 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeaving Some Facial Features Behind
Oct 29, 2024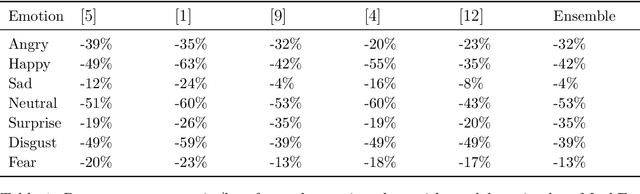

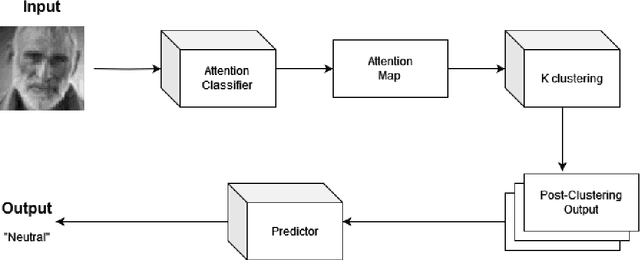
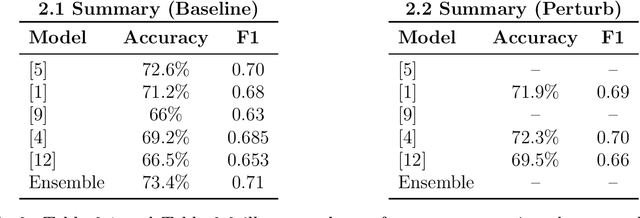
Facial expressions are crucial to human communication, offering insights into emotional states. This study examines how specific facial features influence emotion classification, using facial perturbations on the Fer2013 dataset. As expected, models trained on data with the removal of some important facial feature experienced up to an 85% accuracy drop when compared to baseline for emotions like happy and surprise. Surprisingly, for the emotion disgust, there seem to be slight improvement in accuracy for classifier after mask have been applied. Building on top of this observation, we applied a training scheme to mask out facial features during training, motivating our proposed Perturb Scheme. This scheme, with three phases-attention-based classification, pixel clustering, and feature-focused training, demonstrates improvements in classification accuracy. The experimental results obtained suggests there are some benefits to removing individual facial features in emotion recognition tasks.
Solving Oscillator ODEs via Soft-constrained Physics-informed Neural Network with Small Data
Aug 19, 2024
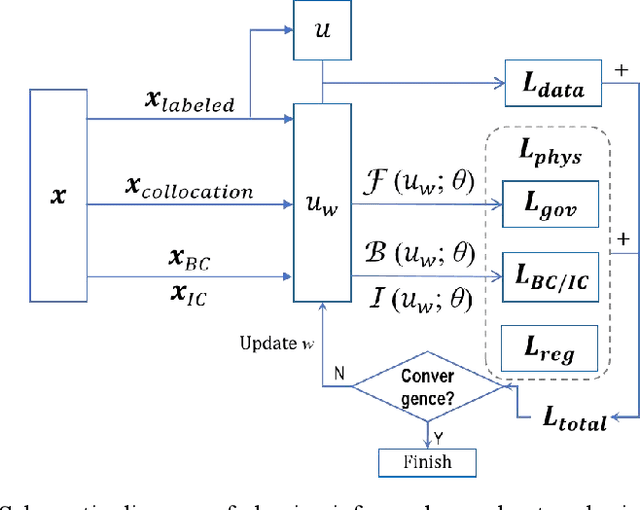
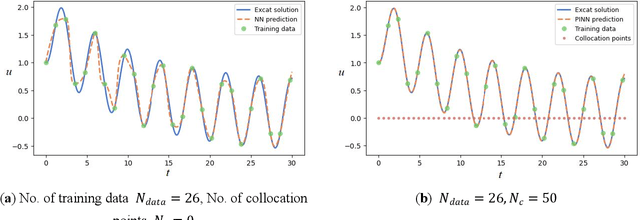
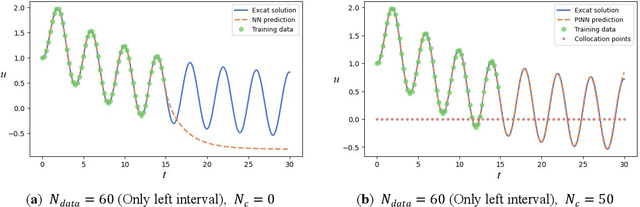
This paper compared physics-informed neural network (PINN), conventional neural network (NN) and numerical discretization methods on solving differential equations through literature research. We formalized the mathematical framework and computational flow of the soft-constrained PINN method for solving differential equations (e.g., ODEs/PDEs). Its working mechanism and its accuracy and efficiency were experimentally verified by solving typical linear and non-linear oscillator ODEs. The implementation of the PINN method based on DeepXDE is not only light code and efficient in training, but also flexible across platforms. PINN greatly reduces the need for labeled data: when the nonlinearity of the ODE is weak, a very small amount of supervised training data plus a small amount of collocation points are sufficient to predict the solution; in the minimalist case, only one or two training points (with initial values) are needed for first- or second-order ODEs, respectively. Strongly nonlinear ODE also require only an appropriate increase in the number of training and collocation points, which still has significant advantages over conventional NN. With the aid of collocation points and the use of physical information, PINN has the ability to extrapolate data outside the time domain covered by the training set, and is robust to noisy data, thus with enhanced generalization capabilities. Training is accelerated when the gains obtained along with the reduction in the amount of data outweigh the delay caused by the increase in the loss function terms. The soft-constrained PINN method can easily impose a physical law (e.g., energy conservation) constraint by adding a regularization term to the total loss function, thus improving the solution performance of ODEs that obey this physical law.
