 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompression Robust Synthetic Speech Detection Using Patched Spectrogram Transformer
Feb 22, 2024



Many deep learning synthetic speech generation tools are readily available. The use of synthetic speech has caused financial fraud, impersonation of people, and misinformation to spread. For this reason forensic methods that can detect synthetic speech have been proposed. Existing methods often overfit on one dataset and their performance reduces substantially in practical scenarios such as detecting synthetic speech shared on social platforms. In this paper we propose, Patched Spectrogram Synthetic Speech Detection Transformer (PS3DT), a synthetic speech detector that converts a time domain speech signal to a mel-spectrogram and processes it in patches using a transformer neural network. We evaluate the detection performance of PS3DT on ASVspoof2019 dataset. Our experiments show that PS3DT performs well on ASVspoof2019 dataset compared to other approaches using spectrogram for synthetic speech detection. We also investigate generalization performance of PS3DT on In-the-Wild dataset. PS3DT generalizes well than several existing methods on detecting synthetic speech from an out-of-distribution dataset. We also evaluate robustness of PS3DT to detect telephone quality synthetic speech and synthetic speech shared on social platforms (compressed speech). PS3DT is robust to compression and can detect telephone quality synthetic speech better than several existing methods.
DSVAE: Interpretable Disentangled Representation for Synthetic Speech Detection
Apr 06, 2023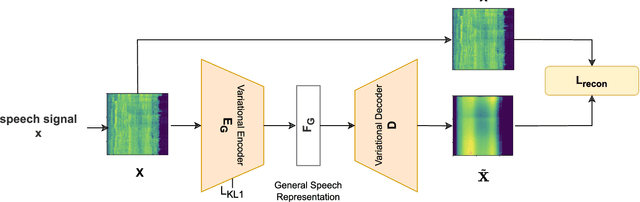
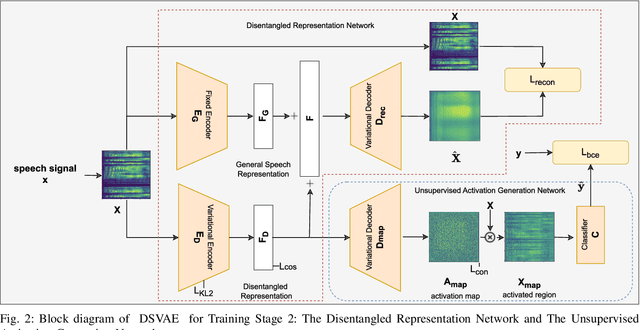
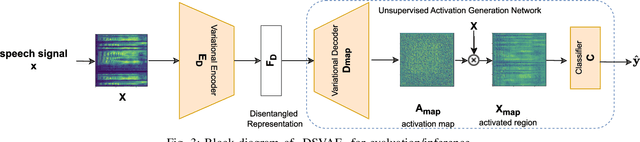
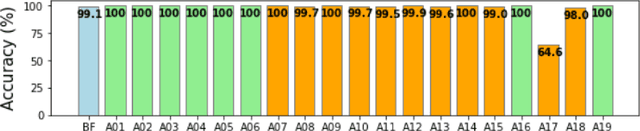
Tools to generate high quality synthetic speech signal that is perceptually indistinguishable from speech recorded from human speakers are easily available. Several approaches have been proposed for detecting synthetic speech. Many of these approaches use deep learning methods as a black box without providing reasoning for the decisions they make. This limits the interpretability of these approaches. In this paper, we propose Disentangled Spectrogram Variational Auto Encoder (DSVAE) which is a two staged trained variational autoencoder that processes spectrograms of speech using disentangled representation learning to generate interpretable representations of a speech signal for detecting synthetic speech. DSVAE also creates an activation map to highlight the spectrogram regions that discriminate synthetic and bona fide human speech signals. We evaluated the representations obtained from DSVAE using the ASVspoof2019 dataset. Our experimental results show high accuracy (>98%) on detecting synthetic speech from 6 known and 10 out of 11 unknown speech synthesizers. We also visualize the representation obtained from DSVAE for 17 different speech synthesizers and verify that they are indeed interpretable and discriminate bona fide and synthetic speech from each of the synthesizers.
An Overview of Recent Work in Media Forensics: Methods and Threats
Apr 26, 2022


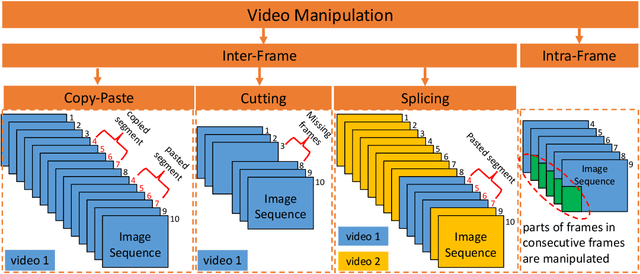
In this paper, we review recent work in media forensics for digital images, video, audio (specifically speech), and documents. For each data modality, we discuss synthesis and manipulation techniques that can be used to create and modify digital media. We then review technological advancements for detecting and quantifying such manipulations. Finally, we consider open issues and suggest directions for future research.
Forensic Analysis and Localization of Multiply Compressed MP3 Audio Using Transformers
Mar 30, 2022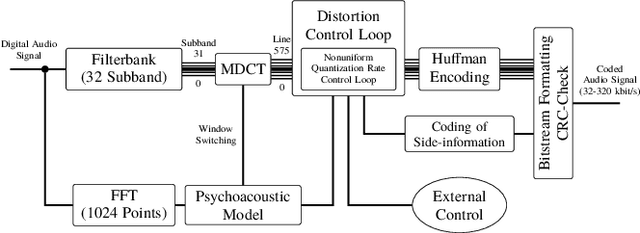
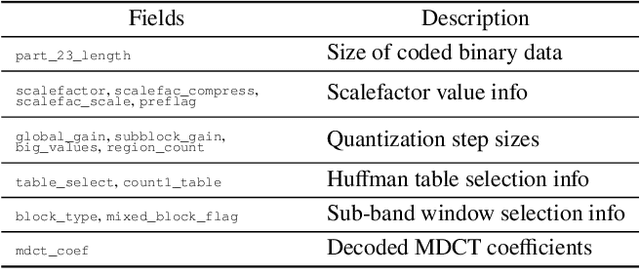


