 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGotFunding: A grant recommendation system based on scientific articles
May 21, 2024Obtaining funding is an important part of becoming a successful scientist. Junior faculty spend a great deal of time finding the right agencies and programs that best match their research profile. But what are the factors that influence the best publication--grant matching? Some universities might employ pre-award personnel to understand these factors, but not all institutions can afford to hire them. Historical records of publications funded by grants can help us understand the matching process and also help us develop recommendation systems to automate it. In this work, we present \textsc{GotFunding} (Grant recOmmendaTion based on past FUNDING), a recommendation system trained on National Institutes of Health's (NIH) grant--publication records. Our system achieves a high performance (NDCG@1 = 0.945) by casting the problem as learning to rank. By analyzing the features that make predictions effective, our results show that the ranking considers most important 1) the year difference between publication and grant grant, 2) the amount of information provided in the publication, and 3) the relevance of the publication to the grant. We discuss future improvements of the system and an online tool for scientists to try.
Modeling citation worthiness by using attention-based bidirectional long short-term memory networks and interpretable models
May 20, 2024Scientist learn early on how to cite scientific sources to support their claims. Sometimes, however, scientists have challenges determining where a citation should be situated -- or, even worse, fail to cite a source altogether. Automatically detecting sentences that need a citation (i.e., citation worthiness) could solve both of these issues, leading to more robust and well-constructed scientific arguments. Previous researchers have applied machine learning to this task but have used small datasets and models that do not take advantage of recent algorithmic developments such as attention mechanisms in deep learning. We hypothesize that we can develop significantly accurate deep learning architectures that learn from large supervised datasets constructed from open access publications. In this work, we propose a Bidirectional Long Short-Term Memory (BiLSTM) network with attention mechanism and contextual information to detect sentences that need citations. We also produce a new, large dataset (PMOA-CITE) based on PubMed Open Access Subset, which is orders of magnitude larger than previous datasets. Our experiments show that our architecture achieves state of the art performance on the standard ACL-ARC dataset ($F_{1}=0.507$) and exhibits high performance ($F_{1}=0.856$) on the new PMOA-CITE. Moreover, we show that it can transfer learning across these datasets. We further use interpretable models to illuminate how specific language is used to promote and inhibit citations. We discover that sections and surrounding sentences are crucial for our improved predictions. We further examined purported mispredictions of the model, and uncovered systematic human mistakes in citation behavior and source data. This opens the door for our model to check documents during pre-submission and pre-archival procedures. We make this new dataset, the code, and a web-based tool available to the community.
Paraphrase Identification with Deep Learning: A Review of Datasets and Methods
Dec 13, 2022The rapid advancement of AI technology has made text generation tools like GPT-3 and ChatGPT increasingly accessible, scalable, and effective. This can pose serious threat to the credibility of various forms of media if these technologies are used for plagiarism, including scientific literature and news sources. Despite the development of automated methods for paraphrase identification, detecting this type of plagiarism remains a challenge due to the disparate nature of the datasets on which these methods are trained. In this study, we review traditional and current approaches to paraphrase identification and propose a refined typology of paraphrases. We also investigate how this typology is represented in popular datasets and how under-representation of certain types of paraphrases impacts detection capabilities. Finally, we outline new directions for future research and datasets in the pursuit of more effective paraphrase detection using AI.
