 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-Based Speech Synthesizer Attribution in an Open Set Scenario
Oct 14, 2022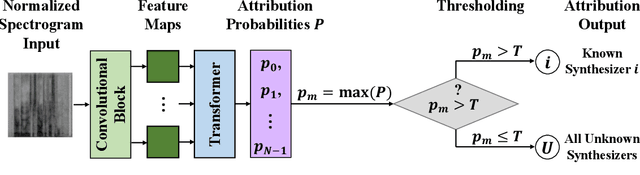
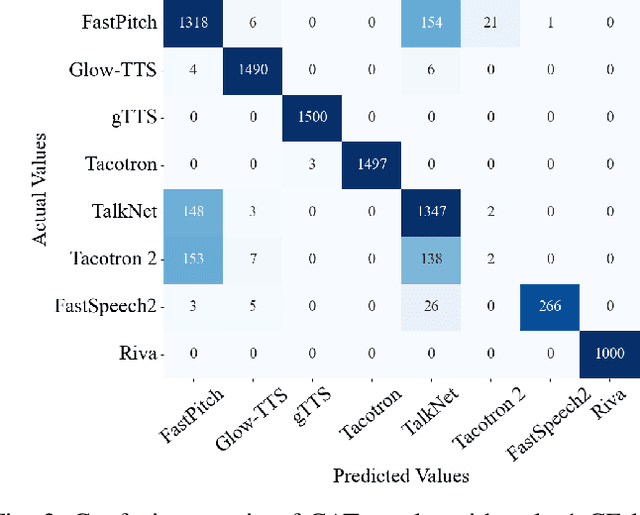
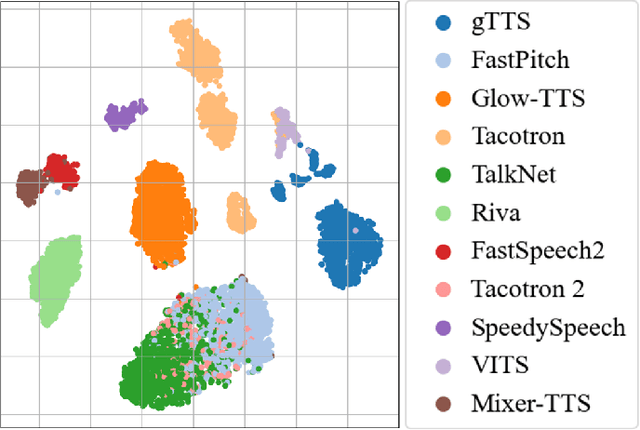
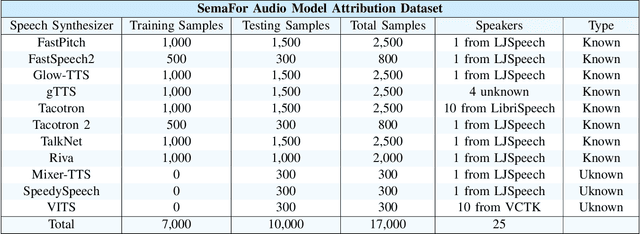
Speech synthesis methods can create realistic-sounding speech, which may be used for fraud, spoofing, and misinformation campaigns. Forensic methods that detect synthesized speech are important for protection against such attacks. Forensic attribution methods provide even more information about the nature of synthesized speech signals because they identify the specific speech synthesis method (i.e., speech synthesizer) used to create a speech signal. Due to the increasing number of realistic-sounding speech synthesizers, we propose a speech attribution method that generalizes to new synthesizers not seen during training. To do so, we investigate speech synthesizer attribution in both a closed set scenario and an open set scenario. In other words, we consider some speech synthesizers to be "known" synthesizers (i.e., part of the closed set) and others to be "unknown" synthesizers (i.e., part of the open set). We represent speech signals as spectrograms and train our proposed method, known as compact attribution transformer (CAT), on the closed set for multi-class classification. Then, we extend our analysis to the open set to attribute synthesized speech signals to both known and unknown synthesizers. We utilize a t-distributed stochastic neighbor embedding (tSNE) on the latent space of the trained CAT to differentiate between each unknown synthesizer. Additionally, we explore poly-1 loss formulations to improve attribution results. Our proposed approach successfully attributes synthesized speech signals to their respective speech synthesizers in both closed and open set scenarios.
* Accepted to the 2022 IEEE International Conference on Machine Learning and Applications
Frequency Domain-Based Detection of Generated Audio
May 03, 2022