Audio signals are often stored and transmitted in compressed formats. Among the many available audio compression schemes, MPEG-1 Audio Layer III (MP3) is very popular and widely used. Since MP3 is lossy it leaves characteristic traces in the compressed audio which can be used forensically to expose the past history of an audio file. In this paper, we consider the scenario of audio signal manipulation done by temporal splicing of compressed and uncompressed audio signals. We propose a method to find the temporal location of the splices based on transformer networks. Our method identifies which temporal portions of a audio signal have undergone single or multiple compression at the temporal frame level, which is the smallest temporal unit of MP3 compression. We tested our method on a dataset of 486,743 MP3 audio clips. Our method achieved higher performance and demonstrated robustness with respect to different MP3 data when compared with existing methods.
Forensic Analysis of Video Files Using Metadata
May 13, 2021

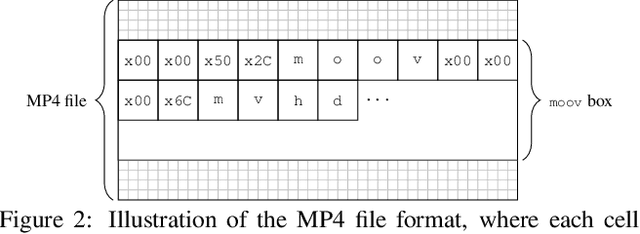
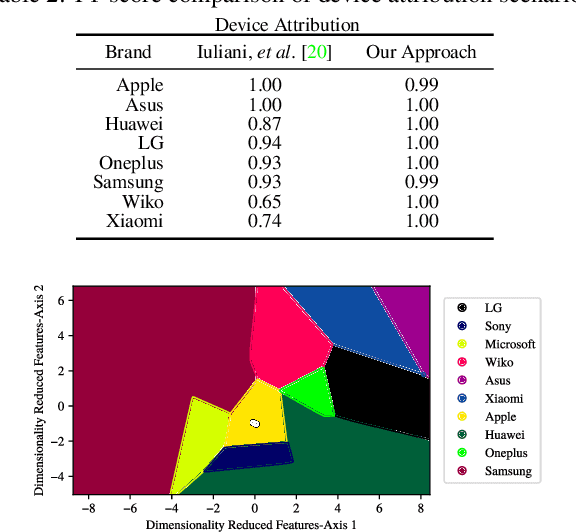
The unprecedented ease and ability to manipulate video content has led to a rapid spread of manipulated media. The availability of video editing tools greatly increased in recent years, allowing one to easily generate photo-realistic alterations. Such manipulations can leave traces in the metadata embedded in video files. This metadata information can be used to determine video manipulations, brand of video recording device, the type of video editing tool, and other important evidence. In this paper, we focus on the metadata contained in the popular MP4 video wrapper/container. We describe our method for metadata extractor that uses the MP4's tree structure. Our approach for analyzing the video metadata produces a more compact representation. We will describe how we construct features from the metadata and then use dimensionality reduction and nearest neighbor classification for forensic analysis of a video file. Our approach allows one to visually inspect the distribution of metadata features and make decisions. The experimental results confirm that the performance of our approach surpasses other methods.
Scientific Image Tampering Detection Based On Noise Inconsistencies: A Method And Datasets
Mar 04, 2020



Scientific image tampering is a problem that affects not only authors but also the general perception of the research community. Although previous researchers have developed methods to identify tampering in natural images, these methods may not thrive under the scientific setting as scientific images have different statistics, format, quality, and intentions. Therefore, we propose a scientific-image specific tampering detection method based on noise inconsistencies, which is capable of learning and generalizing to different fields of science. We train and test our method on a new dataset of manipulated western blot and microscopy imagery, which aims at emulating problematic images in science. The test results show that our method can detect various types of image manipulation in different scenarios robustly, and it outperforms existing general-purpose image tampering detection schemes. We discuss applications beyond these two types of images and suggest next steps for making detection of problematic images a systematic step in peer review and science in general.
Estimating a Null Model of Scientific Image Reuse to Support Research Integrity Investigations
Feb 22, 2020



When there is a suspicious figure reuse case in science, research integrity investigators often find it difficult to rebut authors claiming that "it happened by chance". In other words, when there is a "collision" of image features, it is difficult to justify whether it appears rarely or not. In this article, we provide a method to predict the rarity of an image feature by statistically estimating the chance of it randomly occurring across all scientific imagery. Our method is based on high-dimensional density estimation of ORB features using 7+ million images in the PubMed Open Access Subset dataset. We show that this method can lead to meaningful feedback during research integrity investigations by providing a null hypothesis for scientific image reuse and thus a p-value during deliberations. We apply the model to a sample of increasingly complex imagery and confirm that it produces decreasingly smaller p-values as expected. We discuss applications to research integrity investigations as well as future work.