Paraphrase Identification with Deep Learning: A Review of Datasets and Methods
Dec 13, 2022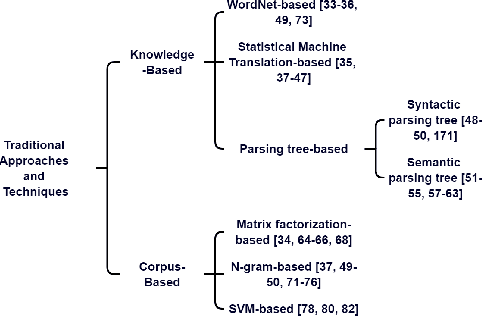
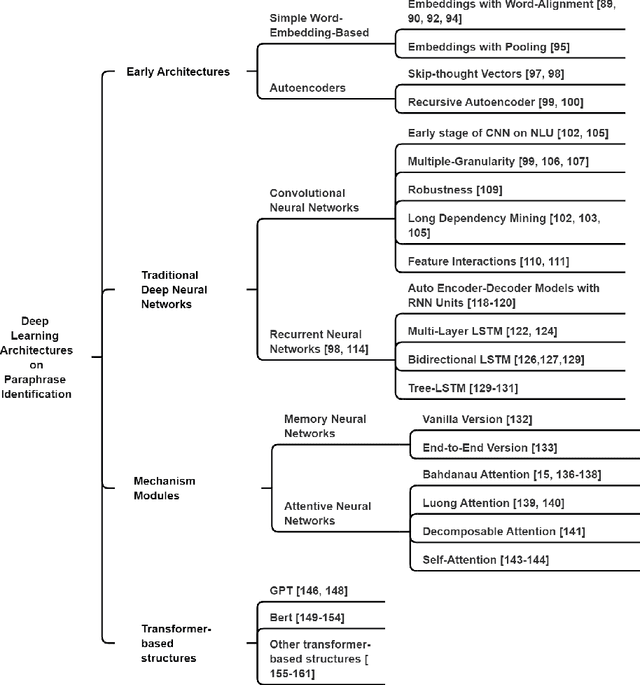
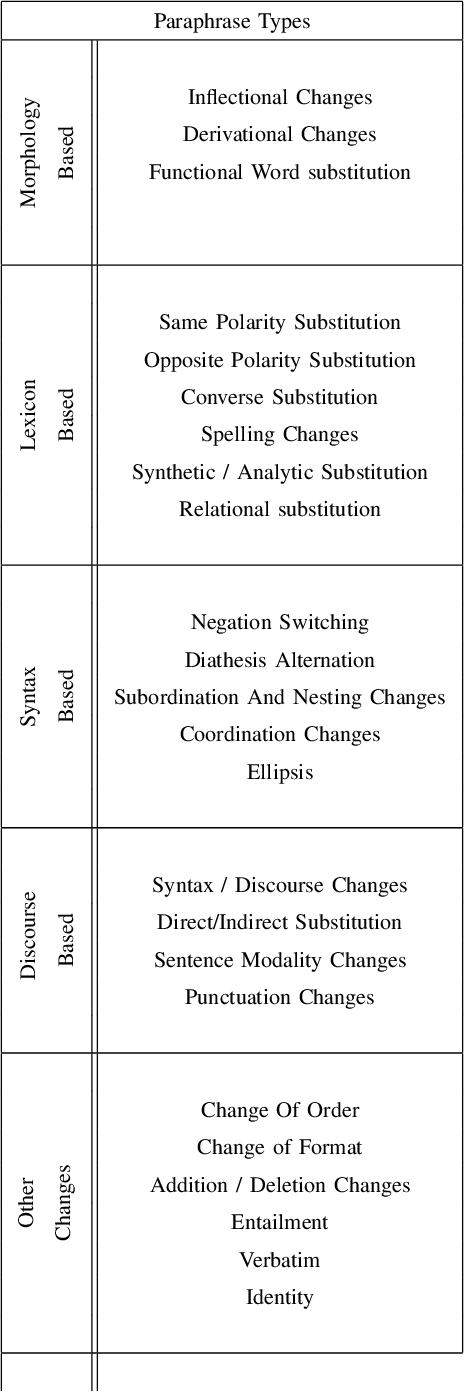
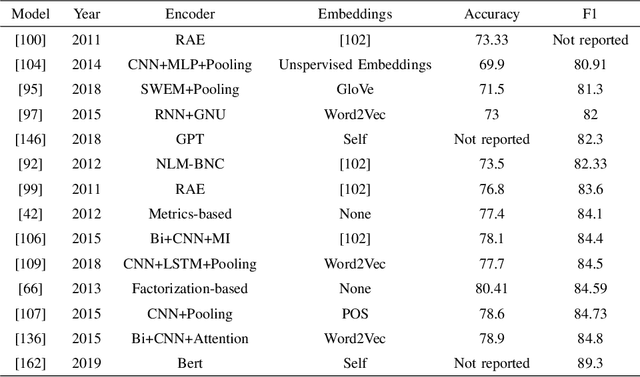
The rapid advancement of AI technology has made text generation tools like GPT-3 and ChatGPT increasingly accessible, scalable, and effective. This can pose serious threat to the credibility of various forms of media if these technologies are used for plagiarism, including scientific literature and news sources. Despite the development of automated methods for paraphrase identification, detecting this type of plagiarism remains a challenge due to the disparate nature of the datasets on which these methods are trained. In this study, we review traditional and current approaches to paraphrase identification and propose a refined typology of paraphrases. We also investigate how this typology is represented in popular datasets and how under-representation of certain types of paraphrases impacts detection capabilities. Finally, we outline new directions for future research and datasets in the pursuit of more effective paraphrase detection using AI.
An even-load-distribution design for composite bolted joints using a novel circuit model and artificial neural networks
May 15, 2021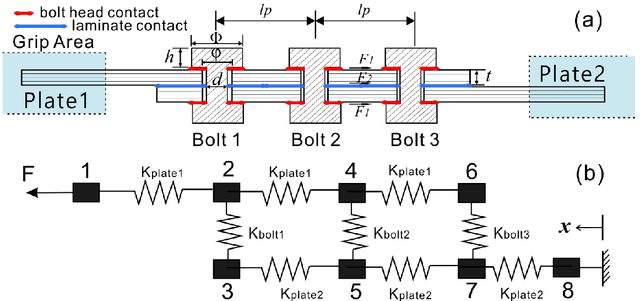
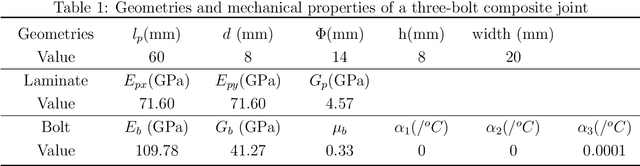
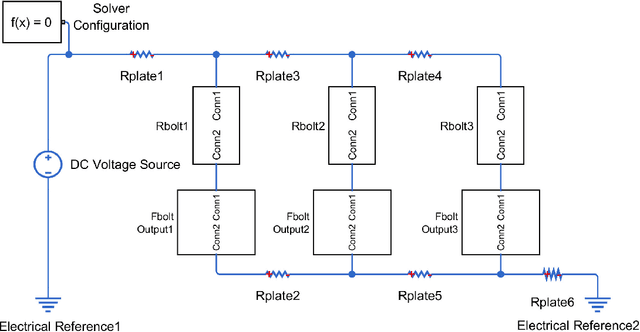
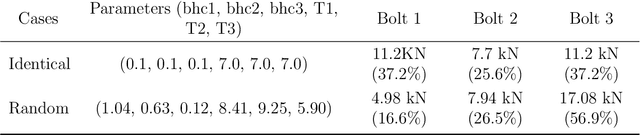
Due to the brittle feature of carbon fiber reinforced plastic laminates, mechanical multi-joint within these composite components show uneven load distribution for each bolt, which weaken the strength advantage of composite laminates. In order to reduce this defect and achieve the goal of even load distribution in mechanical joints, we propose a machine learning-based framework as an optimization method. Since that the friction effect has been proven to be a significant factor in determining bolt load distribution, our framework aims at providing optimal parameters including bolt-hole clearances and tightening torques for a minimum unevenness of bolt load. A novel circuit model is established to generate data samples for the training of artificial networks at a relatively low computational cost. A database for all the possible inputs in the design space is built through the machine learning model. The optimal dataset of clearances and torques provided by the database is validated by both the finite element method, circuit model, and an experimental measurement based on the linear superposition principle, which shows the effectiveness of this general framework for the optimization problem. Then, our machine learning model is further compared and worked in collaboration with commonly used optimization algorithms, which shows the potential of greatly increasing computational efficiency for the inverse design problem.