Attackers may manipulate audio with the intent of presenting falsified reports, changing an opinion of a public figure, and winning influence and power. The prevalence of inauthentic multimedia continues to rise, so it is imperative to develop a set of tools that determines the legitimacy of media. We present a method that analyzes audio signals to determine whether they contain real human voices or fake human voices (i.e., voices generated by neural acoustic and waveform models). Instead of analyzing the audio signals directly, the proposed approach converts the audio signals into spectrogram images displaying frequency, intensity, and temporal content and evaluates them with a Convolutional Neural Network (CNN). Trained on both genuine human voice signals and synthesized voice signals, we show our approach achieves high accuracy on this classification task.
* Accepted to the 2021 Media Watermarking, Security, and Forensics Conference, IS&T Electronic Imaging Symposium (EI)
Splicing Detection and Localization In Satellite Imagery Using Conditional GANs
May 03, 2022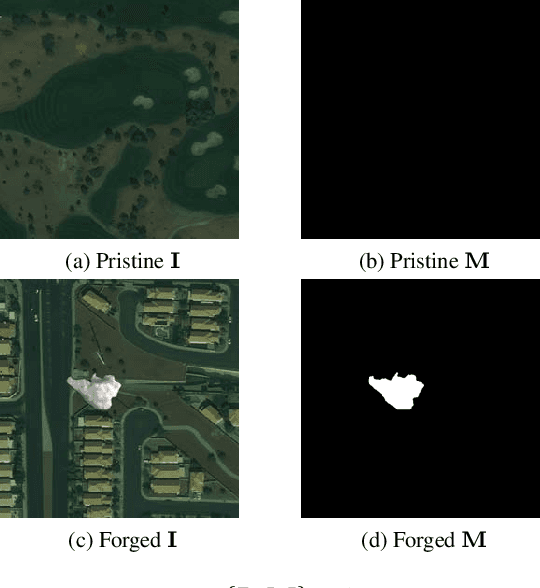


The widespread availability of image editing tools and improvements in image processing techniques allow image manipulation to be very easy. Oftentimes, easy-to-use yet sophisticated image manipulation tools yields distortions/changes imperceptible to the human observer. Distribution of forged images can have drastic ramifications, especially when coupled with the speed and vastness of the Internet. Therefore, verifying image integrity poses an immense and important challenge to the digital forensic community. Satellite images specifically can be modified in a number of ways, including the insertion of objects to hide existing scenes and structures. In this paper, we describe the use of a Conditional Generative Adversarial Network (cGAN) to identify the presence of such spliced forgeries within satellite images. Additionally, we identify their locations and shapes. Trained on pristine and falsified images, our method achieves high success on these detection and localization objectives.
* Accepted to the 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR)
Synthesized Speech Detection Using Convolutional Transformer-Based Spectrogram Analysis
May 03, 2022