Predicting the longevity of resources shared in scientific publications
Mar 24, 2022
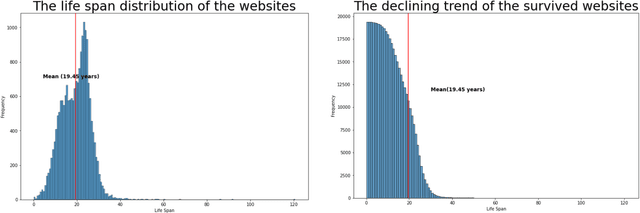
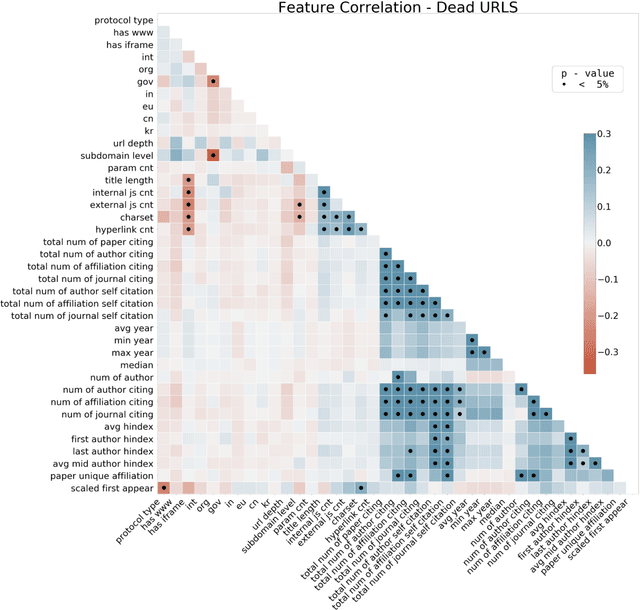
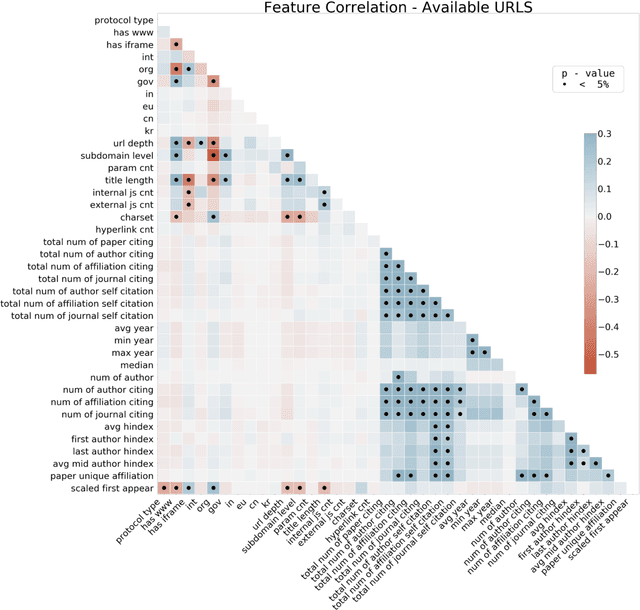
Research has shown that most resources shared in articles (e.g., URLs to code or data) are not kept up to date and mostly disappear from the web after some years (Zeng et al., 2019). Little is known about the factors that differentiate and predict the longevity of these resources. This article explores a range of explanatory features related to the publication venue, authors, references, and where the resource is shared. We analyze an extensive repository of publications and, through web archival services, reconstruct how they looked at different time points. We discover that the most important factors are related to where and how the resource is shared, and surprisingly little is explained by the author's reputation or prestige of the journal. By examining the places where long-lasting resources are shared, we suggest that it is critical to disseminate and create standards with modern technologies. Finally, we discuss implications for reproducibility and recognizing scientific datasets as first-class citizens.
