 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternalInspector $I^2$: Robust Confidence Estimation in LLMs through Internal States
Paper and Code
Jun 17, 2024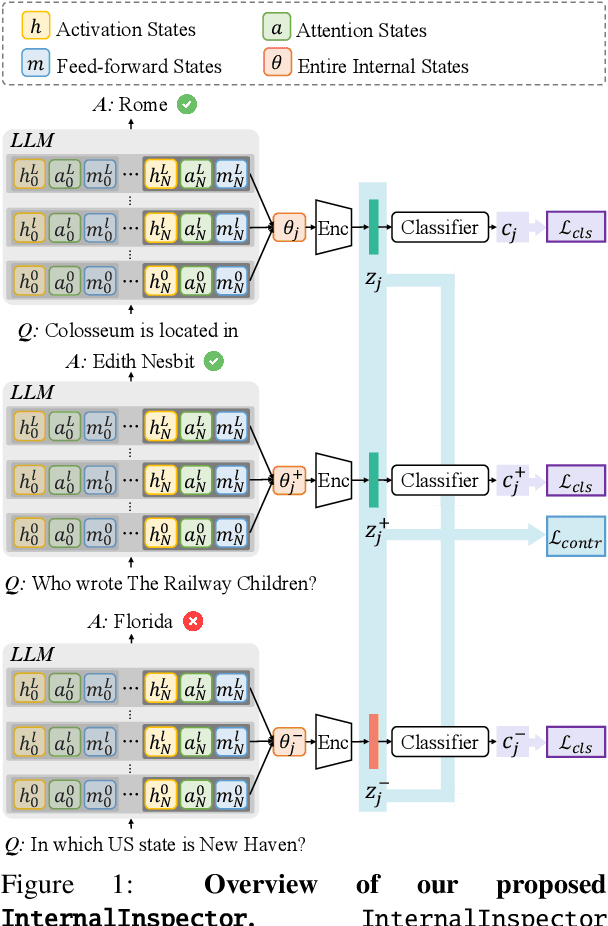
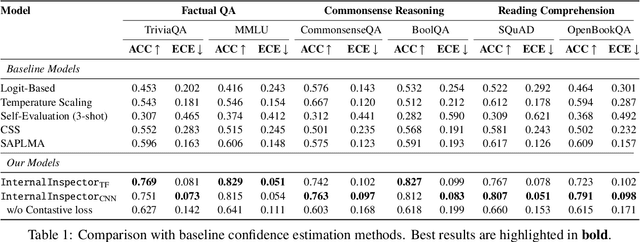
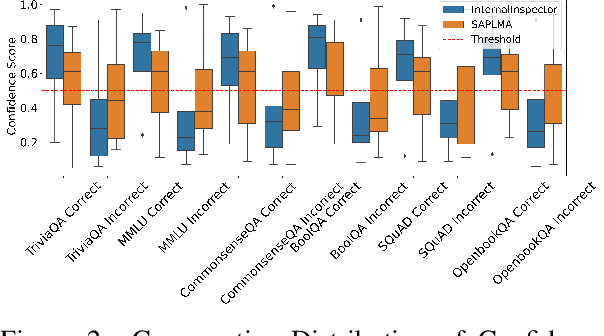
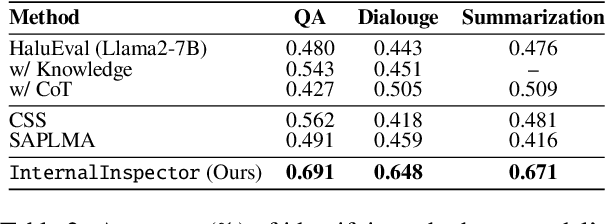
Despite their vast capabilities, Large Language Models (LLMs) often struggle with generating reliable outputs, frequently producing high-confidence inaccuracies known as hallucinations. Addressing this challenge, our research introduces InternalInspector, a novel framework designed to enhance confidence estimation in LLMs by leveraging contrastive learning on internal states including attention states, feed-forward states, and activation states of all layers. Unlike existing methods that primarily focus on the final activation state, InternalInspector conducts a comprehensive analysis across all internal states of every layer to accurately identify both correct and incorrect prediction processes. By benchmarking InternalInspector against existing confidence estimation methods across various natural language understanding and generation tasks, including factual question answering, commonsense reasoning, and reading comprehension, InternalInspector achieves significantly higher accuracy in aligning the estimated confidence scores with the correctness of the LLM's predictions and lower calibration error. Furthermore, InternalInspector excels at HaluEval, a hallucination detection benchmark, outperforming other internal-based confidence estimation methods in this task.