automate it. In this work, we present \textsc{GotFunding} (Grant recOmmendaTion based on past FUNDING), a recommendation system trained on National Institutes of Health's (NIH) grant--publication records. Our system achieves a high performance (NDCG@1 = 0.945) by casting the problem as learning to rank. By analyzing the features that make predictions effective, our results show that the ranking considers most important 1) the year difference between publication and grant grant, 2) the amount of information provided in the publication, and 3) the relevance of the publication to the grant. We discuss future improvements of the system and an online tool for scientists to try.
Dataset Mention Extraction in Scientific Articles Using Bi-LSTM-CRF Model
May 21, 2024Datasets are critical for scientific research, playing an important role in replication, reproducibility, and efficiency. Researchers have recently shown that datasets are becoming more important for science to function properly, even serving as artifacts of study themselves. However, citing datasets is not a common or standard practice in spite of recent efforts by data repositories and funding agencies. This greatly affects our ability to track their usage and importance. A potential solution to this problem is to automatically extract dataset mentions from scientific articles. In this work, we propose to achieve such extraction by using a neural network based on a Bi-LSTM-CRF architecture. Our method achieves F1 = 0.885 in social science articles released as part of the Rich Context Dataset. We discuss the limitations of the current datasets and propose modifications to the model to be done in the future.
Modeling citation worthiness by using attention-based bidirectional long short-term memory networks and interpretable models
May 20, 2024Scientist learn early on how to cite scientific sources to support their claims. Sometimes, however, scientists have challenges determining where a citation should be situated -- or, even worse, fail to cite a source altogether. Automatically detecting sentences that need a citation (i.e., citation worthiness) could solve both of these issues, leading to more robust and well-constructed scientific arguments. Previous researchers have applied machine learning to this task but have used small datasets and models that do not take advantage of recent algorithmic developments such as attention mechanisms in deep learning. We hypothesize that we can develop significantly accurate deep learning architectures that learn from large supervised datasets constructed from open access publications. In this work, we propose a Bidirectional Long Short-Term Memory (BiLSTM) network with attention mechanism and contextual information to detect sentences that need citations. We also produce a new, large dataset (PMOA-CITE) based on PubMed Open Access Subset, which is orders of magnitude larger than previous datasets. Our experiments show that our architecture achieves state of the art performance on the standard ACL-ARC dataset ($F_{1}=0.507$) and exhibits high performance ($F_{1}=0.856$) on the new PMOA-CITE. Moreover, we show that it can transfer learning across these datasets. We further use interpretable models to illuminate how specific language is used to promote and inhibit citations. We discover that sections and surrounding sentences are crucial for our improved predictions. We further examined purported mispredictions of the model, and uncovered systematic human mistakes in citation behavior and source data. This opens the door for our model to check documents during pre-submission and pre-archival procedures. We make this new dataset, the code, and a web-based tool available to the community.
Predicting the longevity of resources shared in scientific publications
Mar 24, 2022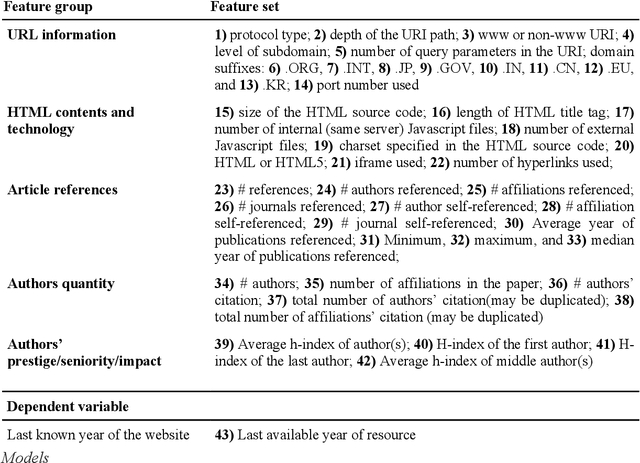
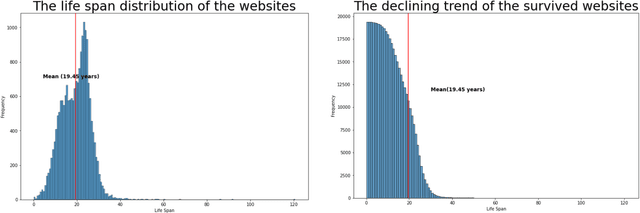
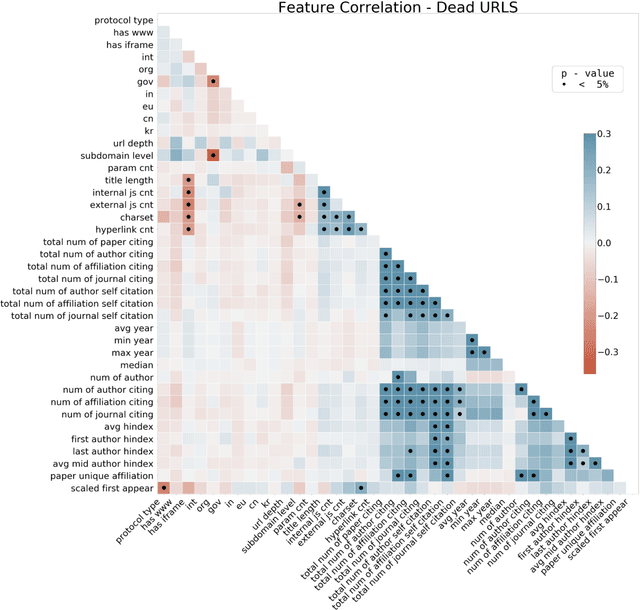
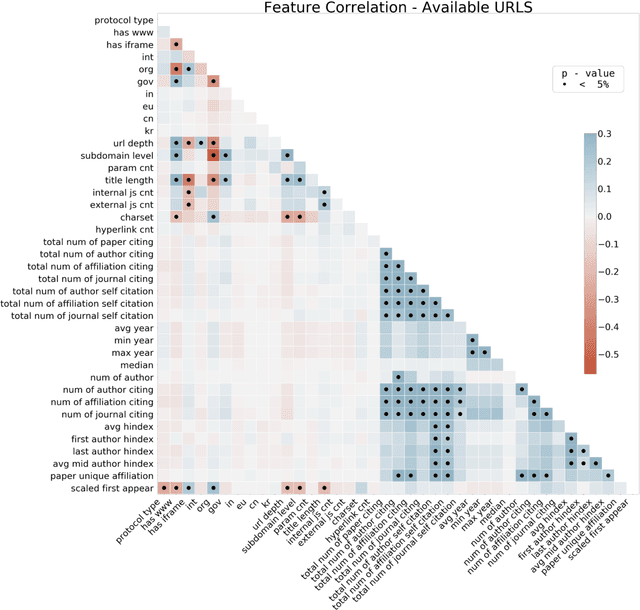
Research has shown that most resources shared in articles (e.g., URLs to code or data) are not kept up to date and mostly disappear from the web after some years (Zeng et al., 2019). Little is known about the factors that differentiate and predict the longevity of these resources. This article explores a range of explanatory features related to the publication venue, authors, references, and where the resource is shared. We analyze an extensive repository of publications and, through web archival services, reconstruct how they looked at different time points. We discover that the most important factors are related to where and how the resource is shared, and surprisingly little is explained by the author's reputation or prestige of the journal. By examining the places where long-lasting resources are shared, we suggest that it is critical to disseminate and create standards with modern technologies. Finally, we discuss implications for reproducibility and recognizing scientific datasets as first-class citizens.