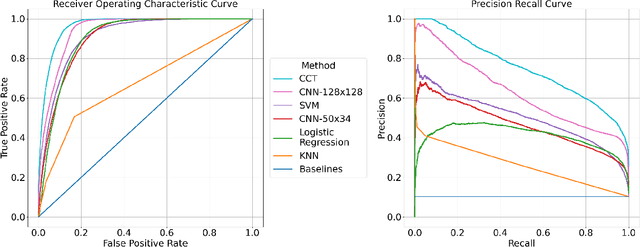
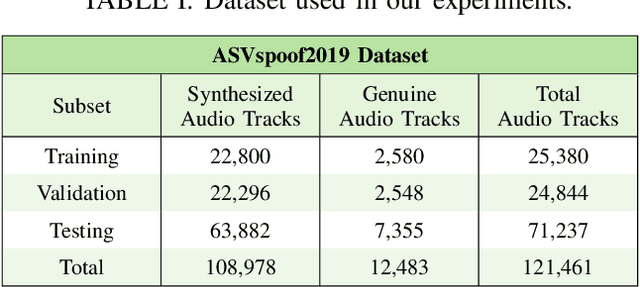
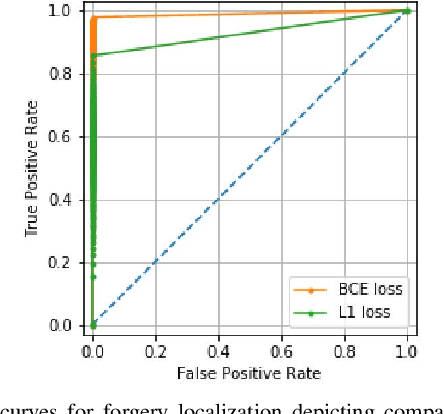
Synthesized speech is common today due to the prevalence of virtual assistants, easy-to-use tools for generating and modifying speech signals, and remote work practices. Synthesized speech can also be used for nefarious purposes, including creating a purported speech signal and attributing it to someone who did not speak the content of the signal. We need methods to detect if a speech signal is synthesized. In this paper, we analyze speech signals in the form of spectrograms with a Compact Convolutional Transformer (CCT) for synthesized speech detection. A CCT utilizes a convolutional layer that introduces inductive biases and shared weights into a network, allowing a transformer architecture to perform well with fewer data samples used for training. The CCT uses an attention mechanism to incorporate information from all parts of a signal under analysis. Trained on both genuine human voice signals and synthesized human voice signals, we demonstrate that our CCT approach successfully differentiates between genuine and synthesized speech signals.
* Accepted to the 2021 IEEE Asilomar Conference on Signals, Systems, and Computers
An Overview of Recent Work in Media Forensics: Methods and Threats
Apr 26, 2022


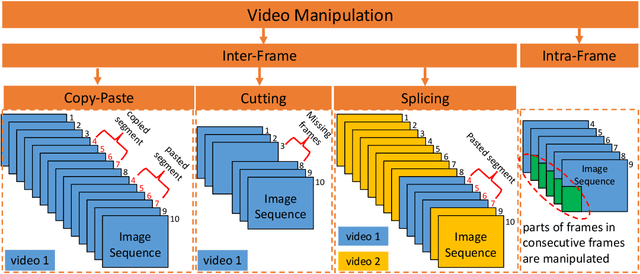
In this paper, we review recent work in media forensics for digital images, video, audio (specifically speech), and documents. For each data modality, we discuss synthesis and manipulation techniques that can be used to create and modify digital media. We then review technological advancements for detecting and quantifying such manipulations. Finally, we consider open issues and suggest directions for future research.
An Attention-Based System for Damage Assessment Using Satellite Imagery
Apr 14, 2020


When disaster strikes, accurate situational information and a fast, effective response are critical to save lives. Widely available, high resolution satellite images enable emergency responders to estimate locations, causes, and severity of damage. Quickly and accurately analyzing the extensive amount of satellite imagery available, though, requires an automatic approach. In this paper, we present Siam-U-Net-Attn model - a multi-class deep learning model with an attention mechanism - to assess damage levels of buildings given a pair of satellite images depicting a scene before and after a disaster. We evaluate the proposed method on xView2, a large-scale building damage assessment dataset, and demonstrate that the proposed approach achieves accurate damage scale classification and building segmentation results simultaneously.