EILEEN: A recommendation system for scientific publications and grants
Oct 19, 2021
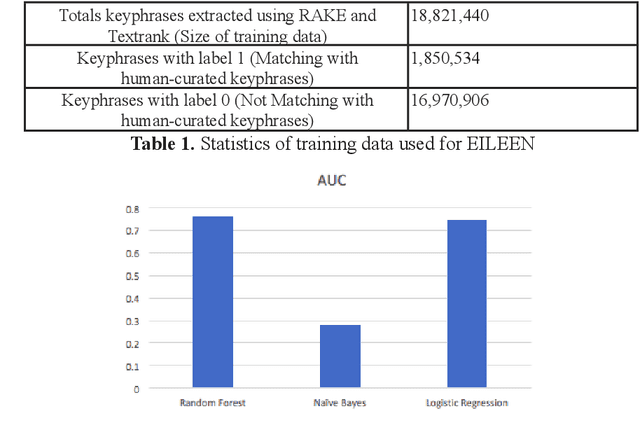


Finding relevant scientific articles is crucial for advancing knowledge. Recommendation systems are helpful for such purpose, although they have only been applied to science recently. This article describes EILEEN (Exploratory Innovator of LitEraturE Networks), a recommendation system for scientific publications and grants with open source code and datasets. We describe EILEEN's architecture for ingesting and processing documents and modeling the recommendation system and keyphrase estimator. Using a unique dataset of log-in user behavior, we validate our recommendation system against Latent Semantic Analysis (LSA) and the standard ranking from Elasticsearch (Lucene scoring). We find that a learning-to-rank with Random Forest achieves an AUC of 0.9, significantly outperforming both baselines. Our results suggest that we can substantially improve science recommendations and learn about scientists' behavior through their search behavior. We make our system available through eileen.io
Scientific Image Tampering Detection Based On Noise Inconsistencies: A Method And Datasets
Mar 04, 2020



Scientific image tampering is a problem that affects not only authors but also the general perception of the research community. Although previous researchers have developed methods to identify tampering in natural images, these methods may not thrive under the scientific setting as scientific images have different statistics, format, quality, and intentions. Therefore, we propose a scientific-image specific tampering detection method based on noise inconsistencies, which is capable of learning and generalizing to different fields of science. We train and test our method on a new dataset of manipulated western blot and microscopy imagery, which aims at emulating problematic images in science. The test results show that our method can detect various types of image manipulation in different scenarios robustly, and it outperforms existing general-purpose image tampering detection schemes. We discuss applications beyond these two types of images and suggest next steps for making detection of problematic images a systematic step in peer review and science in general.
Estimating a Null Model of Scientific Image Reuse to Support Research Integrity Investigations
Feb 22, 2020



When there is a suspicious figure reuse case in science, research integrity investigators often find it difficult to rebut authors claiming that "it happened by chance". In other words, when there is a "collision" of image features, it is difficult to justify whether it appears rarely or not. In this article, we provide a method to predict the rarity of an image feature by statistically estimating the chance of it randomly occurring across all scientific imagery. Our method is based on high-dimensional density estimation of ORB features using 7+ million images in the PubMed Open Access Subset dataset. We show that this method can lead to meaningful feedback during research integrity investigations by providing a null hypothesis for scientific image reuse and thus a p-value during deliberations. We apply the model to a sample of increasingly complex imagery and confirm that it produces decreasingly smaller p-values as expected. We discuss applications to research integrity investigations as well as future work.
Artificial mental phenomena: Psychophysics as a framework to detect perception biases in AI models
Dec 15, 2019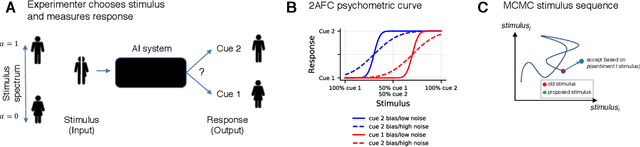



Detecting biases in artificial intelligence has become difficult because of the impenetrable nature of deep learning. The central difficulty is in relating unobservable phenomena deep inside models with observable, outside quantities that we can measure from inputs and outputs. For example, can we detect gendered perceptions of occupations (e.g., female librarian, male electrician) using questions to and answers from a word embedding-based system? Current techniques for detecting biases are often customized for a task, dataset, or method, affecting their generalization. In this work, we draw from Psychophysics in Experimental Psychology---meant to relate quantities from the real world (i.e., "Physics") into subjective measures in the mind (i.e., "Psyche")---to propose an intellectually coherent and generalizable framework to detect biases in AI. Specifically, we adapt the two-alternative forced choice task (2AFC) to estimate potential biases and the strength of those biases in black-box models. We successfully reproduce previously-known biased perceptions in word embeddings and sentiment analysis predictions. We discuss how concepts in experimental psychology can be naturally applied to understanding artificial mental phenomena, and how psychophysics can form a useful methodological foundation to study fairness in AI.