 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer-Based Speech Synthesizer Attribution in an Open Set Scenario
Paper and Code
Oct 14, 2022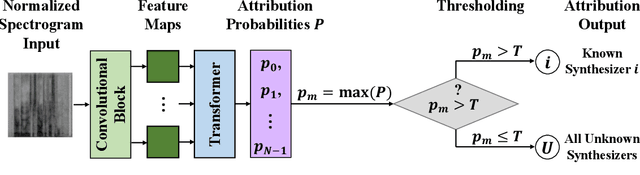
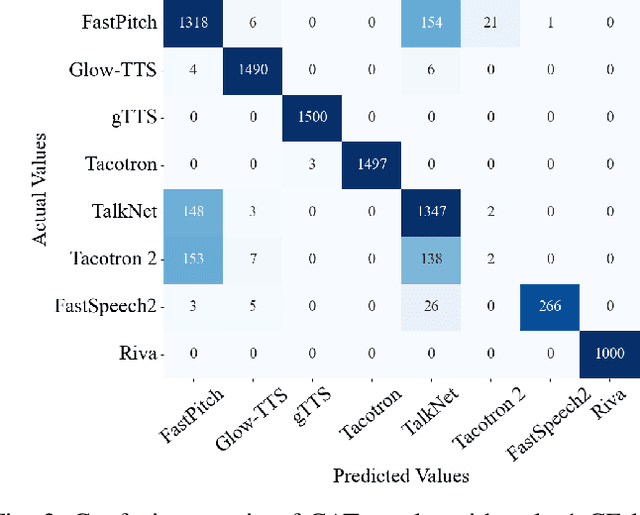
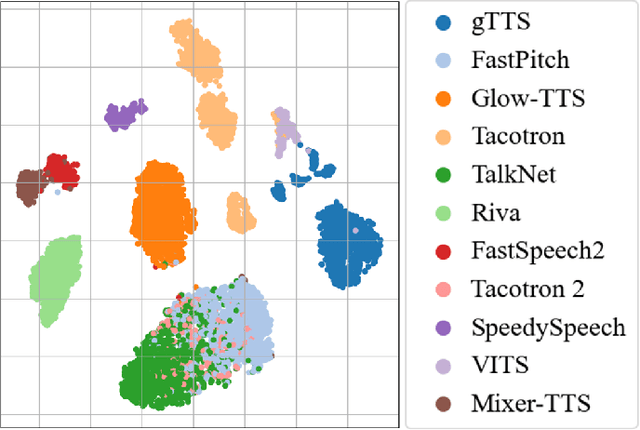
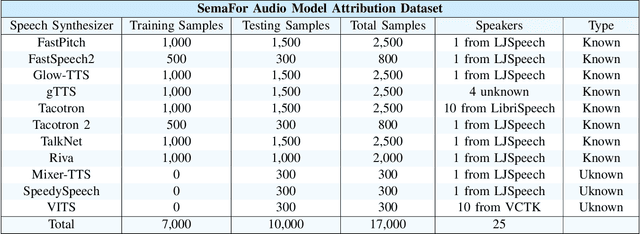
Speech synthesis methods can create realistic-sounding speech, which may be used for fraud, spoofing, and misinformation campaigns. Forensic methods that detect synthesized speech are important for protection against such attacks. Forensic attribution methods provide even more information about the nature of synthesized speech signals because they identify the specific speech synthesis method (i.e., speech synthesizer) used to create a speech signal. Due to the increasing number of realistic-sounding speech synthesizers, we propose a speech attribution method that generalizes to new synthesizers not seen during training. To do so, we investigate speech synthesizer attribution in both a closed set scenario and an open set scenario. In other words, we consider some speech synthesizers to be "known" synthesizers (i.e., part of the closed set) and others to be "unknown" synthesizers (i.e., part of the open set). We represent speech signals as spectrograms and train our proposed method, known as compact attribution transformer (CAT), on the closed set for multi-class classification. Then, we extend our analysis to the open set to attribute synthesized speech signals to both known and unknown synthesizers. We utilize a t-distributed stochastic neighbor embedding (tSNE) on the latent space of the trained CAT to differentiate between each unknown synthesizer. Additionally, we explore poly-1 loss formulations to improve attribution results. Our proposed approach successfully attributes synthesized speech signals to their respective speech synthesizers in both closed and open set scenarios.